EnsembleLink:学習データなしでの正確なレコードリンケージ
レコードリンケージは、異なるデータセット間で同一のエンティティを指すレコードを照合するプロセスであり、社会科学において不可欠ですが、現在は場当たり的なルールが適用されるなど手法として未発達な側面があります。
TL;DR(結論)
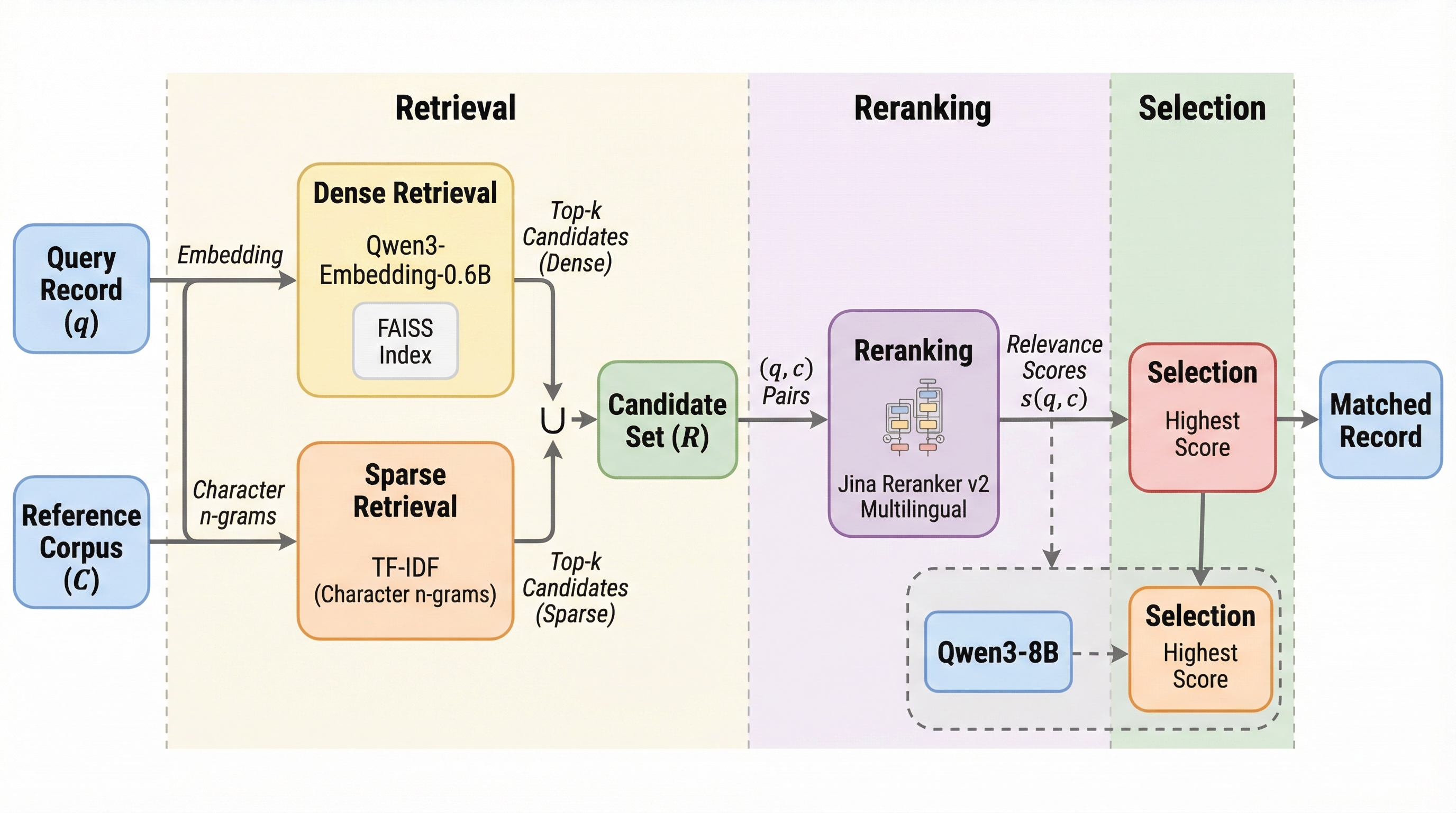
レコードリンケージは、異なるデータセット間で同一のエンティティを指すレコードを照合するプロセスであり、社会科学において不可欠ですが、現在は場当たり的なルールが適用されるなど手法として未発達な側面があります。既存の手法は精度が低いか、あるいは膨大なラベル付きの学習データを必要とするという課題を抱えていましたが、本論文が提案する「EnsembleLink」は、大規模なテキストコーパスから意味的関係を学習済みの事前学習済み言語モデルを活用することで、教師データを一切使わずに高い照合精度を実現します。 この手法は、高密度埋め込みと文字n-gramを用いたアンサンブルによる候補の「検索」、クロスエンコーダによる「再ランク付け」、そして最適な候補の「選択」という3段階のパイプラインで構成されています。事前学習済みモデルが持つ「NYC」と「New York City」が同じ場所であるといった意味的理解や、ニックネームと本名の関係、略語の展開といった知識を利用することで、タスク固有の訓練なしで複雑な照合を可能にしています。 検証では、都市名、人名、組織名、多言語の政党名、書誌記録などのベンチマークにおいて、EnsembleLinkは大量のラベルを必要とする教師あり学習手法と同等、あるいはそれ以上の精度を達成しました。また、外部APIを介さずオープンソースモデルを用いてローカル環境で実行できるため、プライバシーを保護しつつ、一般的な照合タスクを数分で完了できる実用性を備えています。
なぜこの問題か
レコードリンケージは、研究者が共通の識別子を持たない複数のデータセットを、共有されているが「ノイズの多い」インデックス列に基づいて結合するプロセスであり、実証的な社会科学の基盤となっています。例えば、調査の回答を行政記録と照合したり、選挙サイクルをまたいで選挙資金の寄付者を一致させたり、国勢調査を通じて個人を追跡したりといった作業が日常的に行われています。しかし、その遍在性にもかかわらず、レコードリンケージは手法として未発達なままであり、多くの場合、本格的な分析が始まる前の単なる「下準備」として扱われてきました。 現状では、多くの研究者が場当たり的なルールを用いてファジーマッチングを行っていますが、その過程で生じる照合エラーが下流の分析にどのような不確実性をもたらすかについては、ほとんど定量化されていません。これは、数十年前に欠損データが単なる削除や単純な補完で処理されていた状況に似ています。欠損データが現在では原則に基づいた手法を必要とする問題として認識されているように、レコードリンケージも同様の扱いを受けるべきです。誤った照合や照合漏れは、推定値にバイアスを与え、信頼性を過大に評価させる原因となります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related