EnsembleLink:学習データなしでの正確なレコードリンケージ
異なるデータセット間で同一の主体を特定するレコードリンケージにおいて、教師データを一切必要とせずに高い精度を達成する新手法「EnsembleLink」が提案されました。この手法は大規模なテキストコーパスで事前学習された言語モデルが持つ意味的な関係性の理解力を活用しており、都市名や人名、組織名、多言語の政党名といった多様なベンチマークにおいて、大量のラベルを必要とする既存の教師あり学習手法と同等、あるいはそれ以上の性能を記録しています。ローカル環境のオープンソースモデルのみで動作するため外部APIへの依存がなく、一般的な消費者向けハードウェアでも数分で処理を完了できる実用性を備えており、これまでアドホックな規則に頼っていたデータ統合プロセスの精度と信頼性を大幅に向上させることが期待されます。
TL;DR(結論)
異なるデータセット間で同一の主体を特定するレコードリンケージにおいて、教師データを一切必要とせずに高い精度を達成する新手法「EnsembleLink」が提案されました。この手法は大規模なテキストコーパスで事前学習された言語モデルが持つ意味的な関係性の理解力を活用しており、都市名や人名、組織名、多言語の政党名といった多様なベンチマークにおいて、大量のラベルを必要とする既存の教師あり学習手法と同等、あるいはそれ以上の性能を記録しています。ローカル環境のオープンソースモデルのみで動作するため外部APIへの依存がなく、一般的な消費者向けハードウェアでも数分で処理を完了できる実用性を備えており、これまでアドホックな規則に頼っていたデータ統合プロセスの精度と信頼性を大幅に向上させることが期待されます。
なぜこの問題か
社会科学の分野において、異なるデータセットを共通の識別子がない状態で統合するレコードリンケージは、分析の基礎となる極めて重要な工程です。例えば、調査回答と行政記録の照合、選挙サイクルをまたいだ献金者の特定、あるいは国勢調査間での個人の接続など、実証研究の多くはこのプロセスに依存しています。しかし、その重要性にもかかわらず、レコードリンケージは手法として未発達な状態にあり、多くの研究者はこれを単なる「配管作業」のような前処理ステップとして扱ってきました。現状では、場当たり的なルールに基づいたマッチングが行われることが多く、そこで生じるエラーが後の分析結果にどのような不確実性をもたらすかが定量的に評価されていません。 このような状況は、数十年前に欠損値処理が統計的に定式化される前の状態に似ています。かつて欠損値は単なる削除や単純な補完で処理されていましたが、現在では原則に基づいた手法が必要であると認識されています。レコードリンケージも同様の扱いを受けるべきです。研究者が曖昧な照合を用いてデータセットを統合する際、どの記録が同一のエンティティに対応するかという決定は、その後の分析結果を左右する重大な判断です。…
核心:何を提案したのか
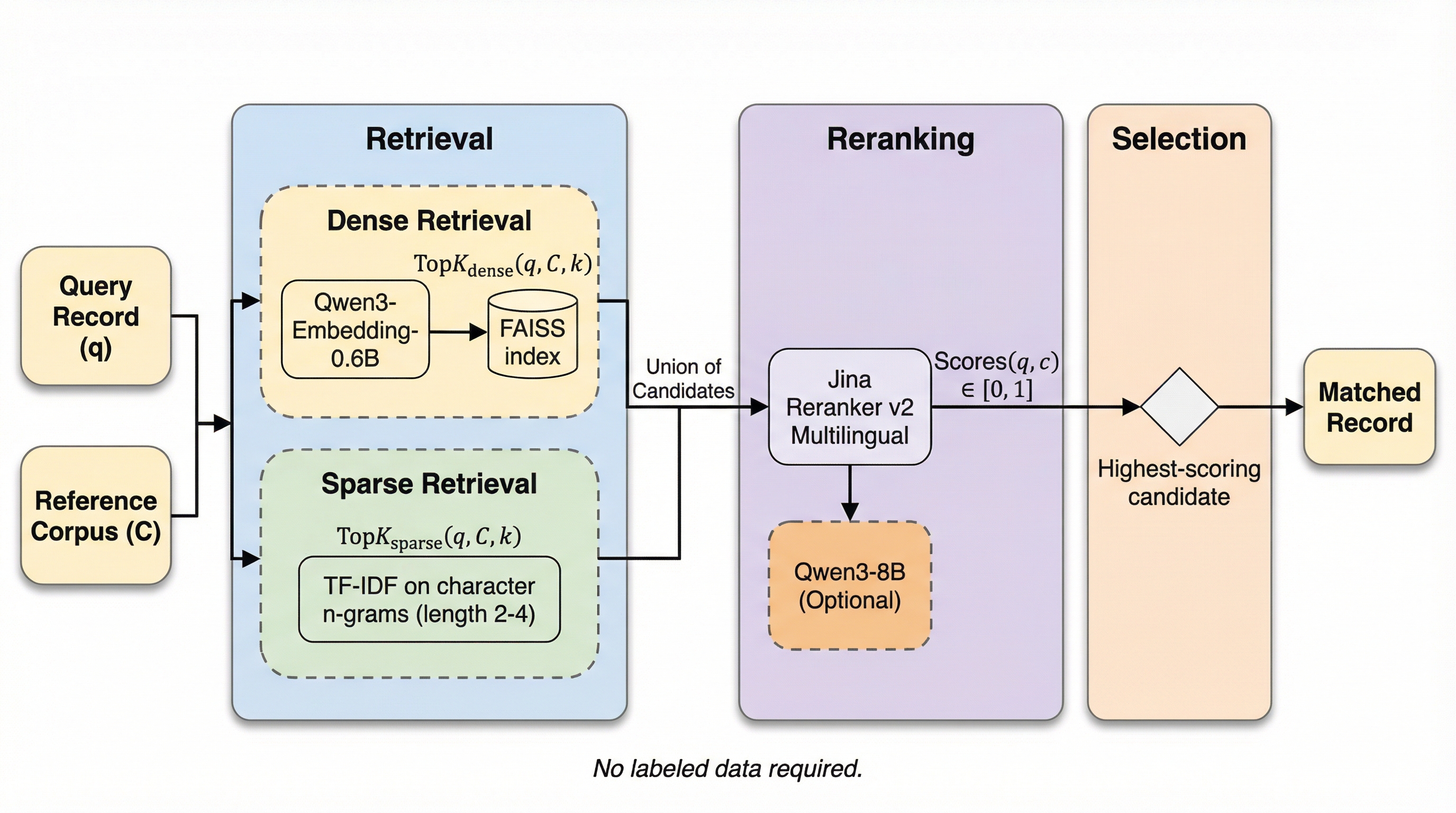
本研究では、学習データを一切使用せずに高精度なレコードリンケージを実現する手法「EnsembleLink」を提案しています。この手法の核心的なアイデアは、近年の自然言語処理技術の進歩によって誕生した大規模言語モデルが、タスク固有の学習なしで「ゼロショット」でレコードを照合できるほど深い意味的理解を備えているという点にあります。モデルは、膨大なテキストコーパスからの学習を通じて、単なる文字列の一致を超えた知識を獲得しています。例えば、「NYC」と「New York City」が同じ場所を指すことや、「Dick」が「Richard」の愛称であることを、モデルは既に把握しています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related