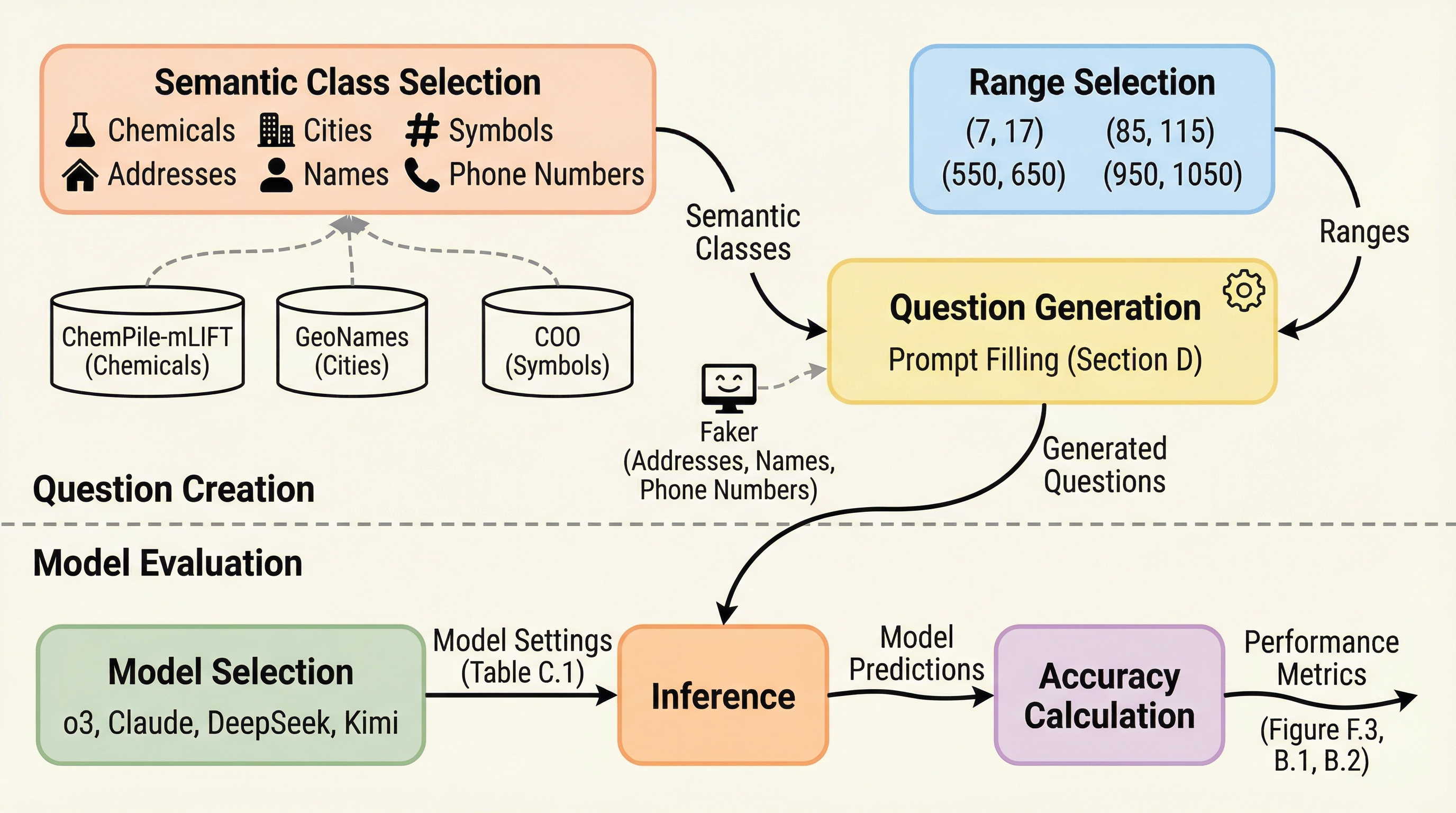
意味的内容がアルゴリズムの性能を決定する
大規模言語モデル(LLM)は、本来なら入力の意味に左右されないはずの計数のようなアルゴリズム的タスクにおいて、対象が「都市名」か「化学物質名」かといった意味的内容(セマンティック・クラス)によって正解率が40%以上も変動するという重大な脆弱性を持っていることが明らかになった。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
大規模言語モデル(LLM)は、本来なら入力の意味に左右されないはずの計数のようなアルゴリズム的タスクにおいて、対象が「都市名」か「化学物質名」かといった意味的内容(セマンティック・クラス)によって正解率が40%以上も変動するという重大な脆弱性を持っていることが明らかになった。
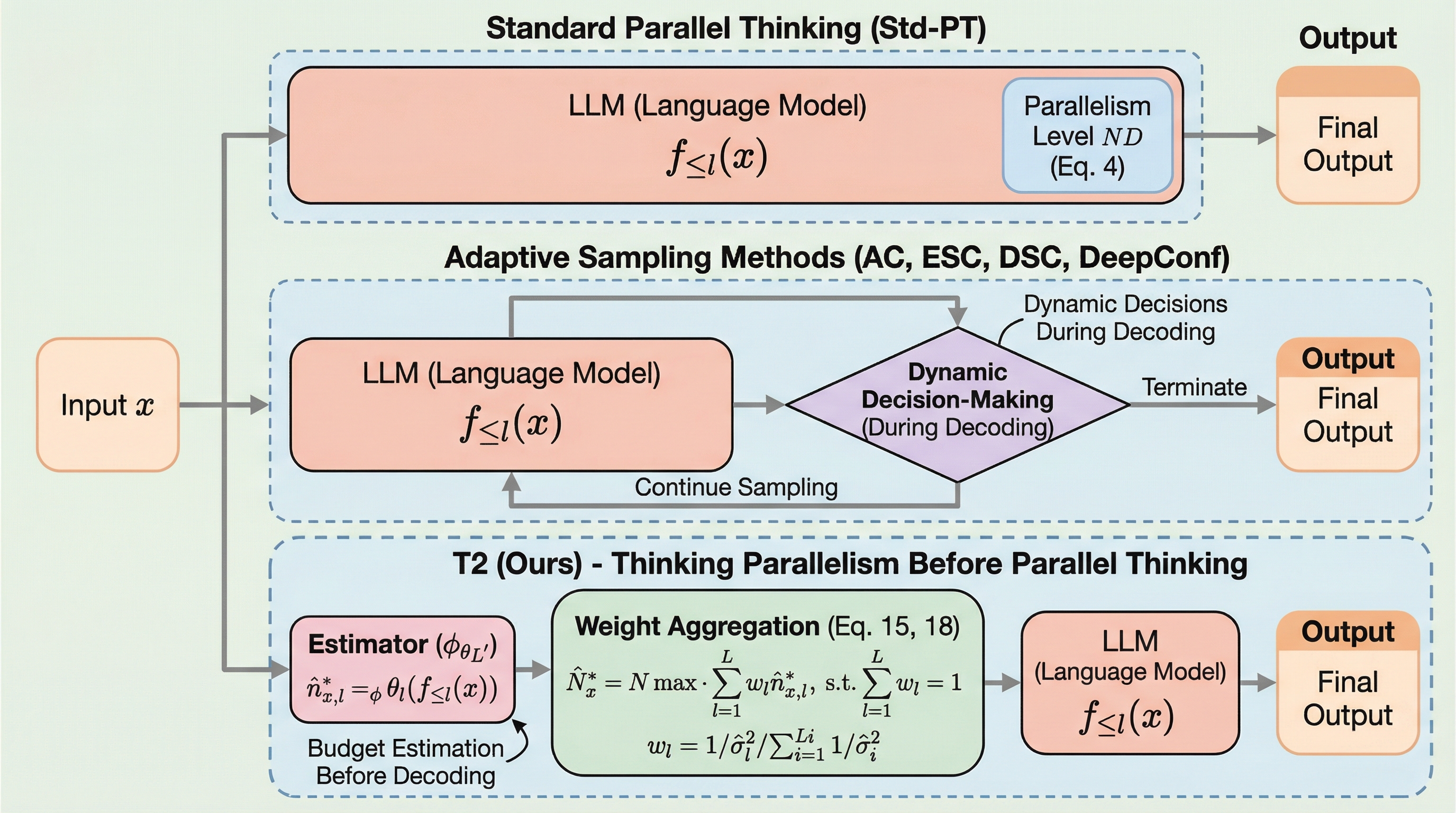
大規模言語モデル(LLM)の推論において、複数の推論パスを並列生成して多数決で統合する「並列思考」は有効ですが、全データに一律の大規模な並列数(予算)を割り当てると、多くのサンプルで計算資源が無駄になる「オーバースケーリングの呪い」が発生します。
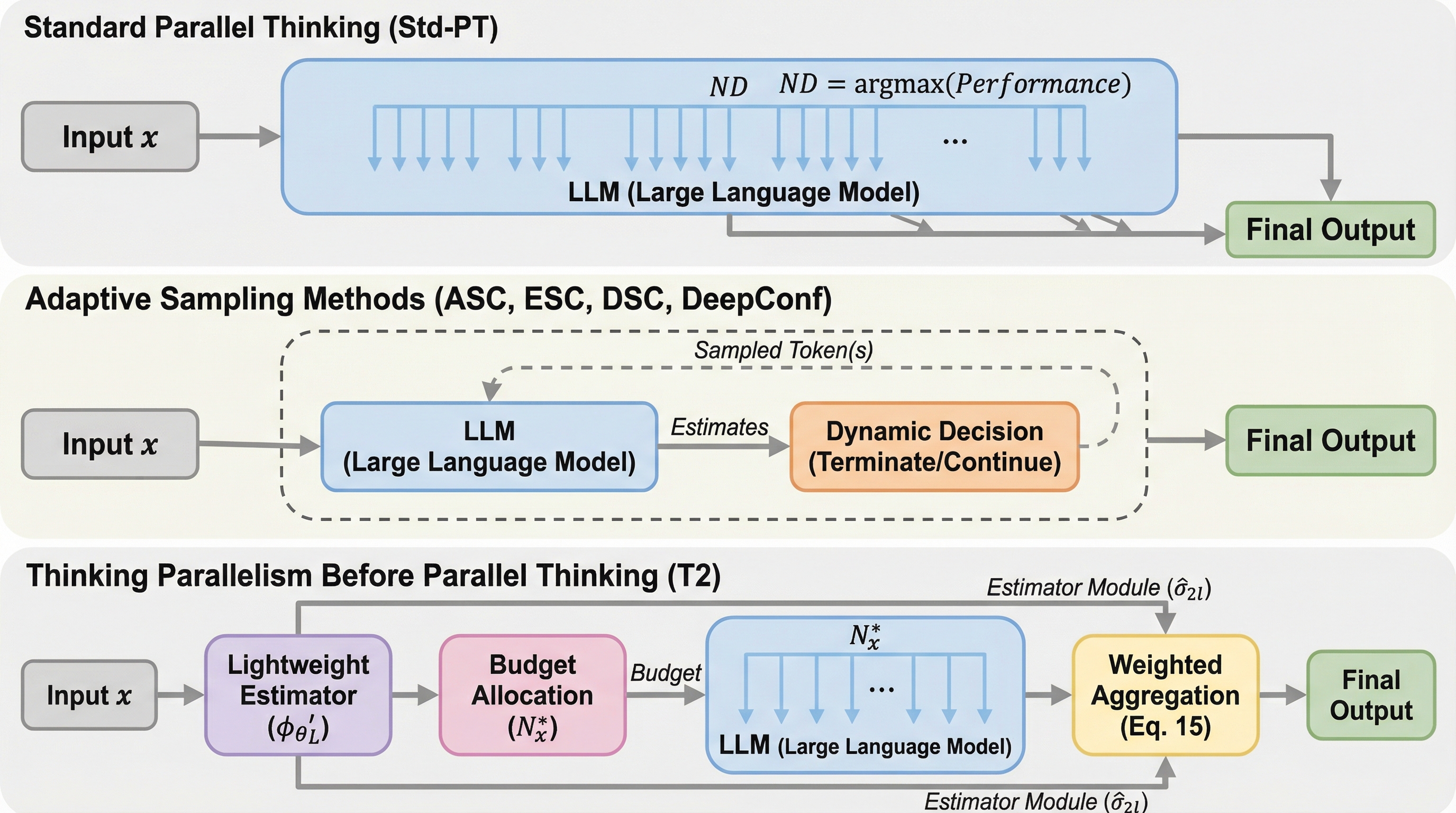
大規模言語モデルの推論において、複数の回答を生成して統合する「並列的思考」は精度を向上させますが、全問題に一律の大きな並列度を割り当てると、簡単な問題などで計算資源が無駄になる「オーバースケーリングの呪い」が発生することを明らかにしました。
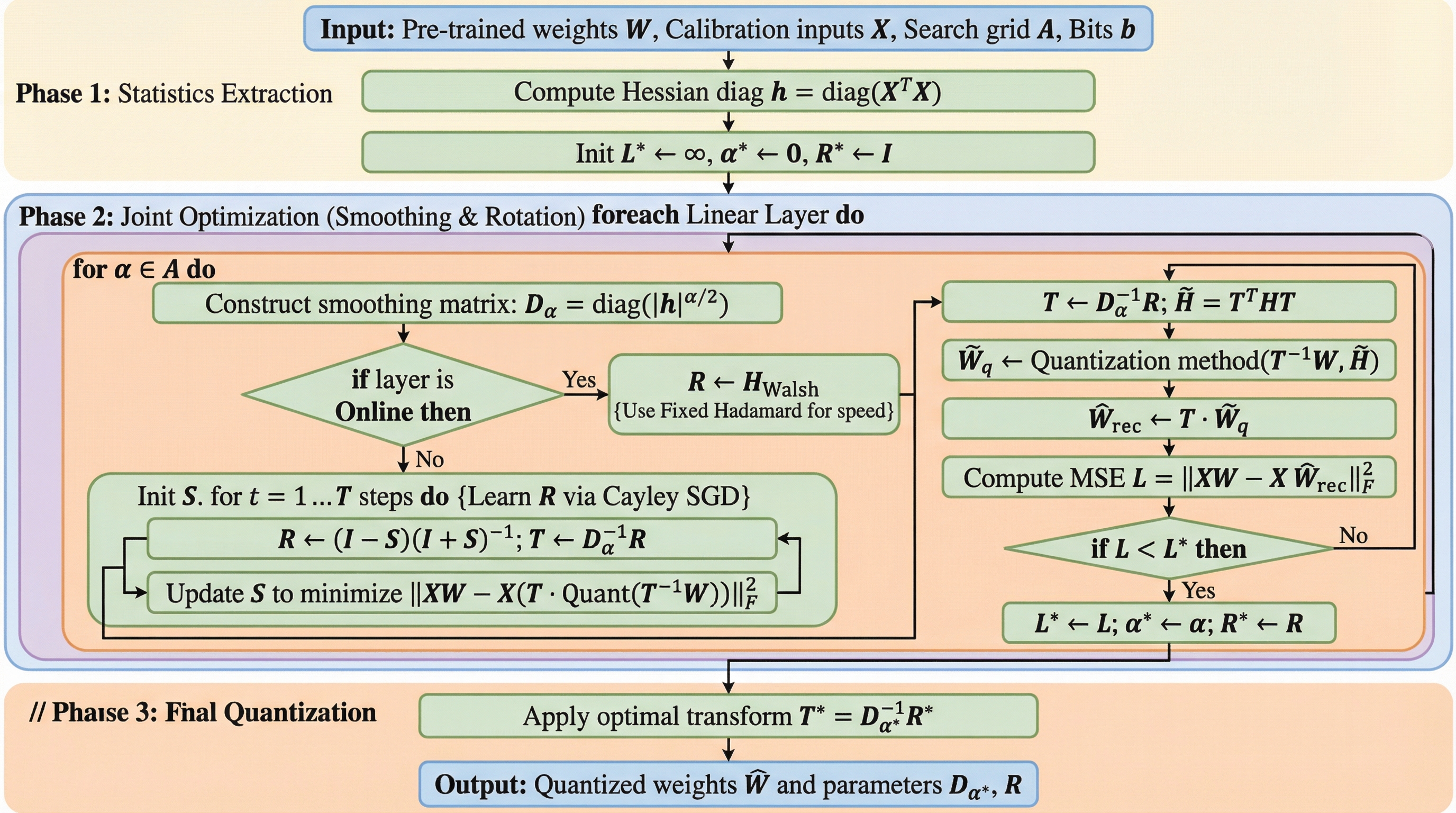
大規模言語モデル(LLM)の量子化において、重みの誤差が小さいにもかかわらず性能が急落する「低誤差・高損失」の矛盾を解決するため、損失曲面の幾何学的構造を改善する新フレームワーク「HeRo-Q」が提案されました。
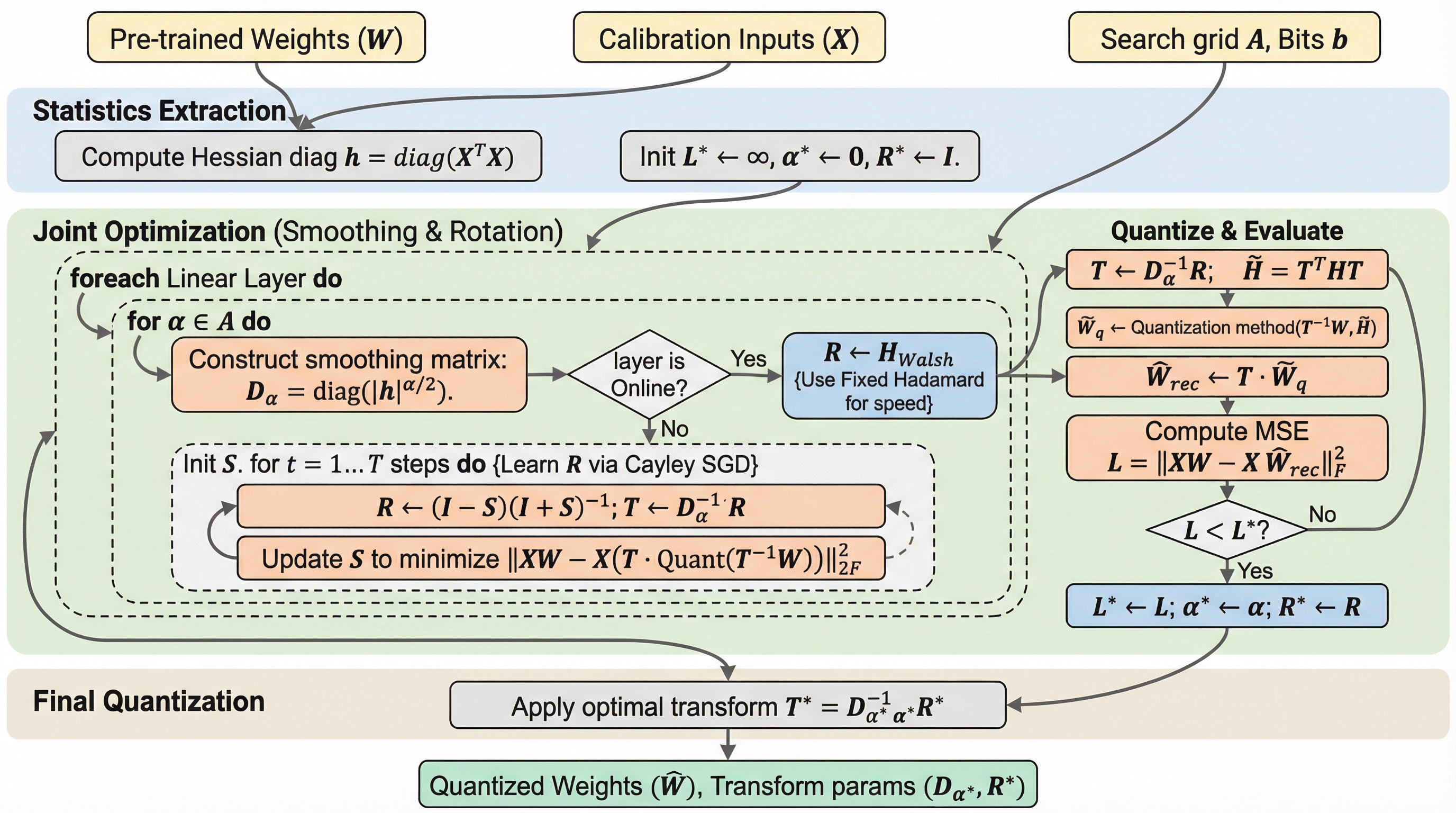
大規模言語モデルの量子化において、誤差は小さいのに性能が大幅に低下する「低誤差・高損失」の矛盾を解決するため、損失曲面の幾何学的構造であるヘッセ行列の曲率を調整する新しいフレームワーク「HeRo-Q」が提案されました。
従来の時系列予測向け混合エキスパート(MoE)モデルは、各時間ステップを独立して処理するトークン単位のルーティングを採用していたが、データの連続性や局所的な構造を十分に活用できていないという課題があった。
時系列予測におけるTransformerモデルのスケーリングと長期的な動態把握の課題に対し、従来のトークン単位ではなく、連続するタイムステップを一つのセグメントとしてルーティングする新しい疎な混合専門家(MoE)アーキテクチャ「Seg-MoE」を提案している。
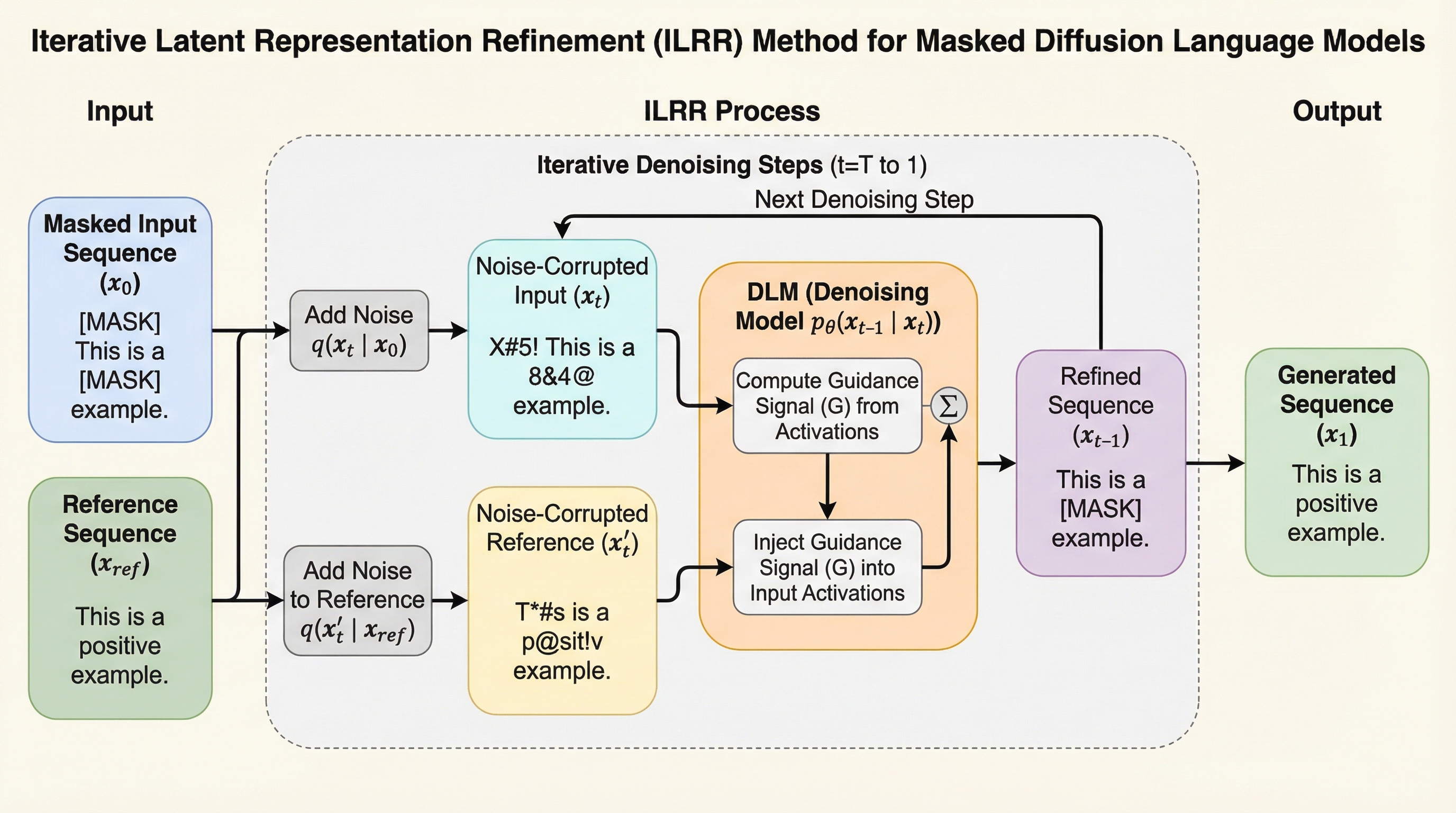
離散拡散言語モデル(DLM)の生成プロセスを推論時に制御するための、学習を必要としない新しいフレームワーク「反復的潜在表現洗練(ILRR)」が提案されました。この手法は、生成中のシーケンスの内部活性化状態を、単一の参照シーケンスの活性化状態と動的に位置合わせすることで、特定の属性やスタイルを効果的に転送します。
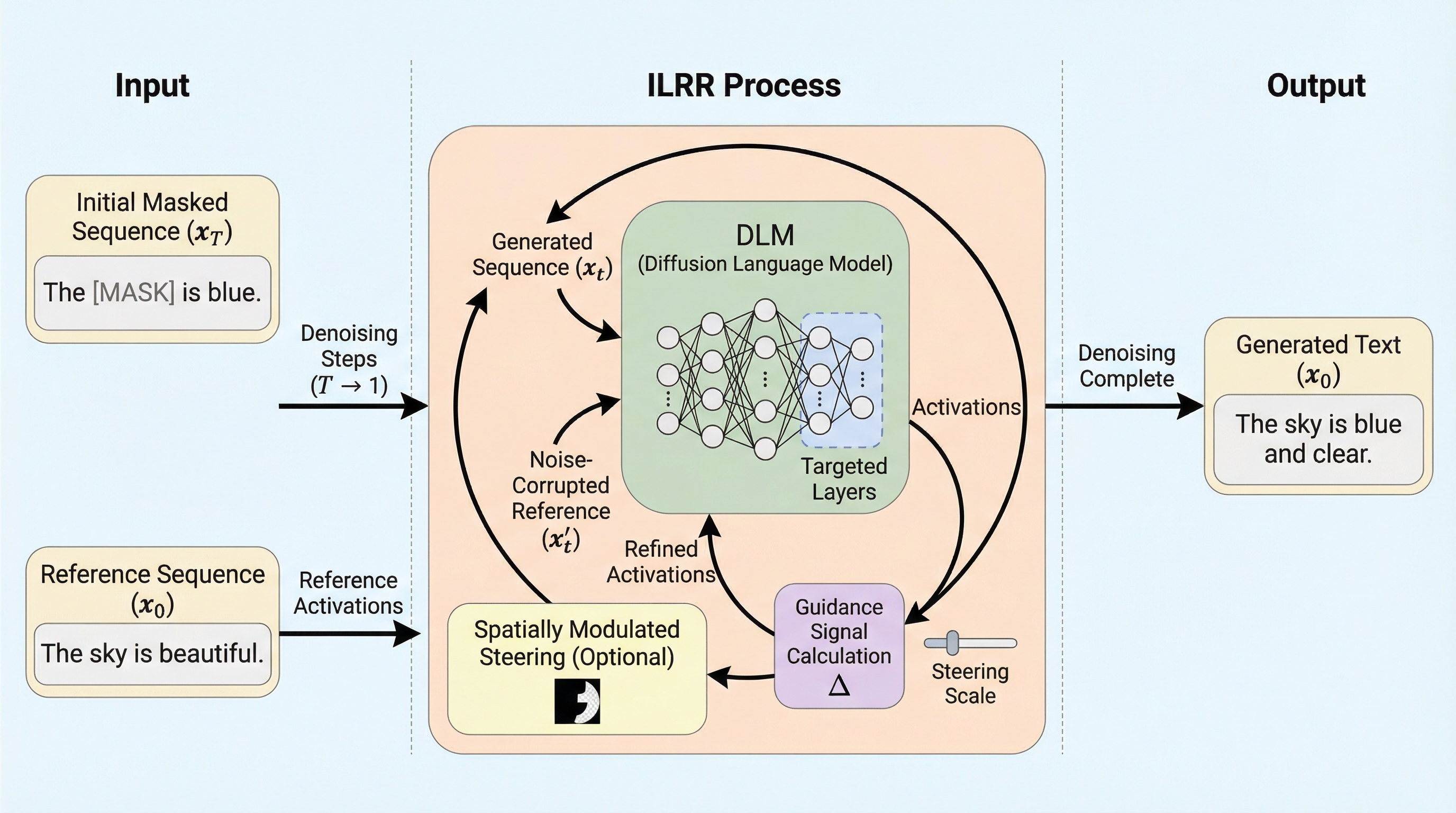
離散拡散言語モデル(DLM)の生成を制御するため、追加の学習や微調整を一切必要とせず、単一の参照シーケンスを用いてモデル内部の活性化状態を動的に調整する「反復的潜在表現洗練(ILRR)」という新しいフレームワークが提案されました。
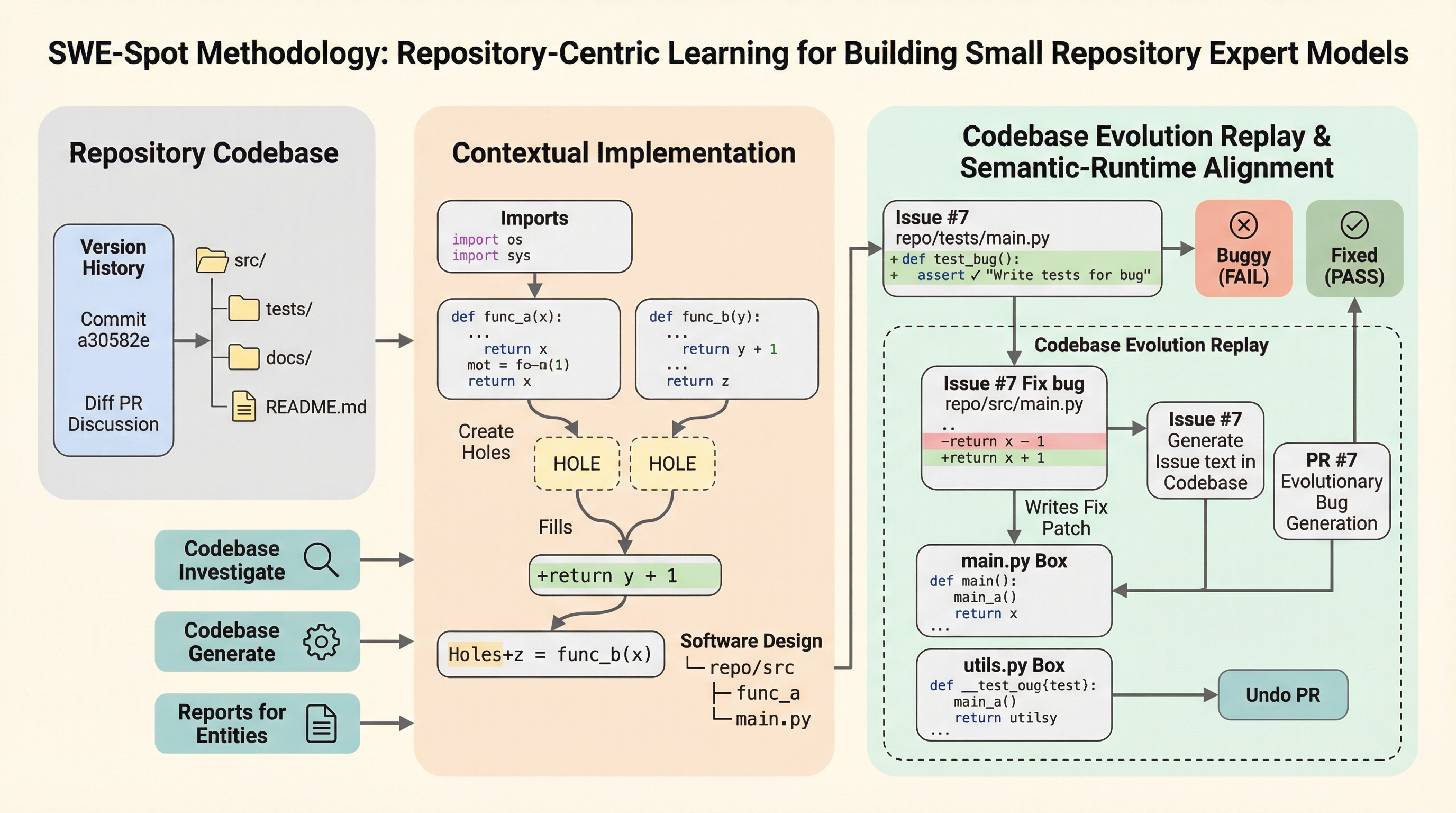
従来のタスク中心学習では、小規模言語モデルが複雑なコードベースの推論時に十分な汎化性能を発揮できず、表面的なパターンの学習に留まるという課題がありました。 本研究は、特定のコードベースに対する垂直的な深さを優先する「リポジトリ中心学習(RCL)」を提案し、静的なコードを対話的な学習信号に変換する4つの経験ユニットを設計しました。 この手法で構築された4BパラメータのSWE-SPOTは、8倍大きなオープンモデルや商用モデルに匹敵する性能を、高いサンプル効率と低い推論コストで実現することに成功しました。