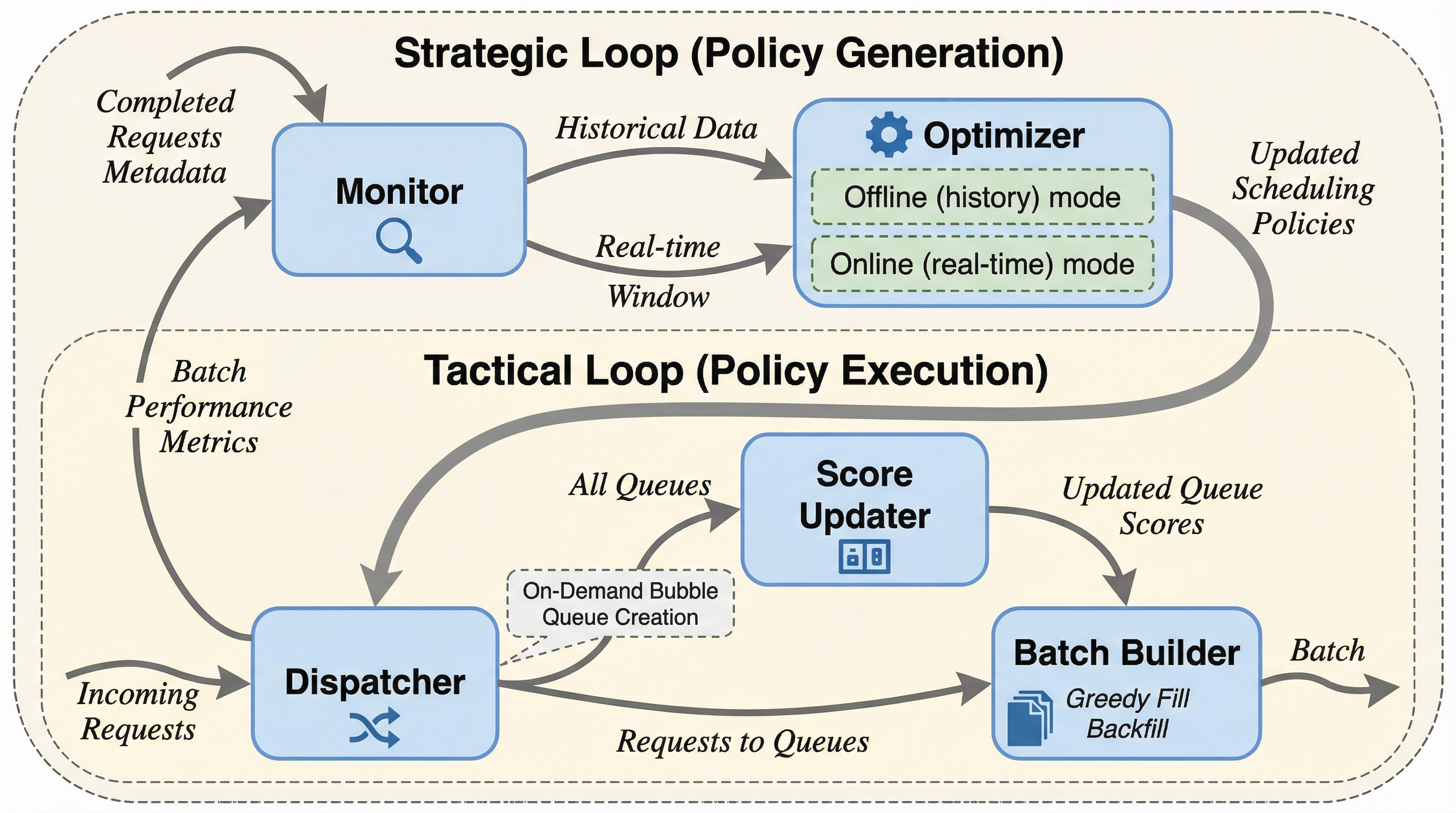
EWSJF: 混合ワークロードLLM推論のためのハイブリッド分割型適応スケジューラ
大規模言語モデル(LLM)の推論において、低遅延が求められる短文クエリとスループット重視の長文バッチが混在する「混合ワークロード」は、従来の先入れ先出し(FCFS)方式では先頭ブロッキングを引き起こし、効率を著しく低下させていました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
大規模言語モデル(LLM)の推論において、低遅延が求められる短文クエリとスループット重視の長文バッチが混在する「混合ワークロード」は、従来の先入れ先出し(FCFS)方式では先頭ブロッキングを引き起こし、効率を著しく低下させていました。
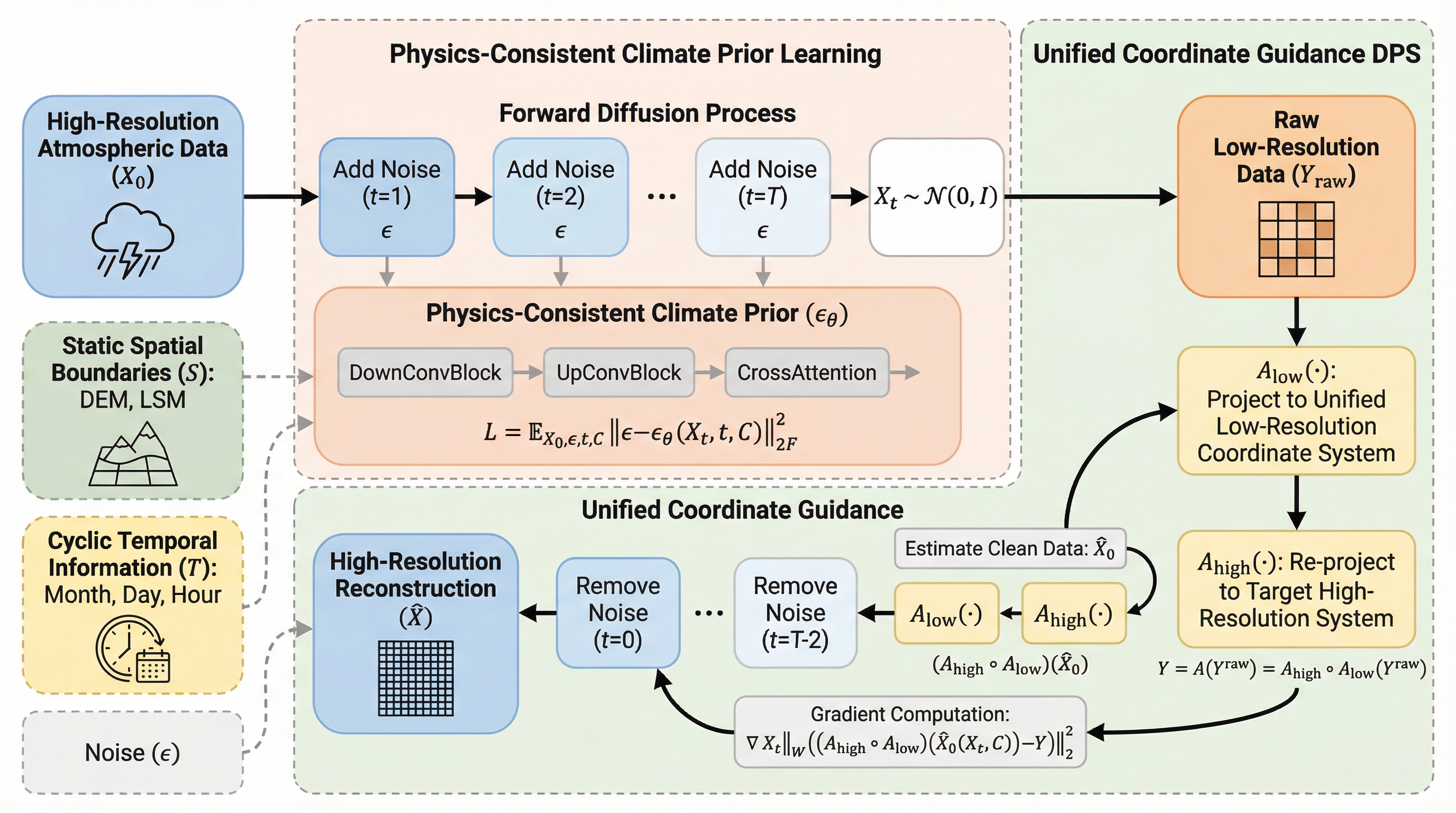
本研究は、全球気候モデル(GCM)と再解析データの間にペアとなる訓練データが存在しないという課題を解決するため、再解析データのみで学習可能な「ゼロショット統計的ダウンスケーリング(ZSSD)」を提案した。
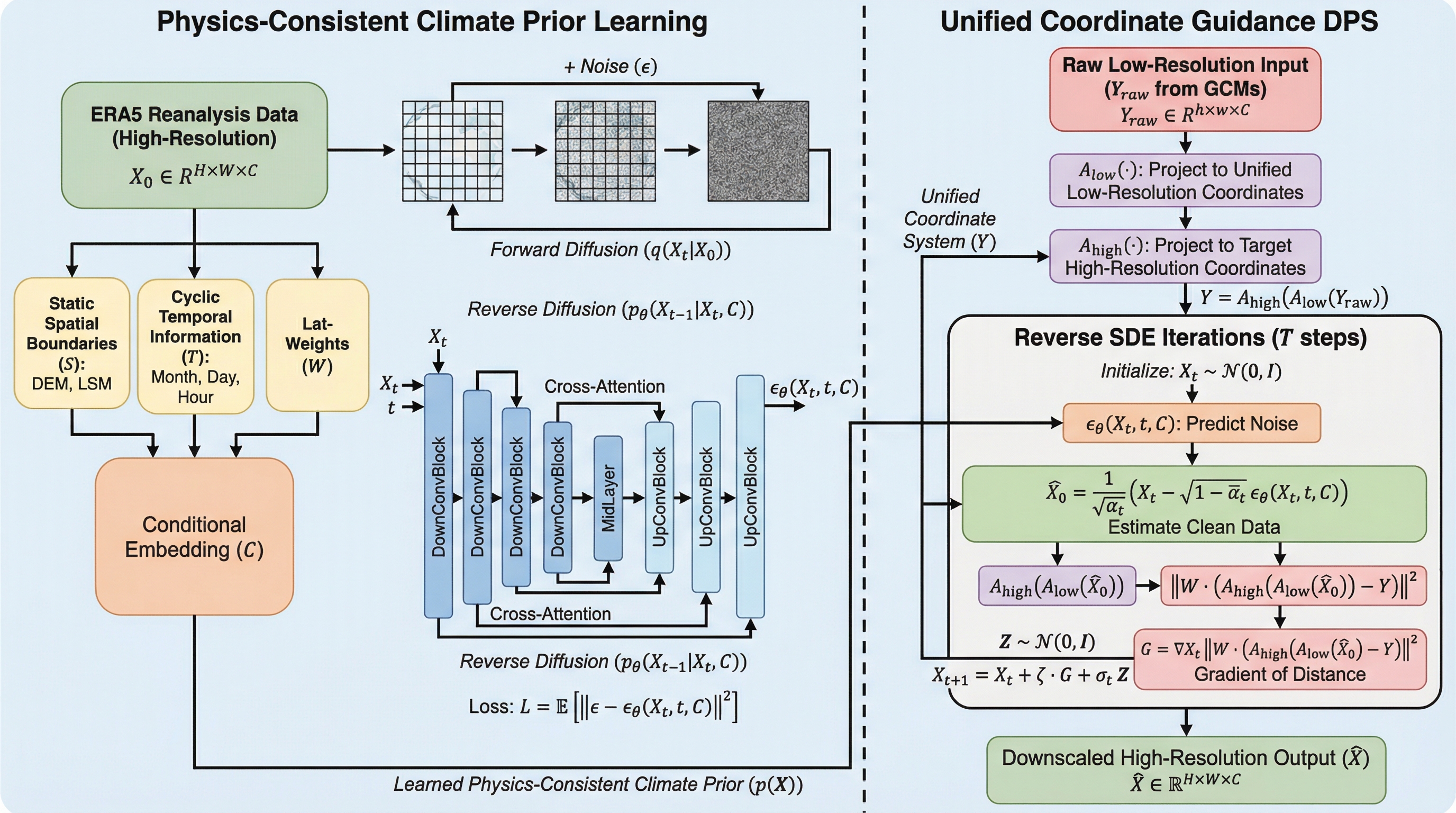
従来の教師あり学習による気候ダウンスケーリングは、全球気候モデル(GCM)と再解析データの間にペアとなる訓練データが存在しないため、異なるモデルへの汎化性能が著しく低いという課題がありました。本研究が提案するZSSDは、再解析データから学習した物理的に一貫性のある気候事前分布と、大規模なスケーリングにおける勾配消失問題を解決する統一座標ガイダンスを組み合わせることで、ペアデータなしでの高精度な復元を可能にしました。検証の結果、ZSSDは既存のゼロショット手法を大幅に上回る精度を達成し、熱帯低気圧のような複雑な気象イベントを、異なる特性を持つ複数の全球気候モデルにわたって一貫して再現することに成功しました。
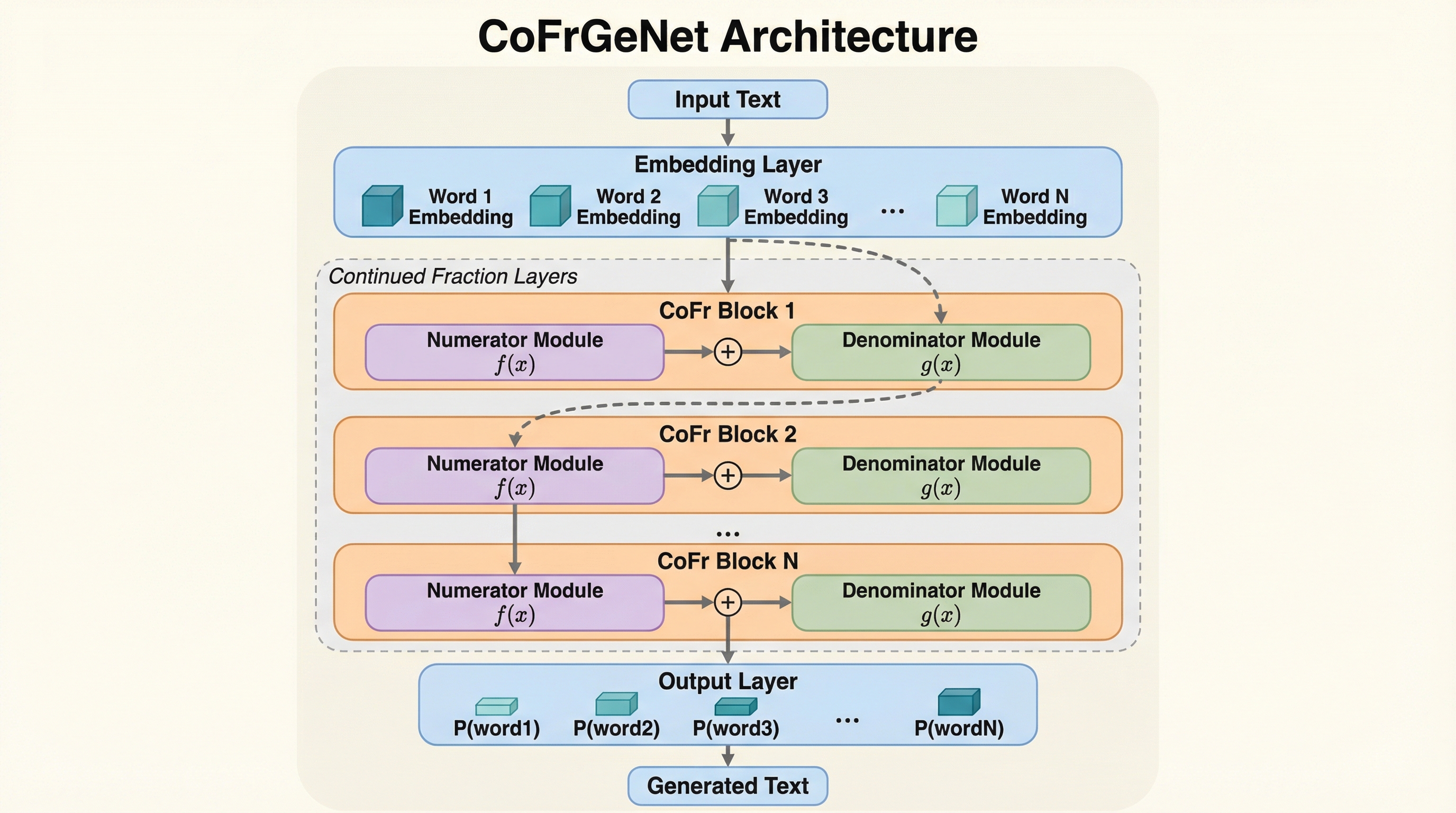
IBM Researchの研究チームは、連分数(Continued Fractions)の数学的構造を言語生成モデルに組み込んだ新アーキテクチャ「CoFrGeNet」を提案しました。このモデルは、従来のTransformerにおけるマルチヘッドアテンションやフィードフォワードネットワーク(FFN)を、より少ないパラメータ数で代替可能な連分数コンポーネントへと置き換えることに成功しています。 独自の「コンティニュアント(Continuants)」を用いた計算手法を導入することで、連分数計算のボトルネックであった除算回数を劇的に削減し、学習および推論の効率を飛躍的に向上させました。これにより、計算リソースの消費を抑えつつ、高度な言語生成能力を維持することが可能になります。 GPT2-xlやLlama3を用いた大規模な実験の結果、元のモデルの半分から3分の2程度のパラメータ数でありながら、分類、質疑応答、推論などの多様なタスクにおいて、標準的なTransformerと同等以上の性能をより短い学習時間で達成できることを実証しました。
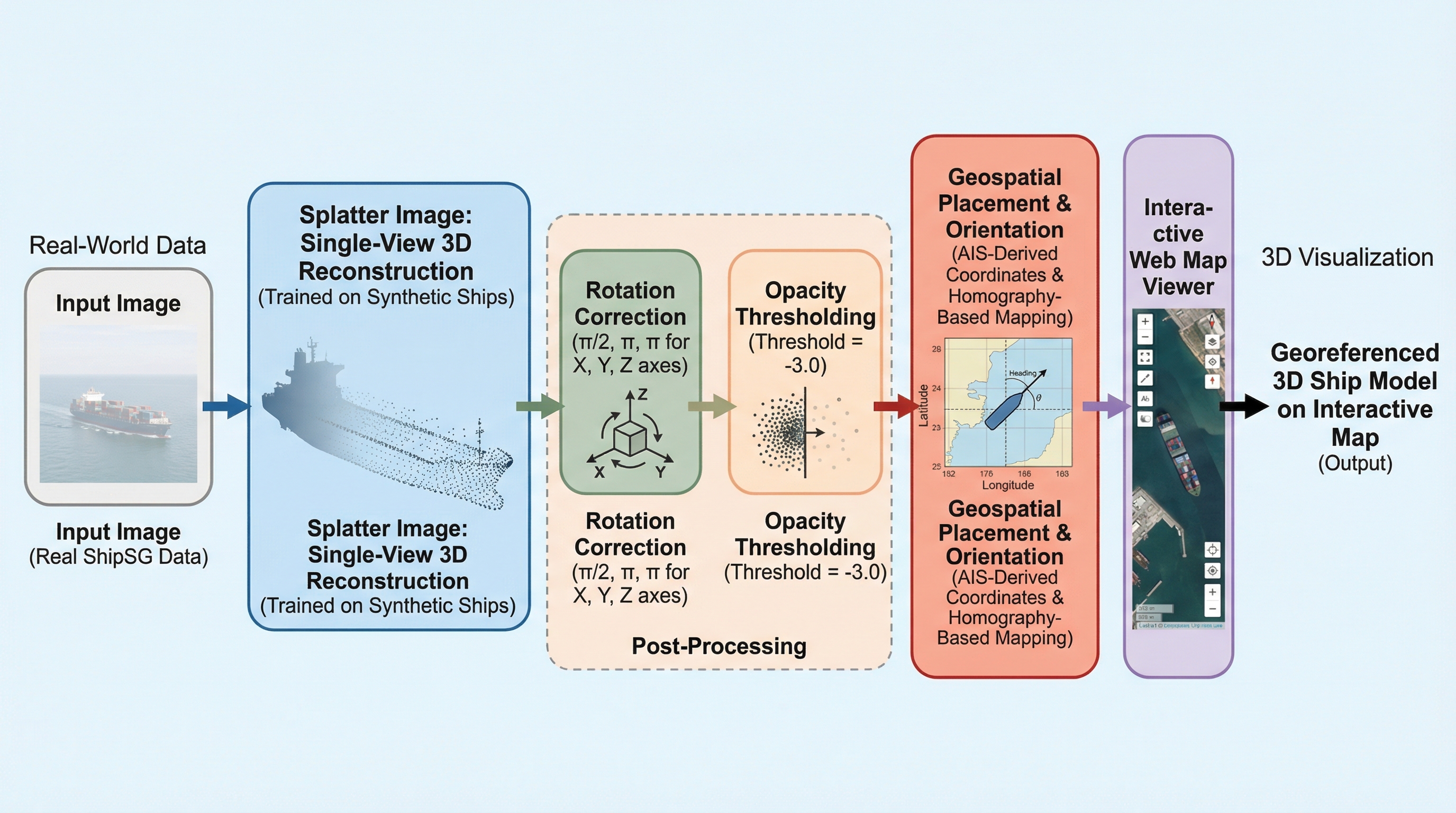
本研究は、実世界の3Dアノテーションを一切必要とせず、完全に合成データのみで学習を行うことで、単一の画像から船舶の3Dモデルを再構成する効率的なパイプラインを提案しています。 3Dガウス表現を用いるSplatter Imageネットワークを基盤とし、ShapeNetの船舶データと独自に作成した高精度な合成船舶データセットの2段階でファインチューニングを行うことで、合成データと実データのドメインギャップを克服しています。 YOLOv8によるセグメンテーション、AISメタデータを用いた実寸スケーリング、地理参照によるWebマップ上への配置を統合しており、港湾監視や船舶の寸法検証などの実用的な海洋状況把握を支援するシステムとして機能します。
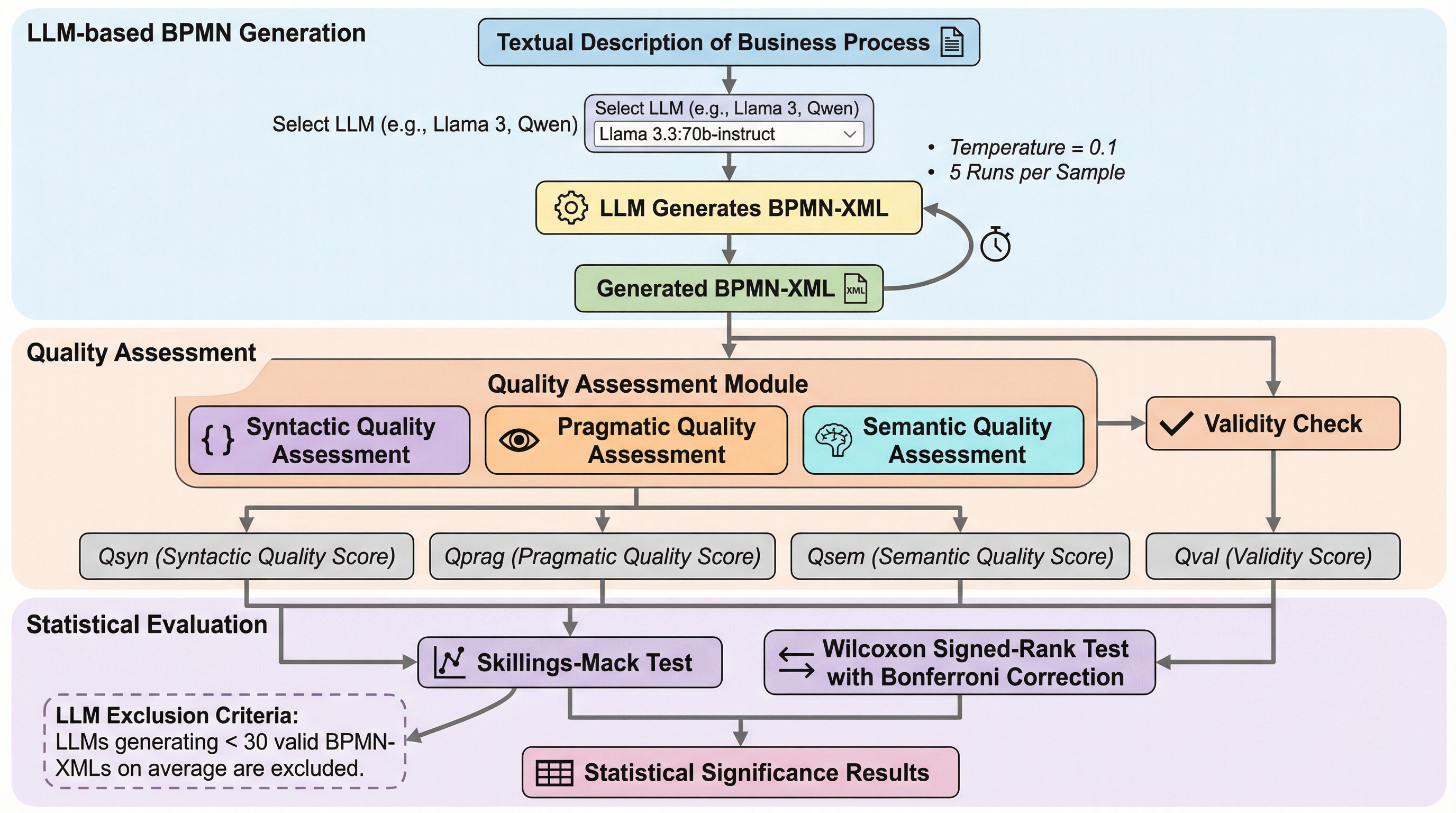
ビジネスプロセスモデリング(BPMN)における大規模言語モデル(LLM)の能力を客観的に評価するため、39個の指標を用いた新しい評価フレームワーク「BEF4LLM」が開発されました。17種類のオープンソースLLMを対象とした大規模なベンチマーク調査により、LLMは構文や実用性の面で優れた成果を出す一方で、意味論的な正確性や有効なXML形式の生成には依然として課題があることが判明しました。特に、モデルの規模が必ずしもモデリング品質の向上に直結しないという結果は、今後のLLMの選択や特定のタスクに向けた微調整において、パラメータ数以外の要素を重視すべきであることを示唆しており、LLMが専門家と同等のモデルを作成できる可能性を示しつつ、実用化に向けた具体的な改善点を明確にしました。
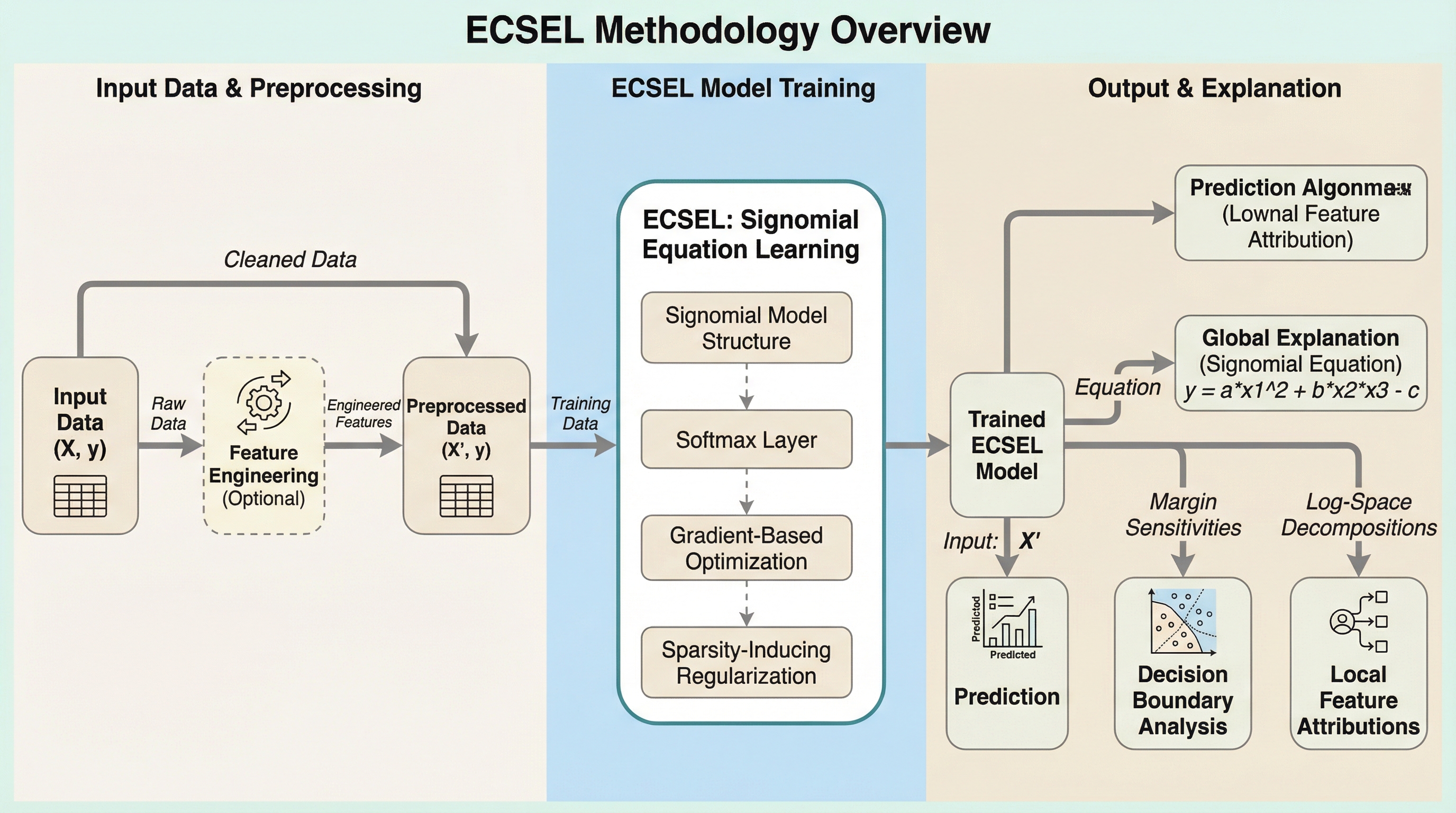
ECSELは、物理法則に多く見られる「シグノミアル方程式」という数式形式を学習モデルに採用することで、高い予測精度と人間が直接読み解ける透明性を両立した新しい分類手法である。 従来の記号回帰手法が抱えていた膨大な計算コストという課題を、勾配ベースの最適化とL1正則化を組み合わせることで解決し、既存の最先端手法を上回る数式復元率と劇的な計算時間の短縮を達成した。 学習された数式からは、特徴量の変化が予測に与える影響を弾力性や反実仮想推論といった数学的指標で直接算出でき、不正検知や電子商取引などの実務において根拠に基づいた意思決定を強力に支援する。
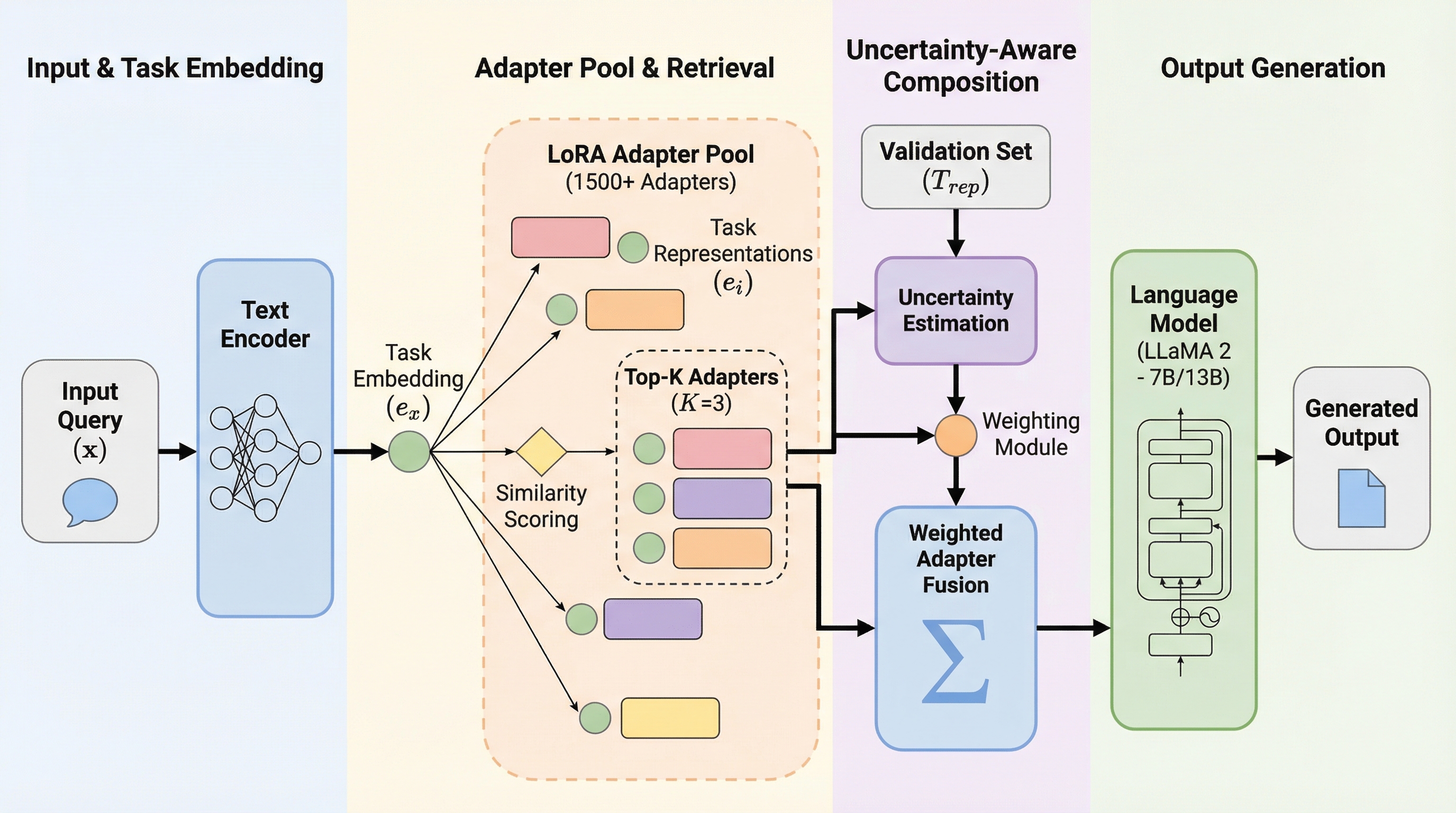
大規模言語モデルの効率的な専門化を実現するLoRAアダプターの膨大なプールから、入力クエリに最適なものを選択・統合する新しいルーティング枠組み「LORAUTER」が提案されました。 従来手法とは異なり、アダプターそのものの特性ではなく「タスク表現」を介してルーティングを行うことで、アダプターの学習データにアクセスできないブラックボックス設定でも動作し、タスク数に応じた高い拡張性を実現しています。 検証では、既存のタスクに最適化されたアダプターと同等以上の性能(101.2%)を達成したほか、未知のタスクに対しても従来手法を5.2ポイント上回る精度を示し、1500個以上のアダプターを含む大規模でノイズの多い環境でも堅牢に機能することが確認されました。
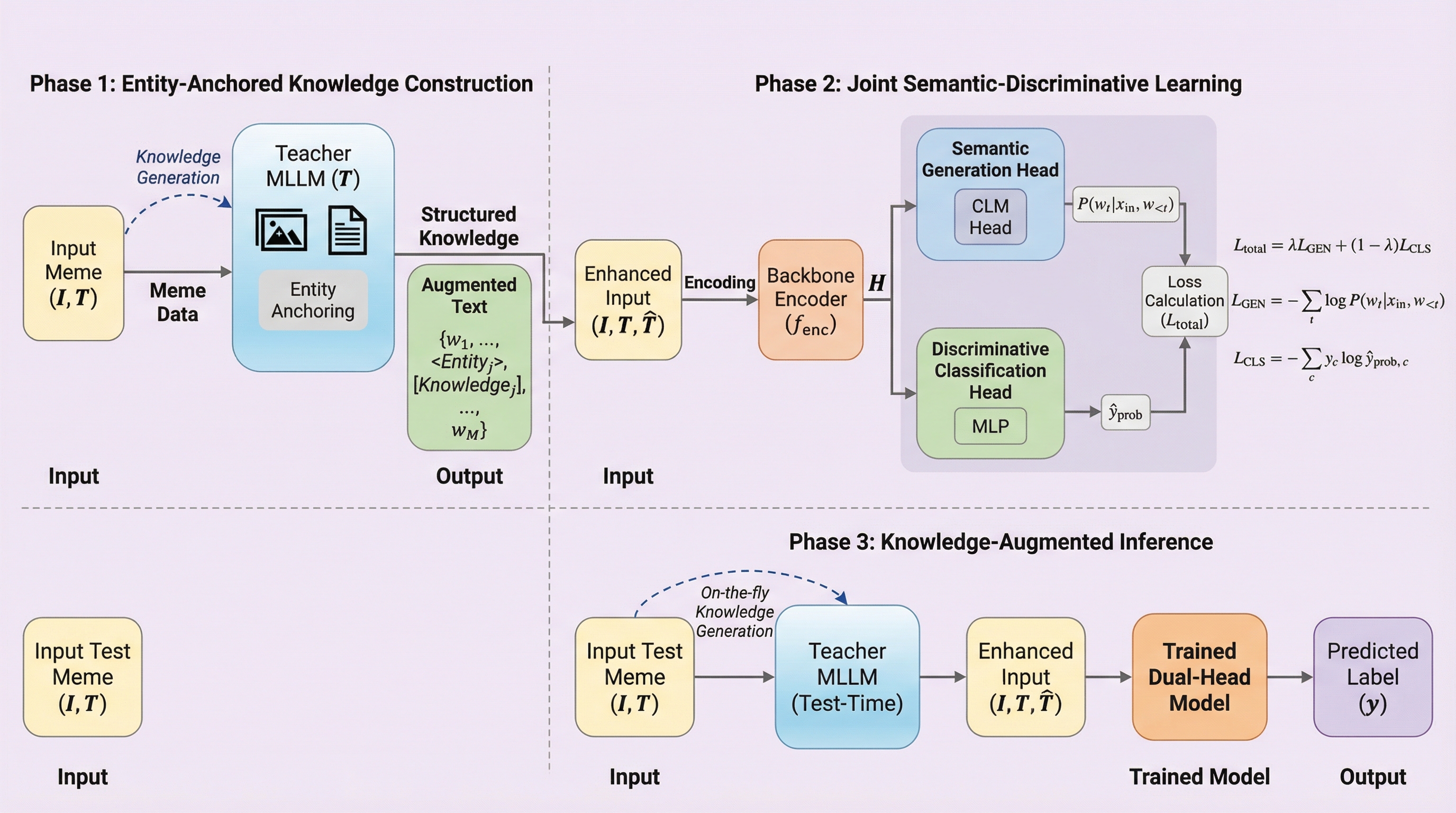
インターネット上のミームは比喩や文化的背景に深く依存しており、従来のモデルでは表面的な情報の処理に留まり、潜在的な有害性を見逃す「知識と文脈の断絶」という課題がありました。本研究が提案するKIDフレームワークは、視覚的エンティティに背景知識を紐付ける「エンティティ・アンカー型知識注入」と、意味生成と分類を同時に最適化する「デュアルヘッド学習」により、複雑な推論を可能にします。英語、中国語、ベンガル語の5つのデータセットを用いた実験の結果、既存の最先端手法を2.1%から19.7%上回る性能を記録し、多言語や低リソースな環境においても極めて高い汎用性と堅牢性を示しました。
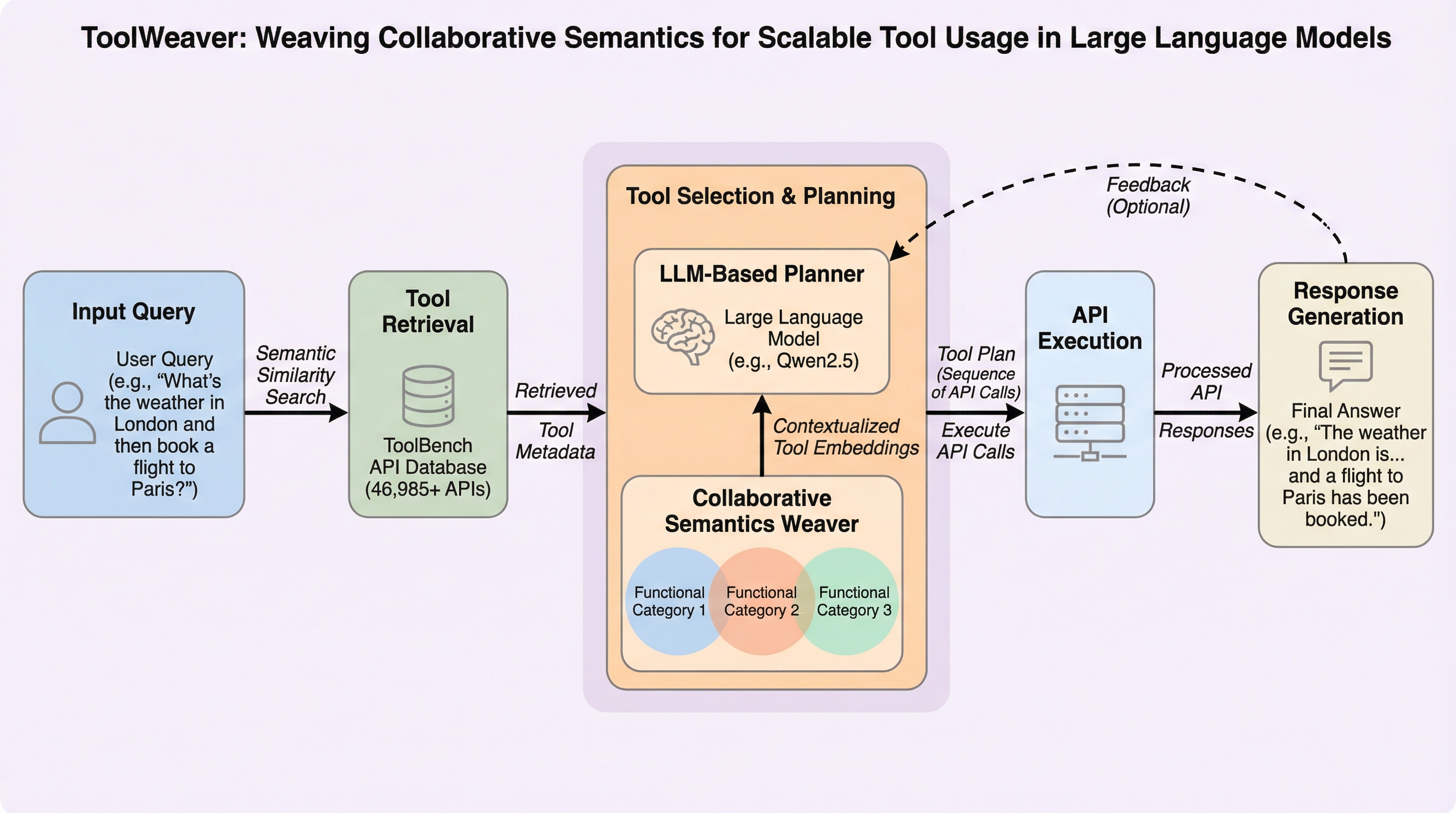
従来の大規模言語モデルにおけるツール利用手法は、ツールごとに固有のトークンを割り当てる方式により、語彙数の膨張とツール間の関連性学習の困難さという課題に直面していました。本研究が提案するToolWeaverは、ツールを階層的なコード配列として表現することで、語彙の拡張を対数スケールに抑制し、ツール間の共起関係を直接学習可能な構造を実現しています。 約47,000個のツールを用いた検証の結果、ToolWeaverは従来手法を大幅に上回る性能を示し、モデルの言語能力を維持しつつ複雑なタスクを完遂できる高い汎用性を証明しました。 具体的には、ツールの内的な機能と外的な共起パターンを結合する「協調認識型ベクトル量子化」を導入し、複数のツールを連携させる必要がある高度な推論タスクにおいて、既存の検索ベースや生成ベースの手法を凌駕する精度を達成しています。