KID: 知識注入とデュアルヘッド学習による有害ミーム検出の最先端フレームワーク
インターネット上のミームは比喩や文化的背景に深く依存しており、従来のモデルでは表面的な情報の処理に留まり、潜在的な有害性を見逃す「知識と文脈の断絶」という課題がありました。本研究が提案するKIDフレームワークは、視覚的エンティティに背景知識を紐付ける「エンティティ・アンカー型知識注入」と、意味生成と分類を同時に最適化する「デュアルヘッド学習」により、複雑な推論を可能にします。英語、中国語、ベンガル語の5つのデータセットを用いた実験の結果、既存の最先端手法を2.1%から19.7%上回る性能を記録し、多言語や低リソースな環境においても極めて高い汎用性と堅牢性を示しました。
TL;DR(結論)
インターネット上のミームは比喩や文化的背景に深く依存しており、従来のモデルでは表面的な情報の処理に留まり、潜在的な有害性を見逃す「知識と文脈の断絶」という課題がありました。本研究が提案するKIDフレームワークは、視覚的エンティティに背景知識を紐付ける「エンティティ・アンカー型知識注入」と、意味生成と分類を同時に最適化する「デュアルヘッド学習」により、複雑な推論を可能にします。英語、中国語、ベンガル語の5つのデータセットを用いた実験の結果、既存の最先端手法を2.1%から19.7%上回る性能を記録し、多言語や低リソースな環境においても極めて高い汎用性と堅牢性を示しました。
なぜこの問題か
インターネットミームは現代のデジタル文化において急速に拡散する主要な媒体ですが、その有害性は画像とテキストの単純な組み合わせだけでは判断できないことが多々あります。ミームの毒性は、視覚的なシンボルとテキスト情報の間の複雑な相互作用の中に隠されており、比喩的な表現や社会文化的な背景、そして高度なクロスモーダルな意味的相互作用に強く依存しています。例えば、特定のブランド名とパンデミックを関連付けたミームでは、単なるビールの画像が特定の組織への攻撃へと変貌しますが、これを理解するにはブランド名とウイルスの名称の類似性という背景知識が不可欠です。既存の自動検出手法の多くは、画像とテキストのそれぞれの特徴を抽出して融合させるか、事前学習済みの視覚言語モデルを利用して明示的な相関関係を捉えることに焦点を当ててきました。しかし、これらの手法は表面的なレベルでの一致を確認するに留まり、ミームの背後にある文化的暗示や比喩的な推論を捉えることができていません。 特に、特定の地域特有の俗語やジェンダーに関するステレオタイプを用いた有害コンテンツは、明示的な攻撃ワードを含まないことが多く、従来のモデルでは「知識と文脈の断絶」が発生してしまいます。…
核心:何を提案したのか
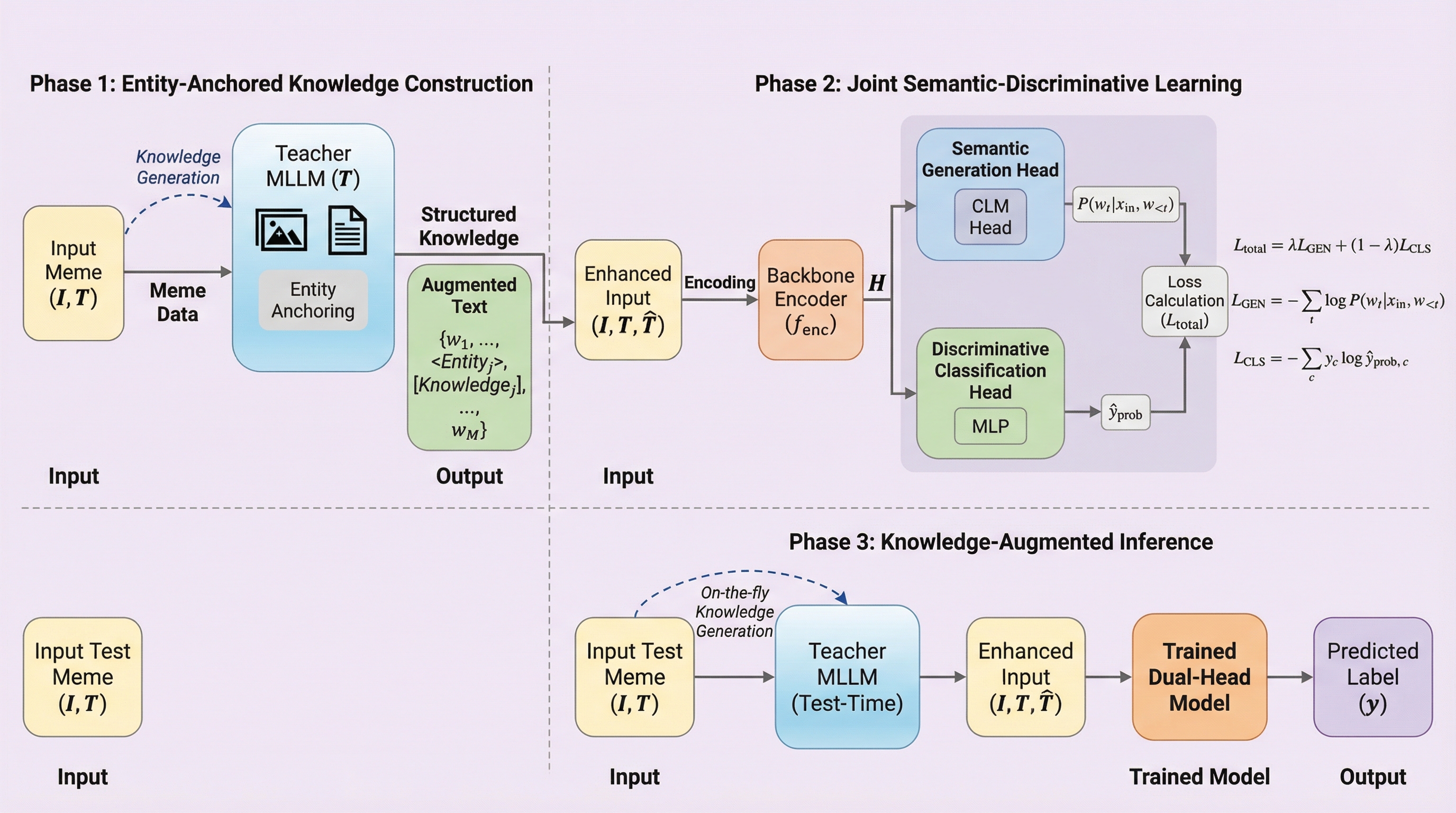
本研究では、上述の「知識と文脈の断絶」問題を解決するために、KID(Knowledge-Injected Dual-Head Learning)と呼ばれる新しいフレームワークを提案しました。KIDの核心的なアイデアは、モデルに対して背景知識をミーム固有の視覚・テキスト文脈に明示的に結びつけるよう導き、多様なタスクにおいて安定した意思決定の境界を維持させることにあります。このフレームワークは、単にピクセルからラベルへと直接マッピングするのではなく、「証拠・知識・ラベル」という構造化された推論チェーンを明示的にモデル化します。KIDの主要な構成要素の一つは、ラベル制約付きの蒸留パラダイムを採用した知識注入戦略です。これにより、複雑なミームの理解を、視覚的な証拠、背景知識、および分類ラベルを論理的にリンクさせる構造化された推論プロセスへと分解します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related