EnsembleLink: 学習データなしで高精度なレコードリンケージを実現
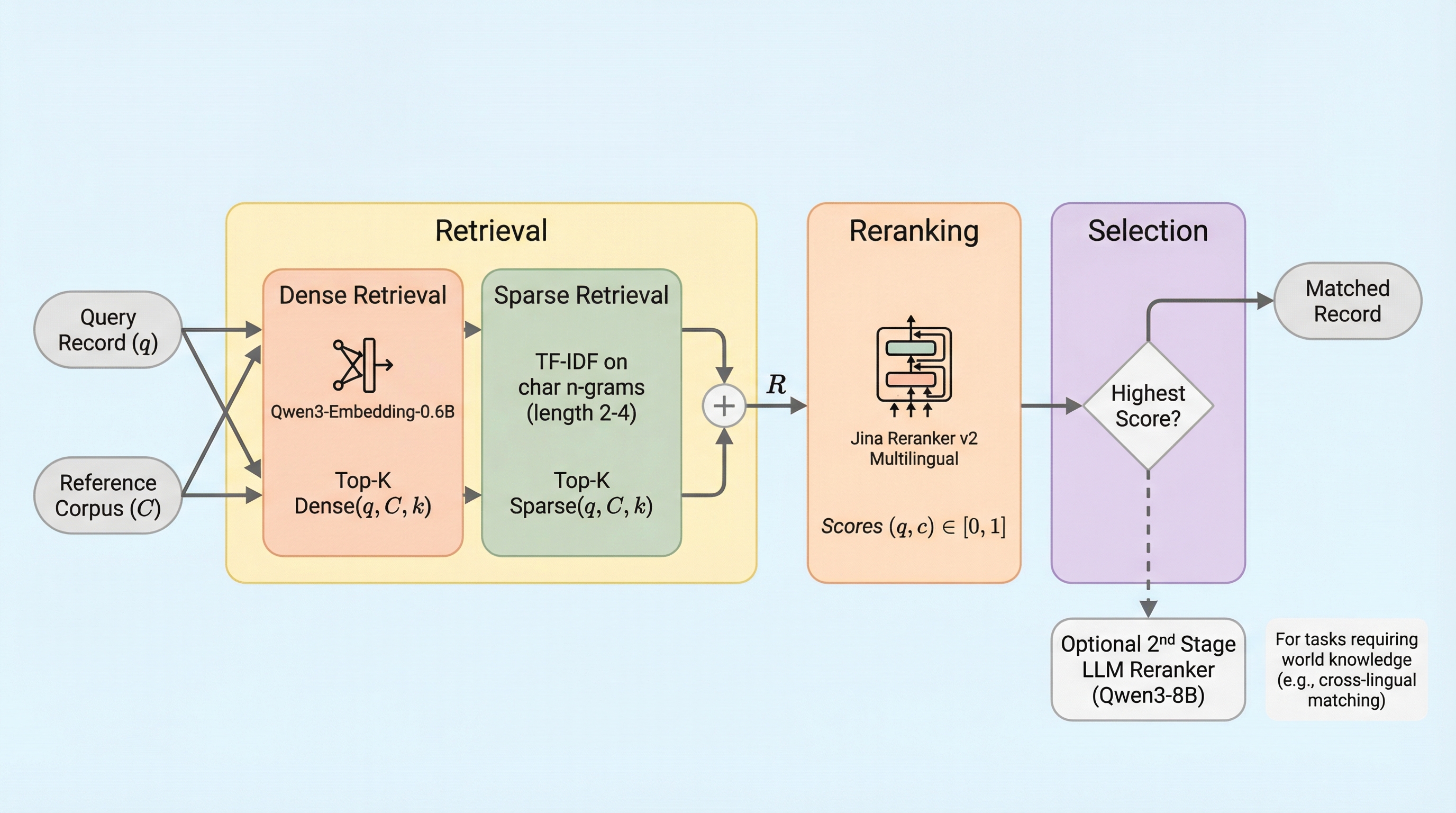
レコードリンケージは異なるデータセット間で同一の対象を照合する重要な工程だが、従来は場当たり的な規則や大量の学習データに依存しており、誤差の定量化も不十分であった。本論文が提案する「EnsembleLink」は、事前学習済み言語モデルのセマンティックな理解力を活用することで、学習データを一切使わずに、都市名や人名、組織名、多言語の政党名などの照合において教師あり学習手法と同等以上の高精度を達成した。 この手法は、密なベクトル検索と文字単位の疎な検索を組み合わせた候補抽出、およびクロスエンコーダによる高精度な再ランク付けという3段階のパイプラインで構成されており、オープンソースの軽量モデルを用いてローカル環境で実行できる。検証の結果、ニックネームや略称、非直訳の多言語対応など、従来のファジーマッチングでは困難だった複雑な照合を数分で完了させることが可能であり、社会科学などの実証研究におけるデータ統合の信頼性を大きく向上させる。 利用者は外部APIを呼び出すことなく、民生用ハードウェア上でプライバシーを保ちながら高速に処理を行うことができ、さらにモデルの重みが固定されているため結果の再現性も保証される。本手法は、都市名照合で90%、有権者照合で99%という極めて高い精度を記録しており、数千のラベルを必要とする既存の最先端手法に匹敵する性能をゼロショットで提供する画期的なツールである。
TL;DR(結論)
レコードリンケージは異なるデータセット間で同一の対象を照合する重要な工程だが、従来は場当たり的な規則や大量の学習データに依存しており、誤差の定量化も不十分であった。本論文が提案する「EnsembleLink」は、事前学習済み言語モデルのセマンティックな理解力を活用することで、学習データを一切使わずに、都市名や人名、組織名、多言語の政党名などの照合において教師あり学習手法と同等以上の高精度を達成した。 この手法は、密なベクトル検索と文字単位の疎な検索を組み合わせた候補抽出、およびクロスエンコーダによる高精度な再ランク付けという3段階のパイプラインで構成されており、オープンソースの軽量モデルを用いてローカル環境で実行できる。検証の結果、ニックネームや略称、非直訳の多言語対応など、従来のファジーマッチングでは困難だった複雑な照合を数分で完了させることが可能であり、社会科学などの実証研究におけるデータ統合の信頼性を大きく向上させる。 利用者は外部APIを呼び出すことなく、民生用ハードウェア上でプライバシーを保ちながら高速に処理を行うことができ、さらにモデルの重みが固定されているため結果の再現性も保証される。本手法は、都市名照合で90%、有権者照合で99%という極めて高い精度を記録しており、数千のラベルを必要とする既存の最先端手法に匹敵する性能をゼロショットで提供する画期的なツールである。
なぜこの問題か
実証的な社会科学において、異なるデータセットを共通の識別子がない状態で結合するレコードリンケージは、極めて基本的かつ不可欠な作業である。例えば、調査回答と行政記録の照合、選挙サイクルをまたぐ献金者の特定、国勢調査間での個人の追跡など、多くの研究がこの工程に依存している。しかし、その重要性にもかかわらず、レコードリンケージは方法論的に未発達な状態に置かれてきた。多くの研究者はこれを本格的な分析の前段階の「配管作業」のように扱い、場当たり的なルールで処理しているのが現状である。このような場当たり的な手法は、照合ミスという形で下流の分析に未知の誤差を混入させ、推定値にバイアスを与えたり、信頼区間を不当に膨らませたりするリスクがある。 著者は、現在のレコードリンケージの扱いは、数十年前に欠損値が単なる削除や単純な補完で処理されていた状況に似ていると指摘する。欠損値が現在では原則に基づいた統計的手法を必要とする問題として認識されているように、レコードリンケージもまた、その不確実性を定量化し、厳密に扱うべき対象である。既存の照合手法には大きな課題がある。…
核心:何を提案したのか
本論文は、学習データを全く必要とせずに高精度なレコードリンケージを実現する新手法「EnsembleLink」を提案している。この手法の核心的なアイデアは、近年の自然言語処理の進歩によって誕生した大規模なテキストコーパスで学習済みのモデルが、レコ…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related