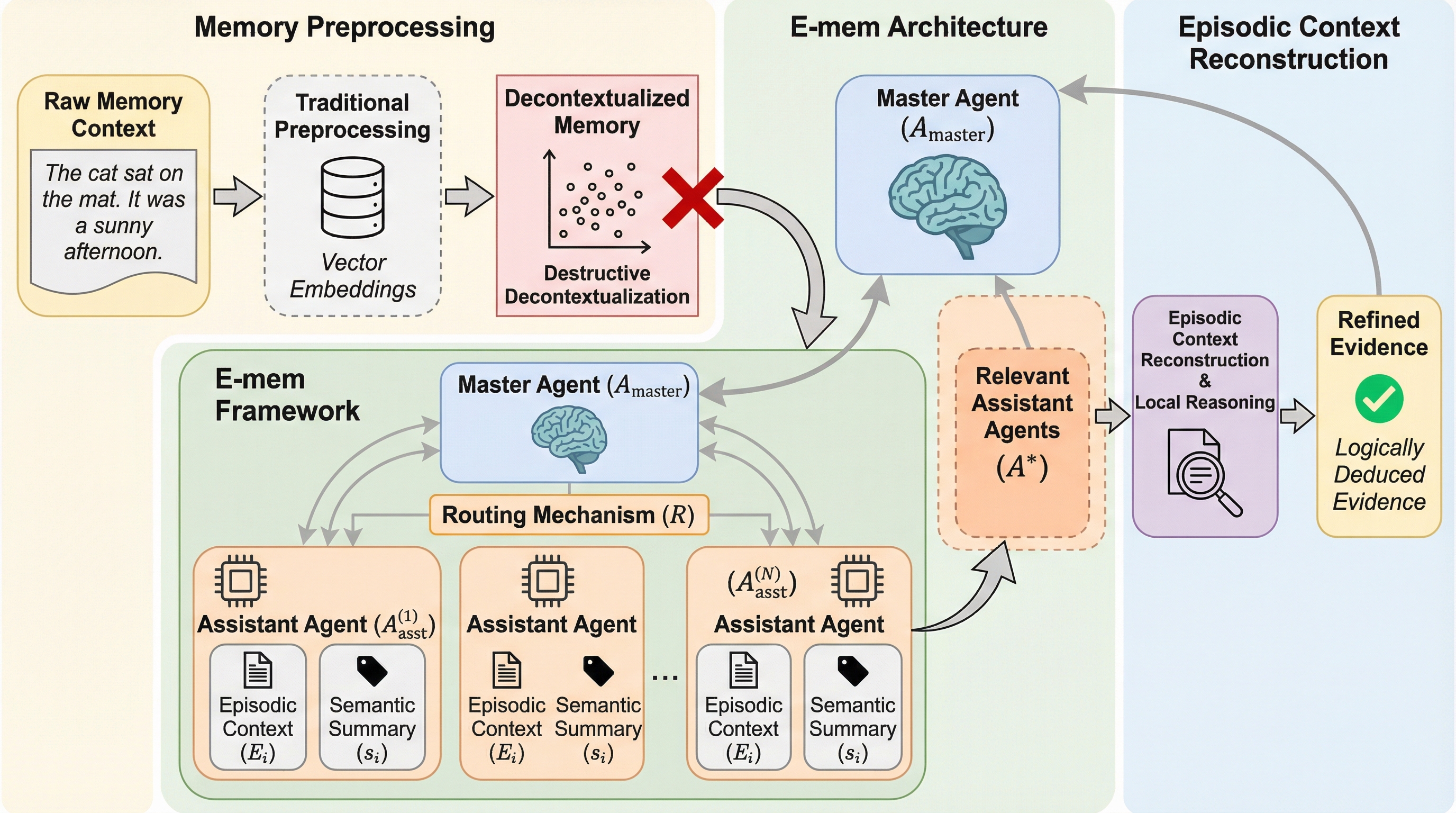
E-mem: マルチエージェントによるエピソード文脈再構成を用いたLLMメモリ管理
大規模言語モデル(LLM)エージェントが複雑な論理的思考を行う「システム2推論」において、従来のメモリ管理が抱えていた「破壊的な脱文脈化」という情報の欠落問題を解決するため、生物学的な記憶痕跡(エングラム)に着想を得た新しいフレームワーク「E-mem」が提案されました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
大規模言語モデル(LLM)エージェントが複雑な論理的思考を行う「システム2推論」において、従来のメモリ管理が抱えていた「破壊的な脱文脈化」という情報の欠落問題を解決するため、生物学的な記憶痕跡(エングラム)に着想を得た新しいフレームワーク「E-mem」が提案されました。
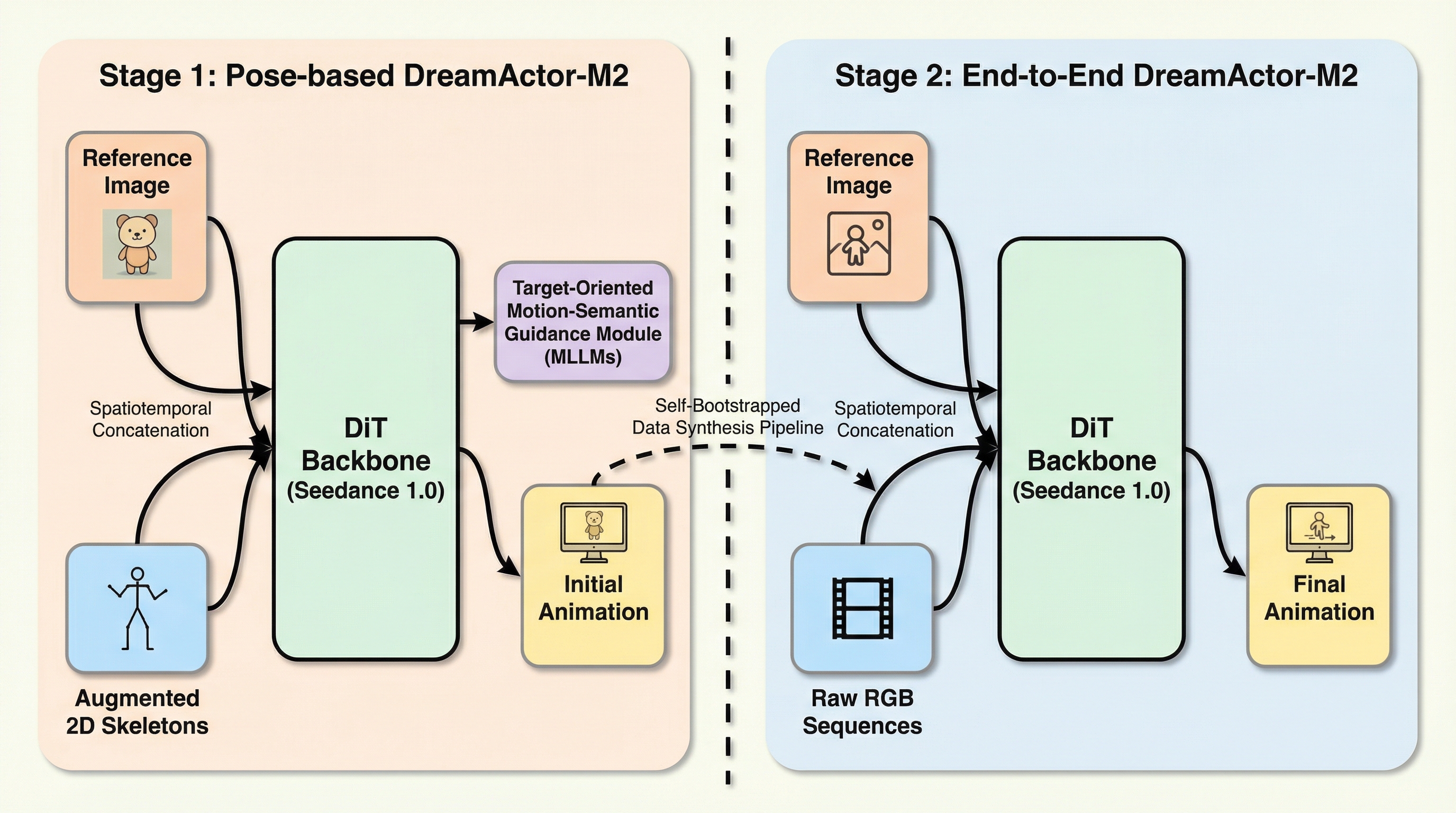
DreamActor-M2は、静止画のキャラクターに任意の動画の動きを転送する新しいアニメーション手法であり、情報の注入を「インコンテキスト学習」として再定義することで、外見の維持と動きの再現を高い次元で両立することに成功しました。
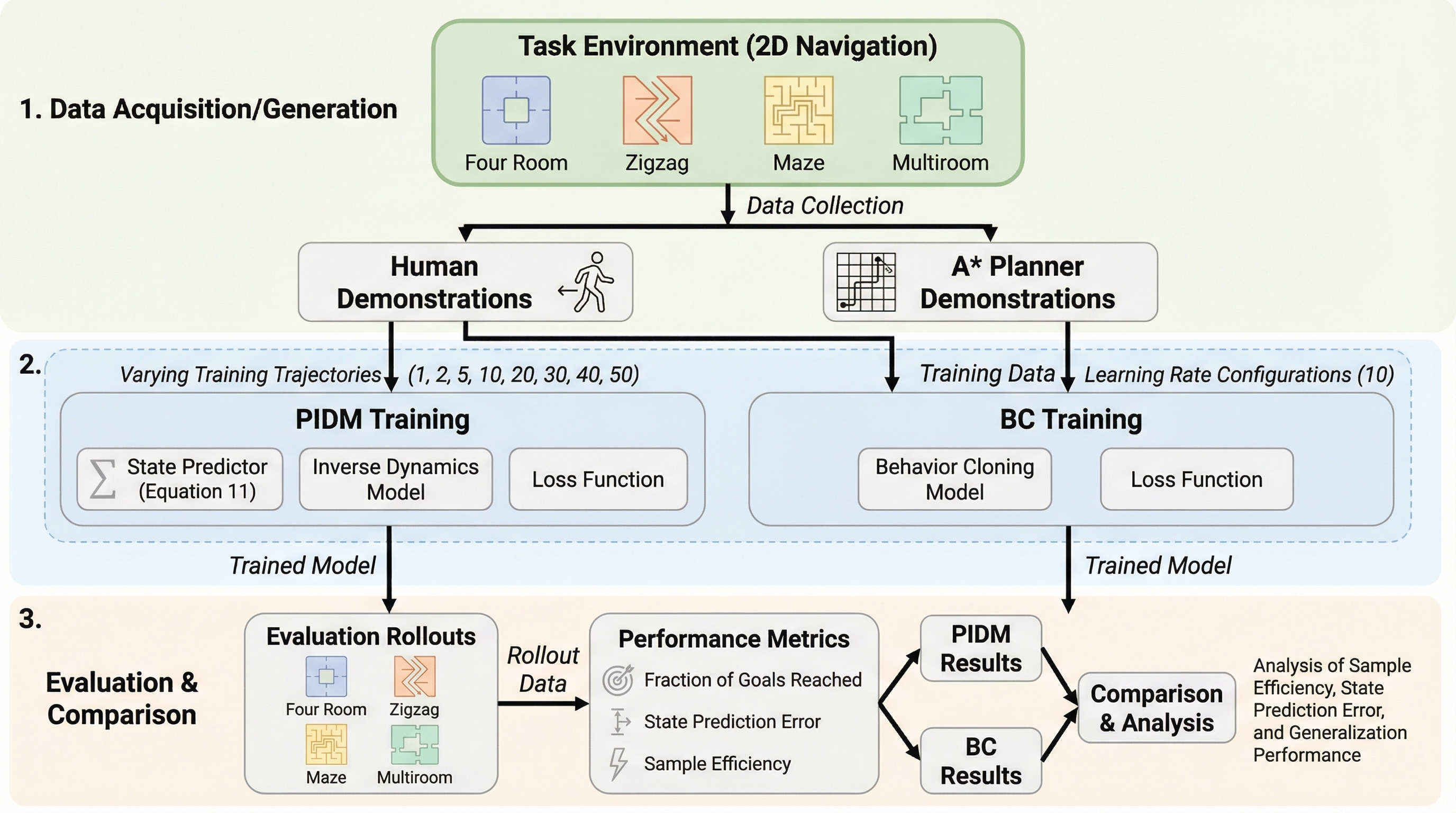
オフライン模倣学習において、未来の状態予測と逆ダイナミクスを組み合わせた予測逆ダイナミクスモデル(PIDM)が、従来の行動クローニング(BC)よりも高いサンプル効率を実現する理由を理論と実験の両面で解明しました。
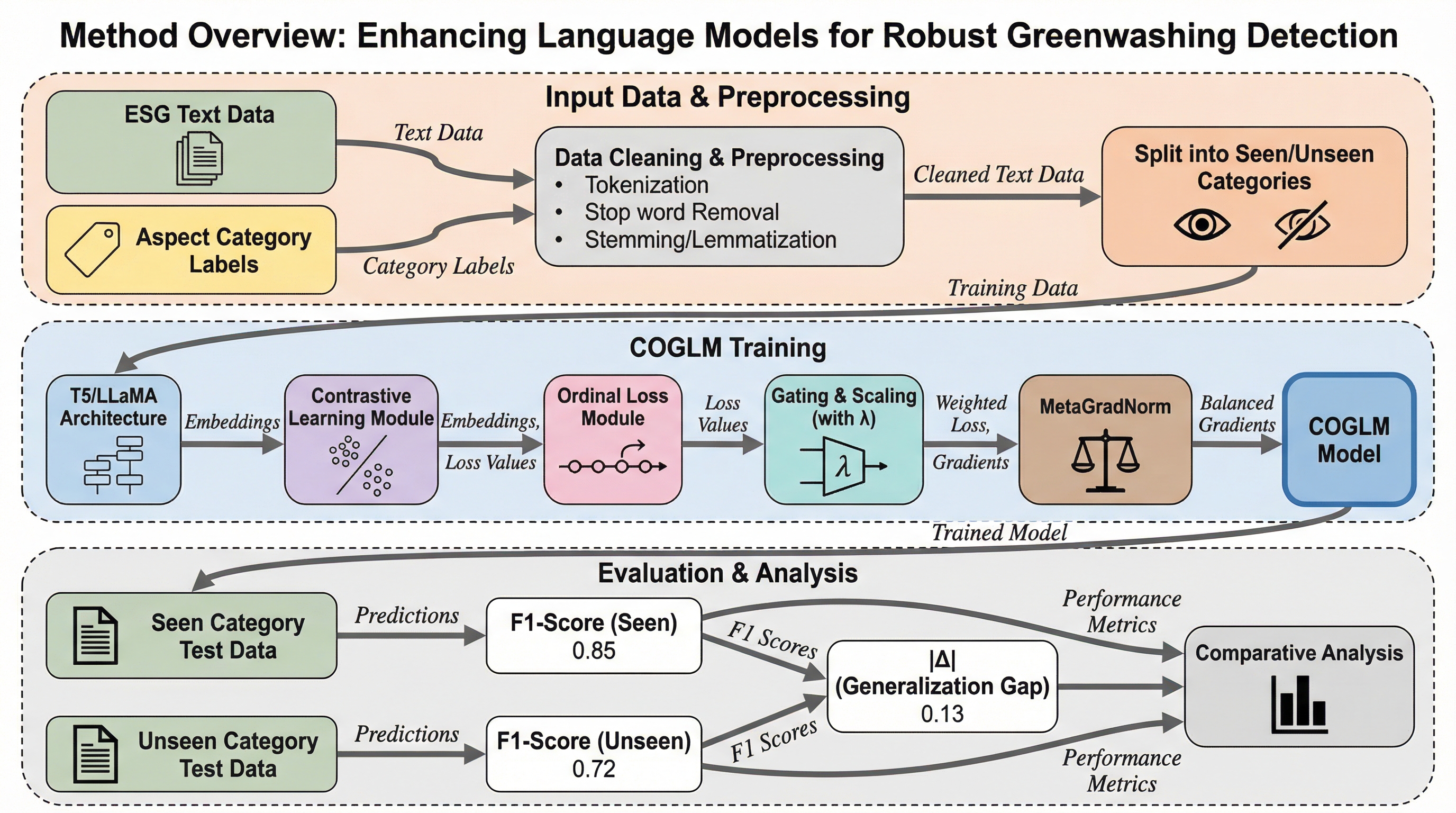
企業のサステナビリティ報告書におけるグリーンウォッシュや曖昧な主張を特定するため、大規模言語モデルの潜在空間を構造化する新しいパラメータ効率の良い学習フレームワーク「COGLM」が提案されました。
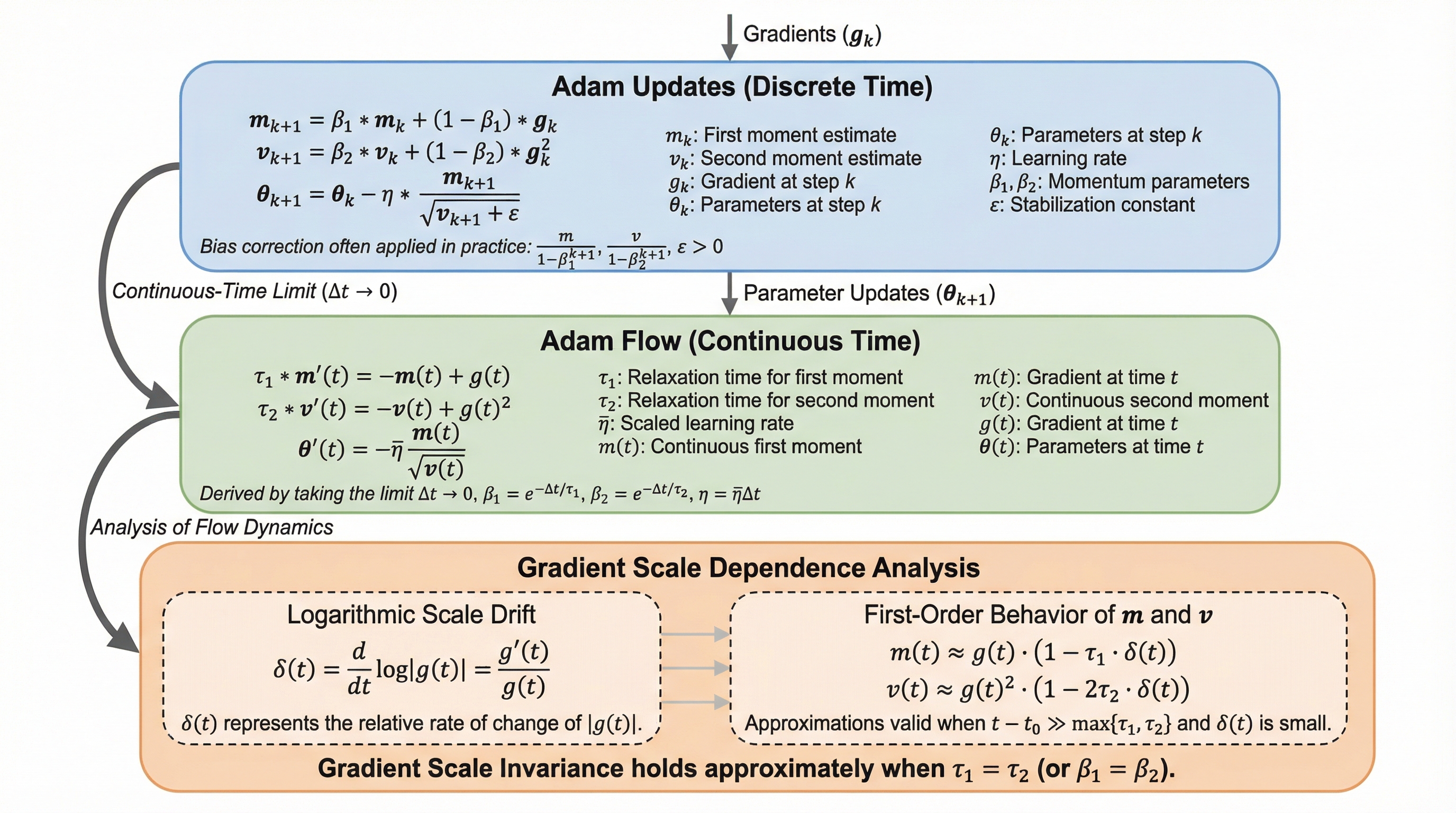
Adamのハイパーパラメータである$\beta1$と$\beta2$を等しく設定することで、訓練の安定性と精度が向上するという経験的事実に対し、「勾配スケール不変性」という新たな理論的枠組みを導入して数学的な解明を行った。
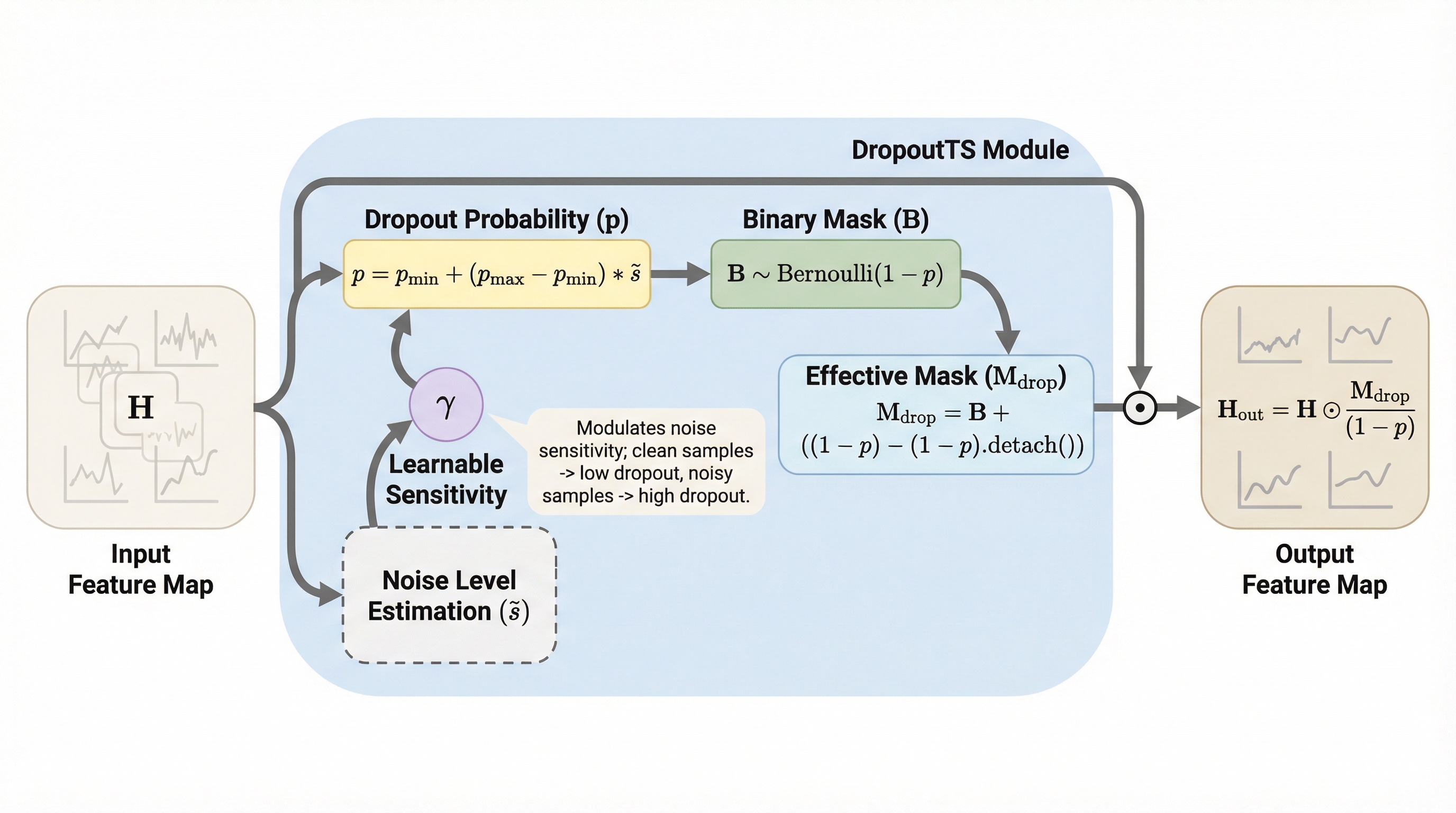
深層時系列予測モデルが実世界のノイズに対して脆弱であるという課題に対し、データの削除や複雑な事前分布の仮定に頼らず、モデルの学習容量をサンプルごとに動的に調整する新しいパラダイム「容量中心の変調(Capacity-Centric Modulation)」を提案した。
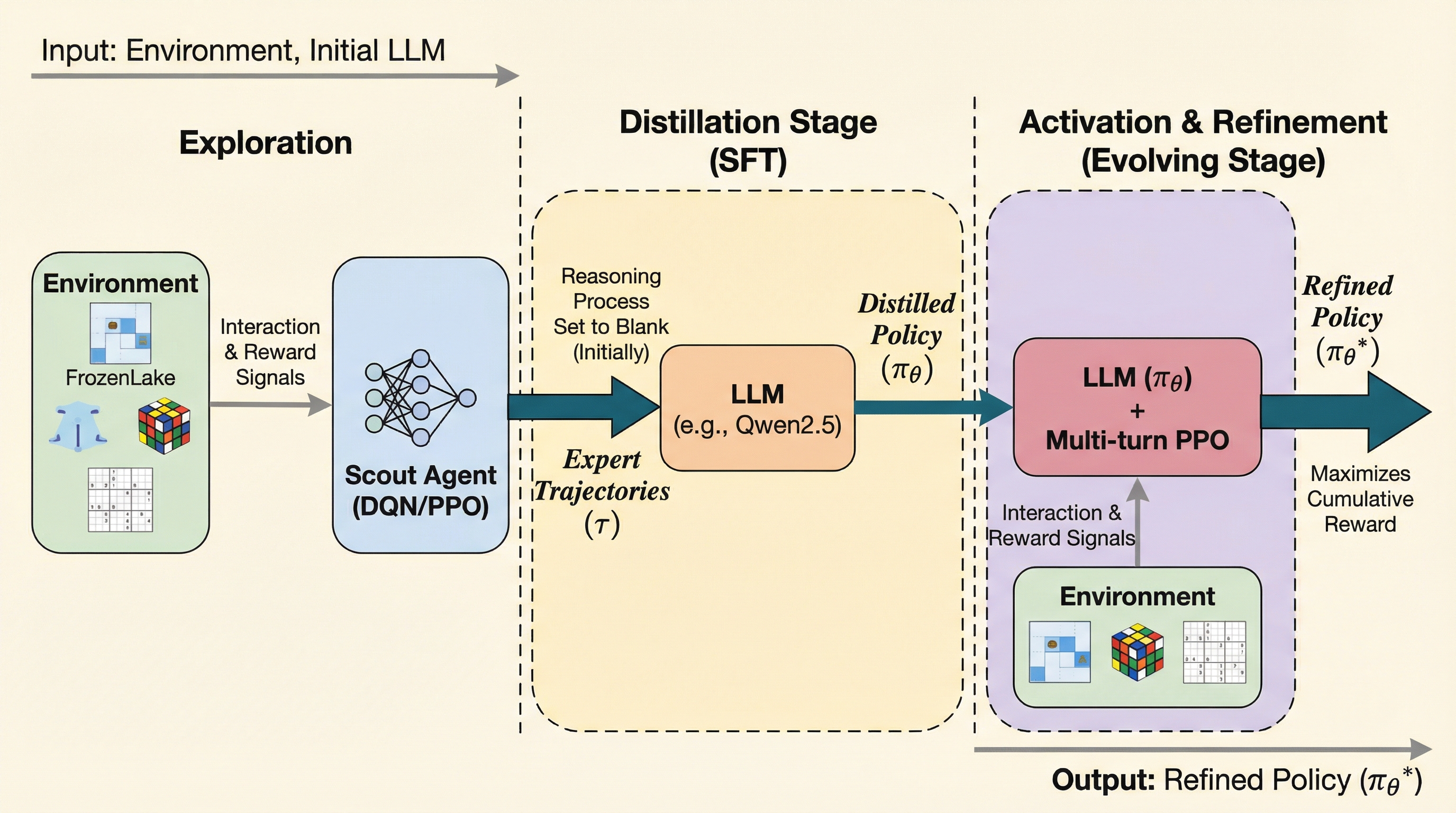
大規模言語モデル(LLM)は言語タスクには強いものの、記号的・空間的な未知のタスクでは膨大なパラメータによる探索コストが障壁となり、試行錯誤の効率が著しく低いという課題がある。 本研究が提案するSCOUTは、軽量なニューラルネットワーク(スカウト)に環境探索を任せて成功軌跡を生成し、それをテキスト化してLLMに蒸留した後、多ターン強化学習で能力を活性化させる新しいフレームワークである。 実証実験では、Qwen2.5-3Bモデルが平均スコア0.86を記録し、Gemini-2.5-Proなどの商用モデルを大幅に上回る性能を示しながら、計算リソースであるGPU時間を約60%削減することに成功した。
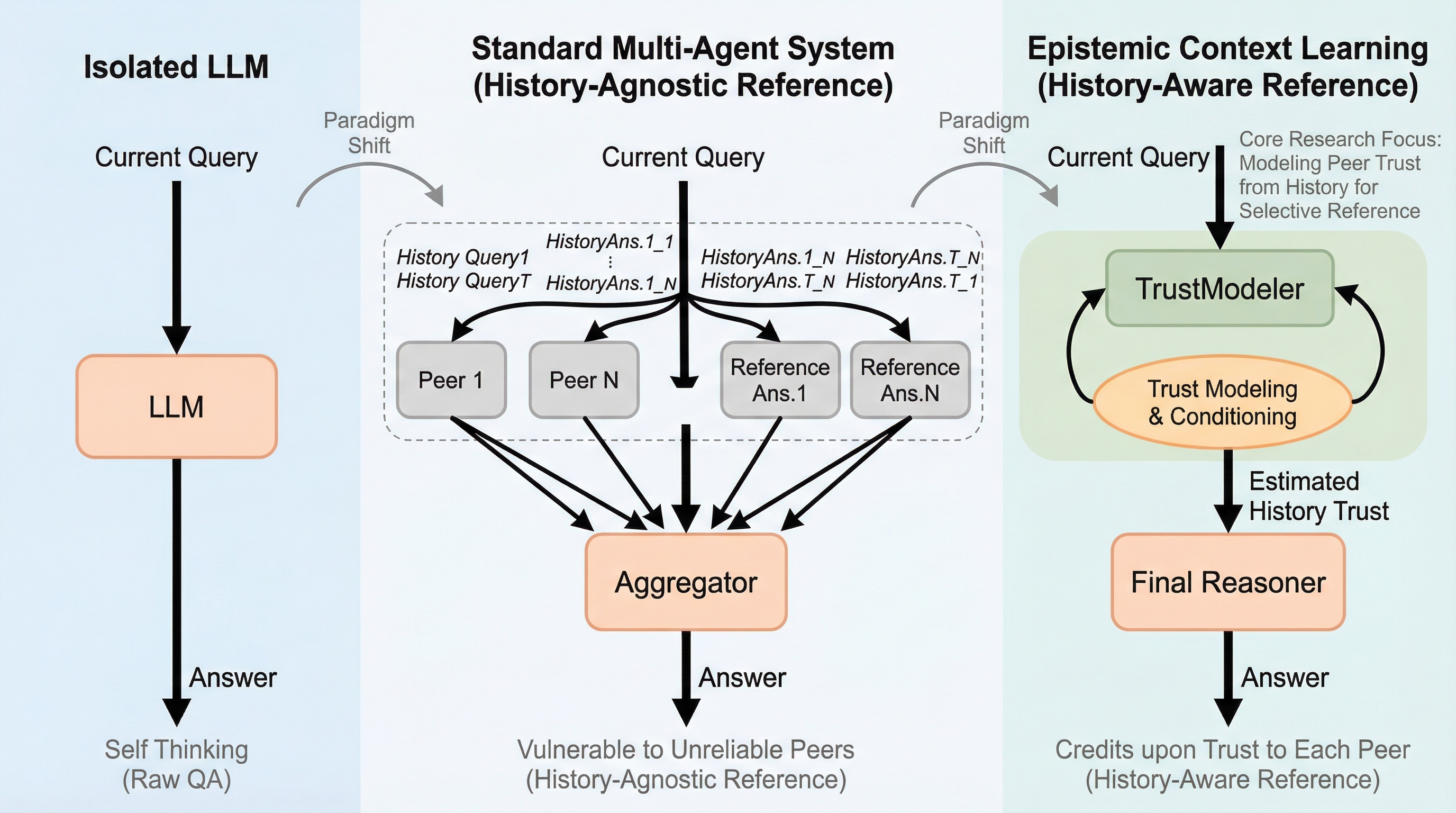
LLMベースのマルチエージェントシステムにおいて、エージェントが誤った情報を持つ他者に盲目的に同調してしまう脆弱性を解決するため、過去の対話履歴から他者の信頼性を評価して情報を選択的に参照する「履歴を考慮した参照」という新しいパラダイムを提案した。
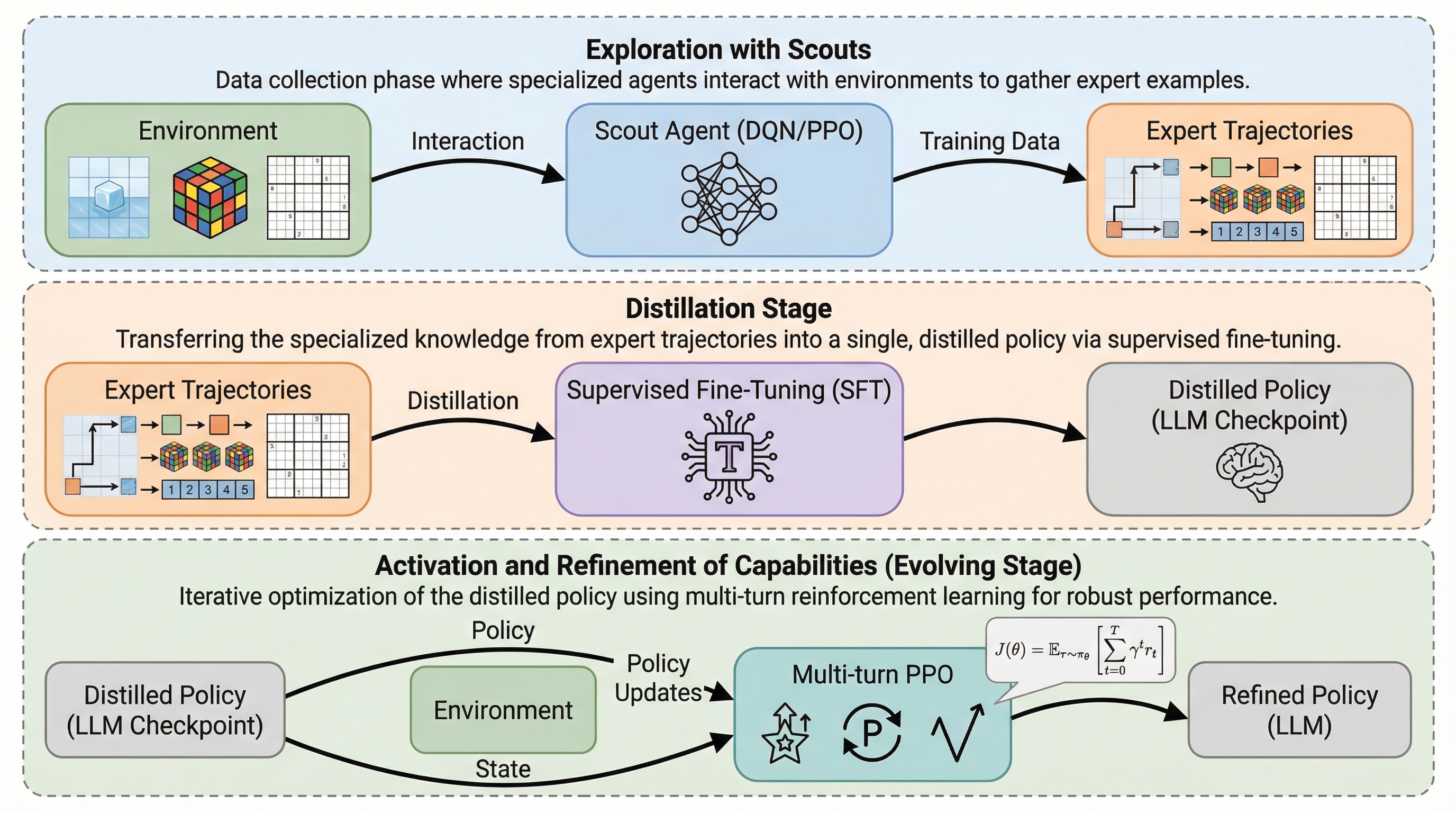
大規模言語モデル(LLM)は言語タスクには強いものの、記号や空間を扱う未知の非言語タスクでは、膨大なパラメータによる試行錯誤の計算コストが極めて高く、効率的な探索が困難であるという根本的な課題を抱えている。
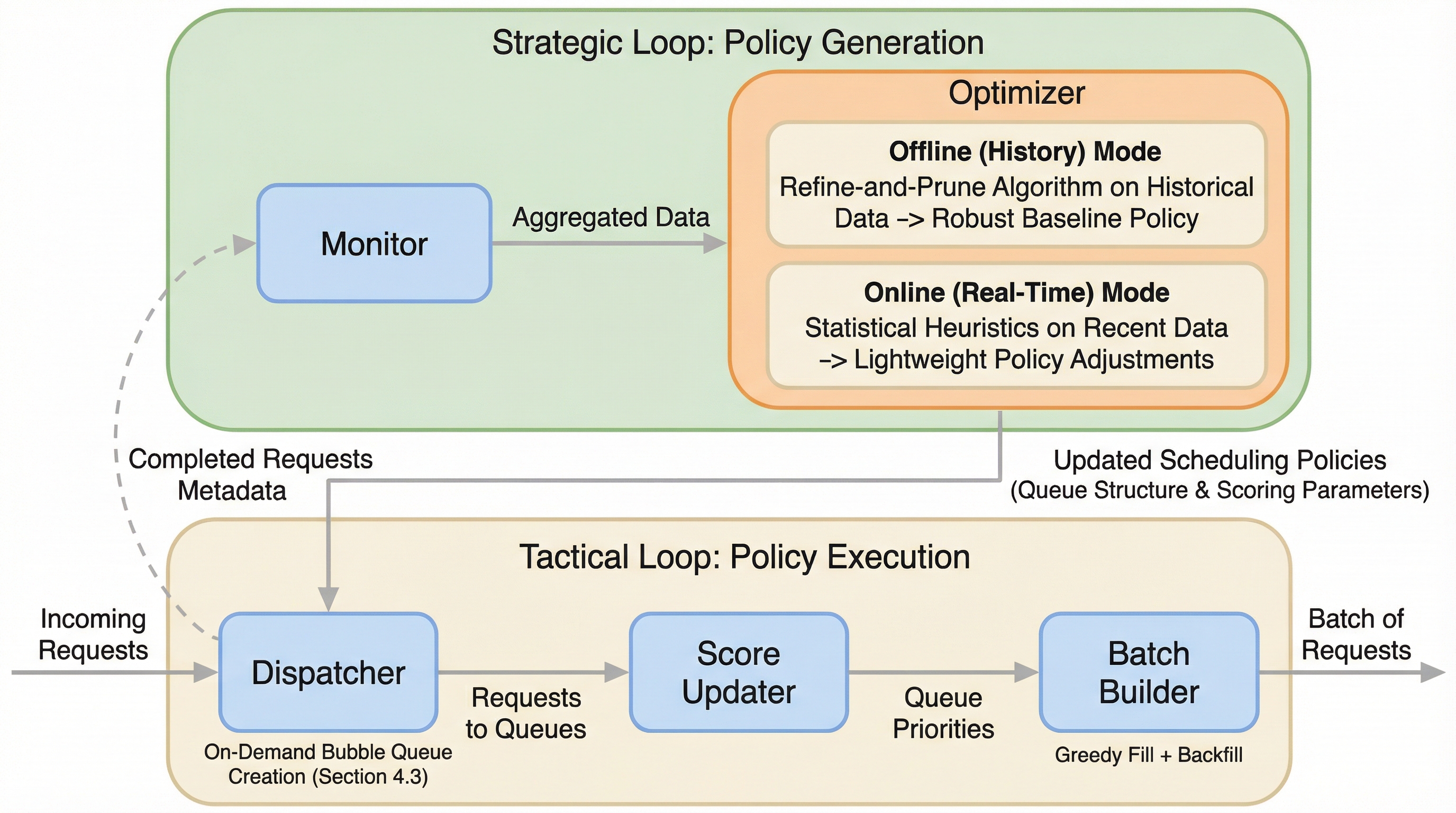
大規模言語モデル(LLM)の推論において、短時間の対話型クエリと長時間のバッチ処理が混在すると、従来の先着順方式では長い処理が先頭で詰まり、応答遅延やハードウェア効率の低下を招くという課題がある。