単一の参照を超えて:手話翻訳における言い換えを用いた学習と評価
現在の手話翻訳データセットは、一つの手話表現に対して一つの書き言葉の翻訳しか紐付けられていないことが多く、手話と書き言葉の非同型な関係性を十分に捉えきれていないという課題がある。 本研究では、大規模言語モデル(LLM)を活用して翻訳文の言い換え(パラフレーズ)を自動生成し、これを合成的な代替参照文として用いることで、手話翻訳モデルの学習と評価の両面に与える影響を詳細に調査した。 検証の結果、言い換えを単純に学習に組み込むだけでは性能向上に繋がらない一方で、評価指標に複数の言い換えを取り入れた「BLEUpara」は、標準的な指標よりも人間の主観評価と強く相関することが明らかになった。
TL;DR(結論)
現在の手話翻訳データセットは、一つの手話表現に対して一つの書き言葉の翻訳しか紐付けられていないことが多く、手話と書き言葉の非同型な関係性を十分に捉えきれていないという課題がある。 本研究では、大規模言語モデル(LLM)を活用して翻訳文の言い換え(パラフレーズ)を自動生成し、これを合成的な代替参照文として用いることで、手話翻訳モデルの学習と評価の両面に与える影響を詳細に調査した。 検証の結果、言い換えを単純に学習に組み込むだけでは性能向上に繋がらない一方で、評価指標に複数の言い換えを取り入れた「BLEUpara」は、標準的な指標よりも人間の主観評価と強く相関することが明らかになった。
なぜこの問題か
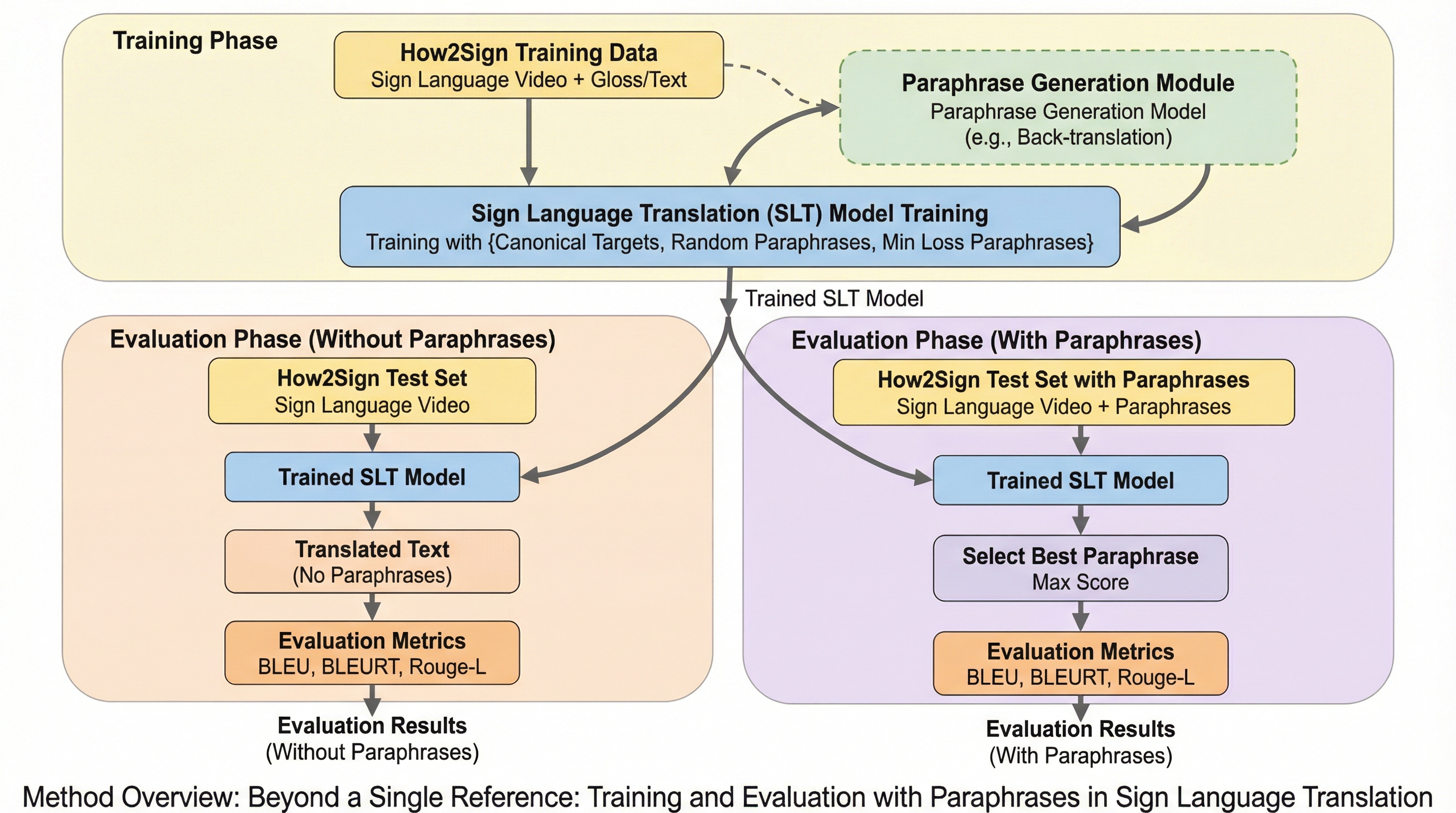
自動手話翻訳(SLT)の分野は、ビジョン言語モデルの進歩や大規模なビデオ・テキストコーパスの登場により急速な発展を遂げている。しかし、既存の手話翻訳データセットには「翻訳の多様性の欠如」という根強い制限が存在する。具体的には、一つの手話の発話に対して、弱く整列された単一の書き言葉の参照訳しかペアになっていないことが一般的である。これは、複数の参照訳が提供されたり、翻訳の選択肢が明示的に注釈されたりする音声言語の機械翻訳とは対照的な状況である。人間が話す言語には、語彙の選択、レジスター(言語使用域)、情報の構造化において自然な多様性が存在するが、現在の手話翻訳データセットはそれを捉えきれていない。 このような多様性の欠如は、モデルの学習と評価の両方において重大な制約となる。特に、BLEUのようなn-gramの一致に基づく評価指標は、参照訳の有無や内容に非常に敏感であることが知られている。手話は視覚的な表現と書き言葉の間に非同型な関係を持っており、一つの手話の文章に対して、語順、明示性の度合い、構文構造が異なる複数の有効な翻訳が存在し得る。…
核心:何を提案したのか
本研究の核心は、大規模言語モデル(LLM)を用いて、手話翻訳コーパスの書き言葉部分を自動的に言い換え、合成的な代替参照文を生成することにある。このアプローチにより、手話翻訳における「正解」の幅を広げ、より柔軟な学習と評価を可能にすることを目指している。具体的には、二つの主要な目的が設定された。第一に、言い換えによって生成された翻訳バリエーションが、T5のようなシーケンス・ツー・シーケンス型の手話翻訳モデルの堅牢性を向上させることができるかを調査することである。第二に、これらの言い換えが自動評価指標にどのような影響を与えるかを検証し、人間の評価との整合性を確認することである。 提案手法の重要な要素として、言い換えの質を評価するための指標「ParaScore」の適応が挙げられる。質の高い言い換えとは、元の意味を正確に保持しつつ、語彙や構文において十分な多様性を持っている必要がある。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related