単一の参照を超えて:手話翻訳における言い換えを用いた学習と評価
現在の手話翻訳(SLT)データセットは、一つの手話に対して一つの書き言葉しか対応していないため、翻訳の多様性を評価できないという課題がありました。本研究では、大規模言語モデル(LLM)を用いて書き言葉のパラフレーズ(言い換え)を自動生成し、複数の正解候補(参照訳)として活用する手法を提案しました。
TL;DR(結論)
現在の手話翻訳(SLT)データセットは、一つの手話に対して一つの書き言葉しか対応していないため、翻訳の多様性を評価できないという課題がありました。本研究では、大規模言語モデル(LLM)を用いて書き言葉のパラフレーズ(言い換え)を自動生成し、複数の正解候補(参照訳)として活用する手法を提案しました。 検証の結果、パラフレーズを学習に組み込む単純な手法は精度向上に寄与しませんでしたが、評価指標として複数のパラフレーズを用いる「BLEUpara」は、人間の主観評価とより強く相関することが確認されました。 研究チームは、GPT-4o miniが最も高品質なパラフレーズを生成することを突き止め、YouTubeASLやHow2Signといった主要データセット向けのパラフレーズデータと評価コードを公開し、より信頼性の高い手話翻訳評価の基盤を構築しました。
なぜこの問題か
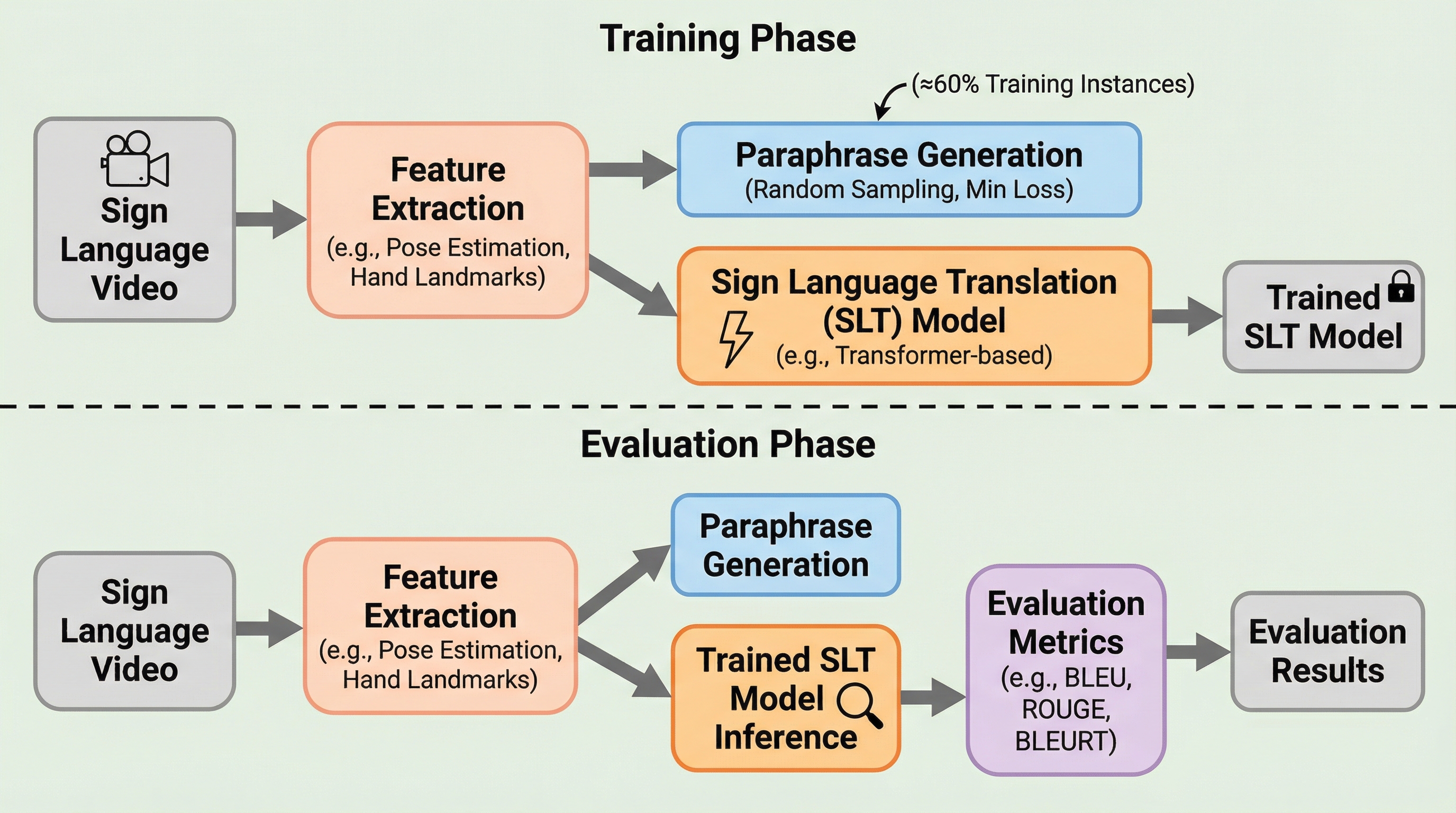
手話翻訳(SLT)の分野は、ビジョン言語モデルの進歩や大規模なビデオ・テキストコーパスの登場により急速な発展を遂げています。しかし、既存の手話翻訳データセットには、翻訳の多様性が著しく欠如しているという根深い問題が存在します。通常、一つの手話の発話に対して、一つの書き言葉の参照訳しかペアリングされていません。これは、複数の正解や表現のバリエーションが許容される自然言語の性質に反しています。特に手話と書き言葉の間には、語順や表現の具体性、構文構造が大きく異なる「非同型」な関係があるため、単一の参照訳に依存することは、モデルの学習を過度に制約し、評価の精度を著しく低下させるリスクがあります。 従来の評価指標であるBLEUなどは、n-gramの一致に基づいているため、参照訳の語彙や表現が少しでも異なると、翻訳の質が正しくてもスコアが低くなってしまいます。音声言語の機械翻訳では、複数の参照訳を用意したり、翻訳の選択肢を注釈したりすることが一般的ですが、手話翻訳ではそのようなリソースが不足しています。手話は視覚的な表現であり、一つの文章が複数の妥当な書き言葉に翻訳され得るため、この問題はより深刻です。…
核心:何を提案したのか
本研究の核心は、大規模言語モデル(LLM)を活用して、手話翻訳データセットの書き言葉部分を自動的にパラフレーズし、合成的な代替参照訳を生成することにあります。これにより、単一の参照訳しかない現状を打破し、古典的な自然言語処理(NLP)で用いられる「複数参照訳」の概念を手話翻訳に導入しました。具体的には、GPT-4o miniやLlamaなどの最新LLMを用いて、意味を維持しつつ語彙や構文を変化させた複数の言い換え文を生成する戦略を調査しました。 提案手法の重要な柱の一つは、生成されたパラフレーズの品質を測定するための指標「ParaScore」の適応です。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related