意味的内容がアルゴリズムの性能を決定する
大規模言語モデル(LLM)は、本来なら入力の意味に左右されないはずの計数のようなアルゴリズム的タスクにおいて、対象が「都市名」か「化学物質名」かといった意味的内容(セマンティック・クラス)によって正解率が40%以上も変動するという重大な脆弱性を持っていることが明らかになった。
TL;DR(結論)
大規模言語モデル(LLM)は、本来なら入力の意味に左右されないはずの計数のようなアルゴリズム的タスクにおいて、対象が「都市名」か「化学物質名」かといった意味的内容(セマンティック・クラス)によって正解率が40%以上も変動するという重大な脆弱性を持っていることが明らかになった。 この現象は、モデルが厳密なアルゴリズムを内部で実行しているのではなく、学習データの統計的パターンに基づいた近似的な処理を行っているために発生しており、トークン数や区切り文字の形式といった表面的な要因を制御しても解消されないことが、新たなベンチマーク「WhatCounts」を用いた厳密な検証によって証明された。 この「セマンティック・ギャップ」は、モデルの推論能力を高めたり特定のツールを利用させたりしても完全には排除できず、さらに無関係なデータによる微調整で予測不能に変化するため、LLMを複雑なシステムやエージェントの構成要素として利用する際の信頼性に深刻な懸念を投げかけている。
なぜこの問題か
アルゴリズムの定義とは、入力の構造に基づいて動作し、その引数が持つ具体的な意味には依存しないことである。例えば、10個の項目を数えるという操作は、対象が都市名であっても、化学物質の名前であっても、あるいは絵文字であっても、全く同じ手順で実行され、同じ結果を導き出すべきである。この「不変性」こそが、アルゴリズムをアルゴリズムたらしめる本質的な特性である。しかし、近年の大規模言語モデル(LLM)は、計数、ソート、検索、抽出といったアルゴリズム的な操作を実行できるかのように見え、多くの開発者がこれらを「プロンプト・プログラミング」の部品として利用している。もしLLMが真にアルゴリズムを実装しているならば、そのエラーはコンテキストの長さ制限といった一般的な制約に由来するはずであり、数える対象の意味によってエラーが体系的に変化することはないはずである。 しかし、もしエラーが意味的内容に依存して変動するのであれば、そのモデルはアルゴリズムを実行しているのではなく、単にパターンマッチングによってアルゴリズムを近似しているに過ぎないことになる。この問題は、LLMが生産システムやエージェントのパイプラインに組み込まれる際に極めて重要となる。…
核心:何を提案したのか
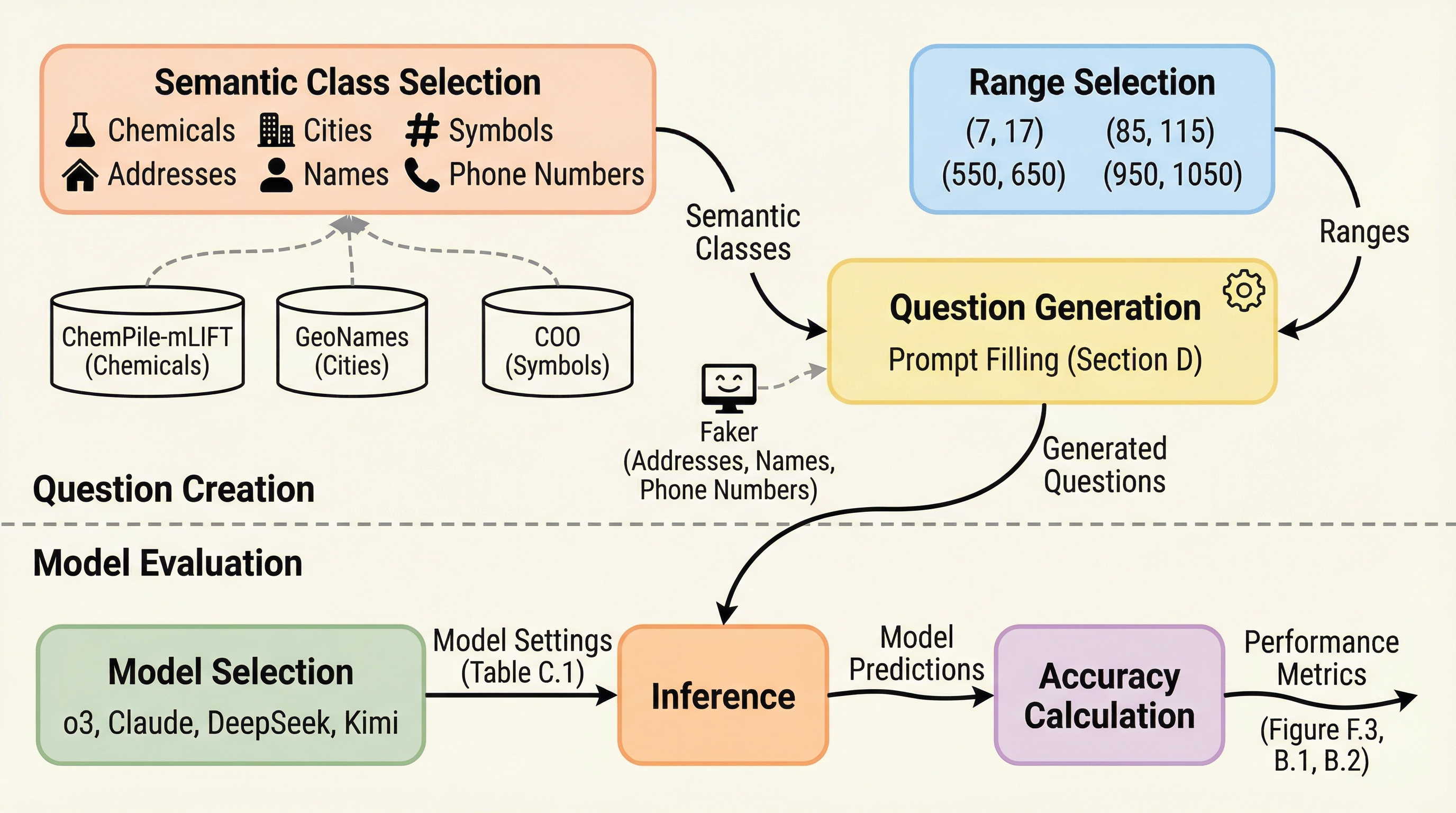
本研究では、LLMがアルゴリズムを実行する際に「セマンティックな不変性」を保てているかを孤立させて検証するために、新たなアトミックなベンチマーク「WhatCounts」を導入した。このベンチマークは、重複や紛らわしい項目を含まず、明確な区切り文字で区切られたリスト内の項目を数えるという、極めて単純かつ純粋なタスクで構成されている。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related