ベンガル語のヘイトスピーチ検出を強化する大規模データセット「BengaliSent140」の登場
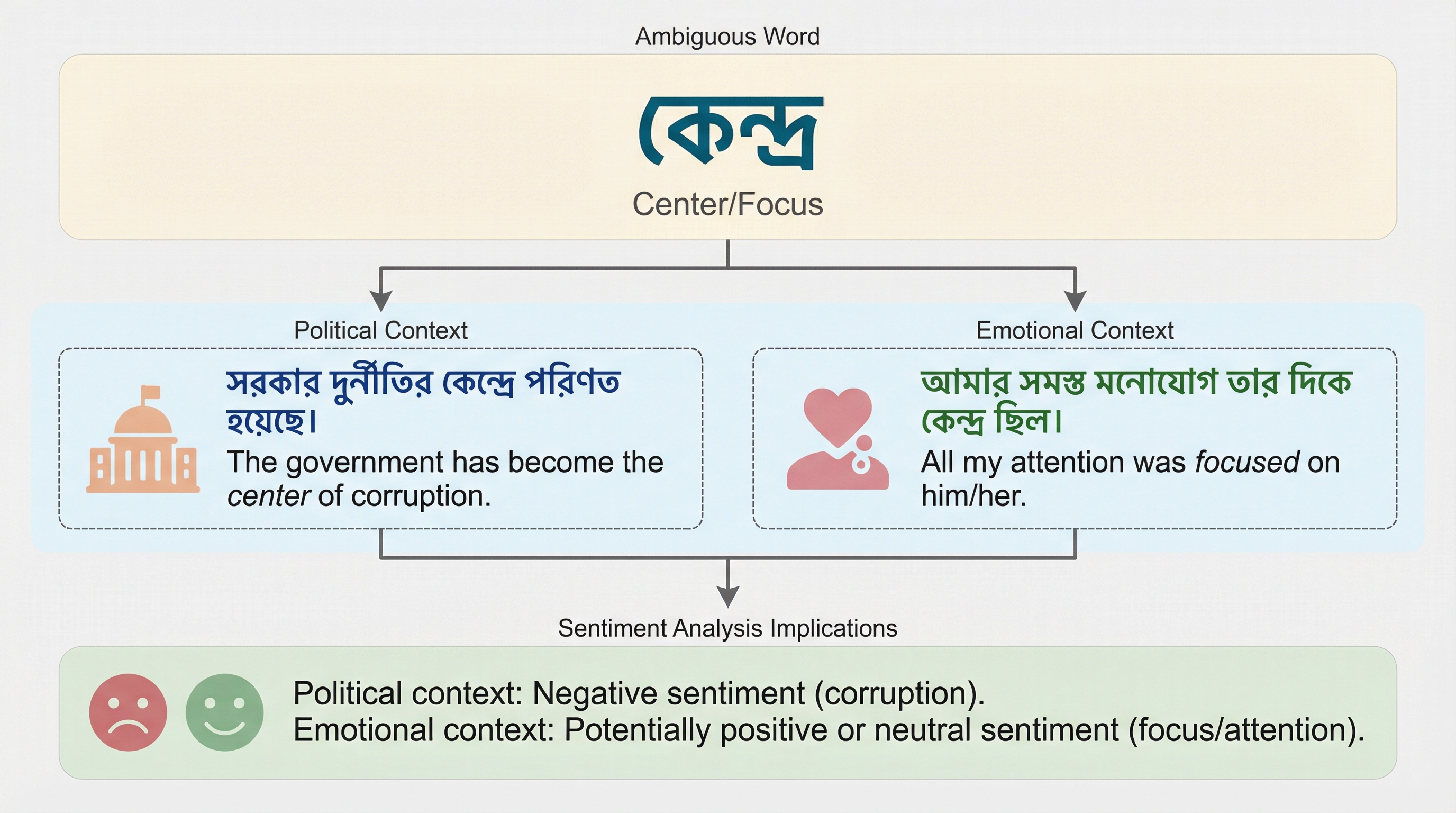
ベンガル語の感情分析とヘイトスピーチ検出において、既存のデータセットは規模が小さくドメインが限定的であるという課題を解決するため、7つの公開リソースを統合し、139,792件のユニークなテキストを含む大規模な二値分類データセット「BengaliSent140」を構築しました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
ベンガル語の感情分析とヘイトスピーチ検出において、既存のデータセットは規模が小さくドメインが限定的であるという課題を解決するため、7つの公開リソースを統合し、139,792件のユニークなテキストを含む大規模な二値分類データセット「BengaliSent140」を構築しました。
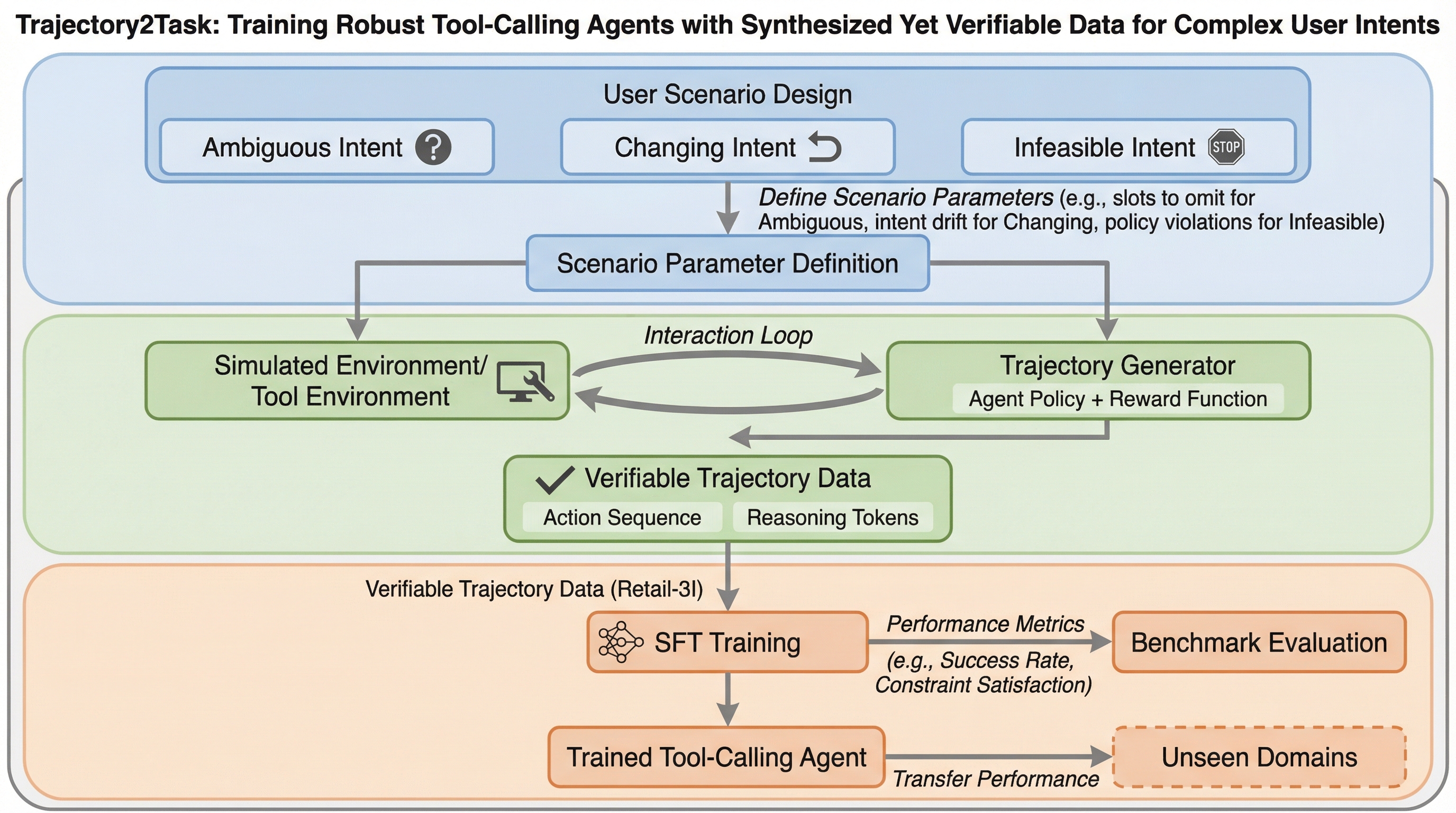
現実世界のツール利用エージェントが直面する「曖昧な意図」「変化する意図」「実行不可能な意図」という3つの複雑なシナリオに対処するため、検証可能なデータ生成パイプラインであるTrajectory2Taskが開発されました。
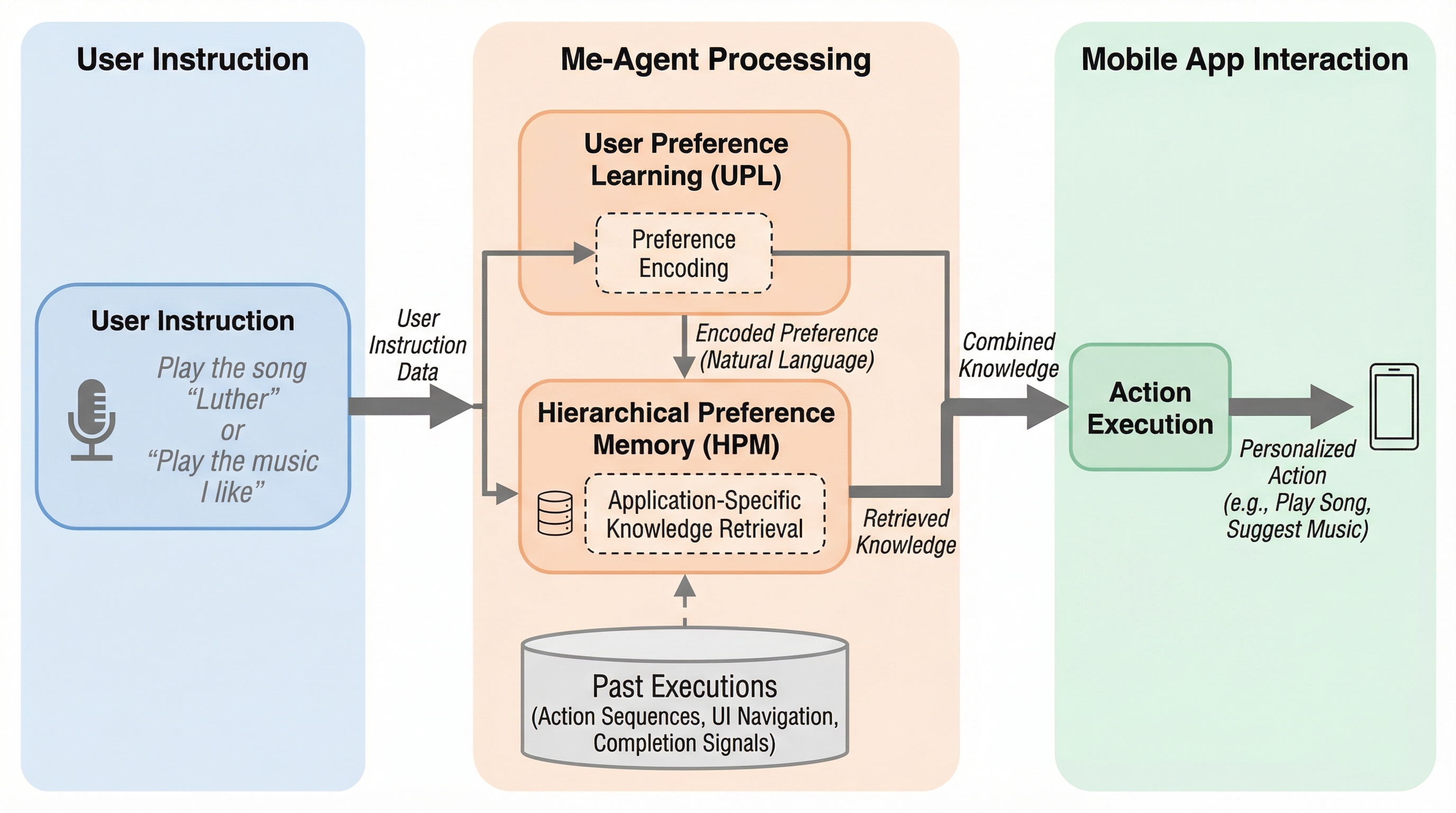
Me-Agentは、大規模言語モデル(LLM)を基盤としたモバイルエージェントにおいて、追加のモデル訓練を行うことなく、ユーザーの過去の行動履歴や潜在的な好みを学習してパーソナライズされた操作を実現する新しいフレームワークである。
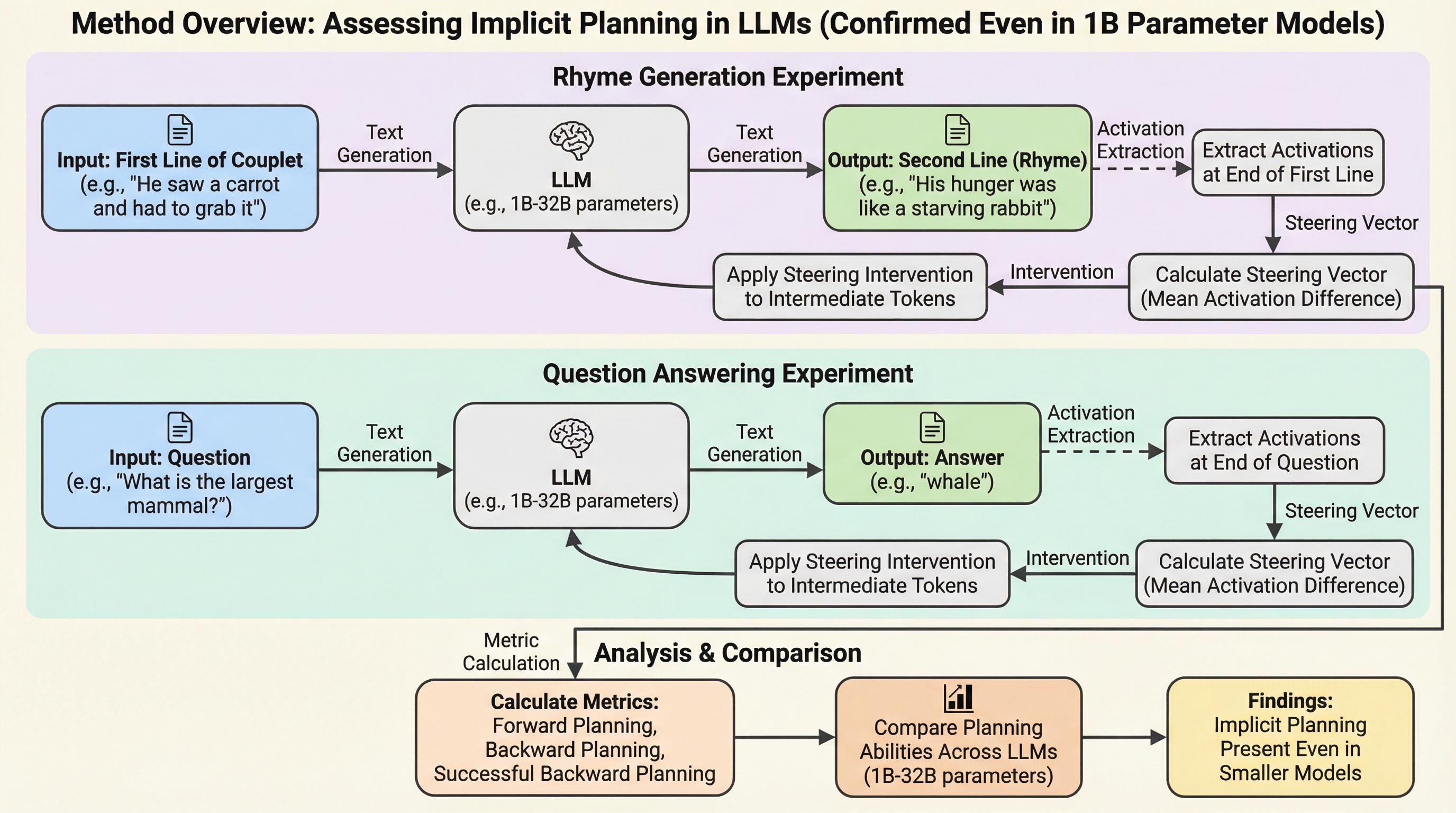
大規模言語モデルは、単に次の単語を予測するだけでなく、将来出力すべき内容を事前に準備する「暗黙的計画」の能力を備えていることが明らかになりました。 本研究では、モデルの内部状態を操作する簡便な手法を用いることで、10億パラメータ程度の比較的小規模なモデルにおいても、この計画能力が普遍的に存在することを定量的に実証しました。 この手法により、特定の韻を踏む際や質問に回答する際に、数トークン手前の段階で冠詞や中間表現を動的に調整しているメカニズムが解明され、AIの安全性と制御の理解に新たな道を開きました。
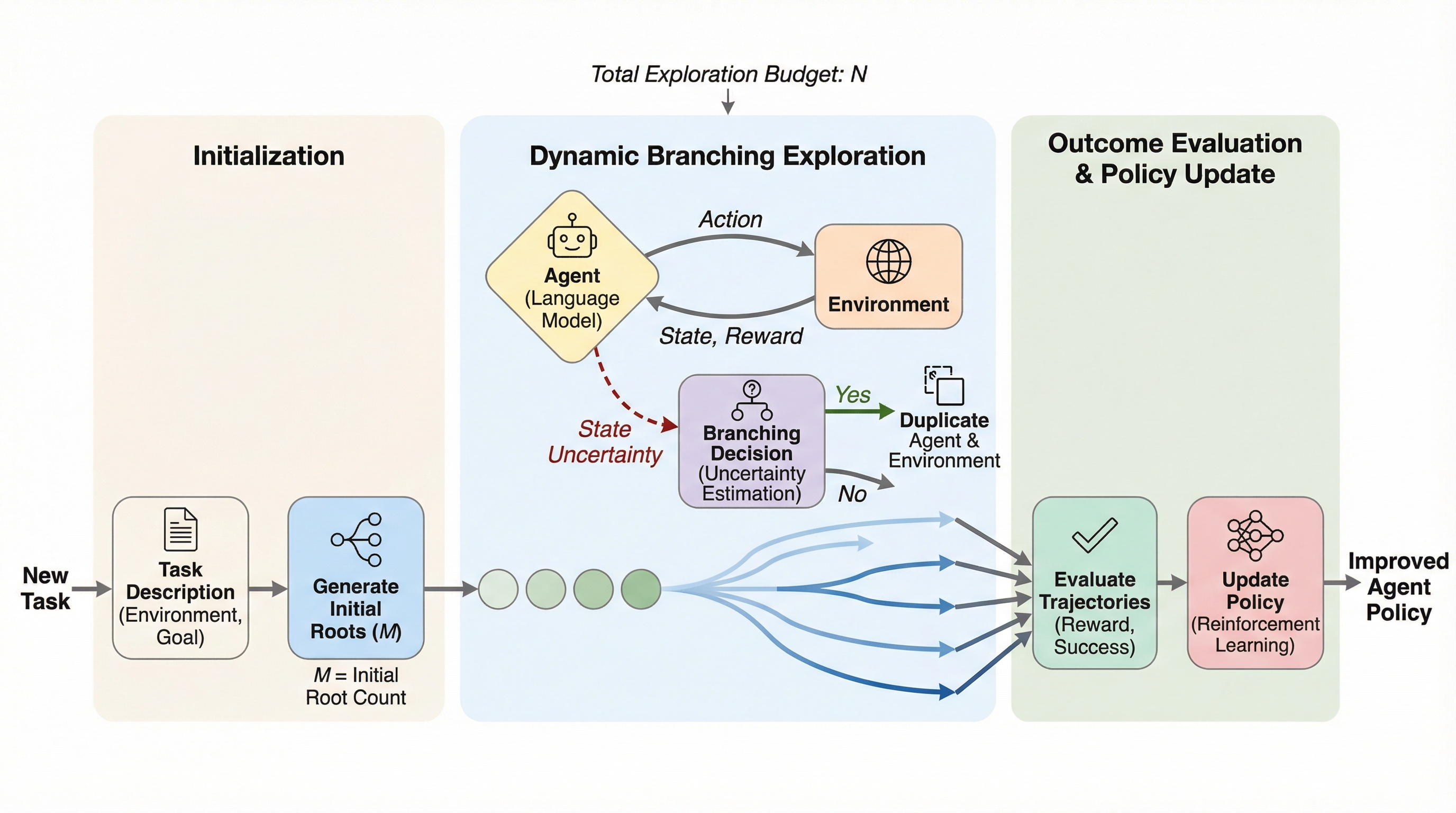
長期的なタスクを実行するAIエージェントの強化学習において、全ステップに一律の計算資源を配分する従来手法の非効率性を解消するため、重要な決定局面でのみ探索を分岐させる新フレームワーク「SPARK」が提案されました。
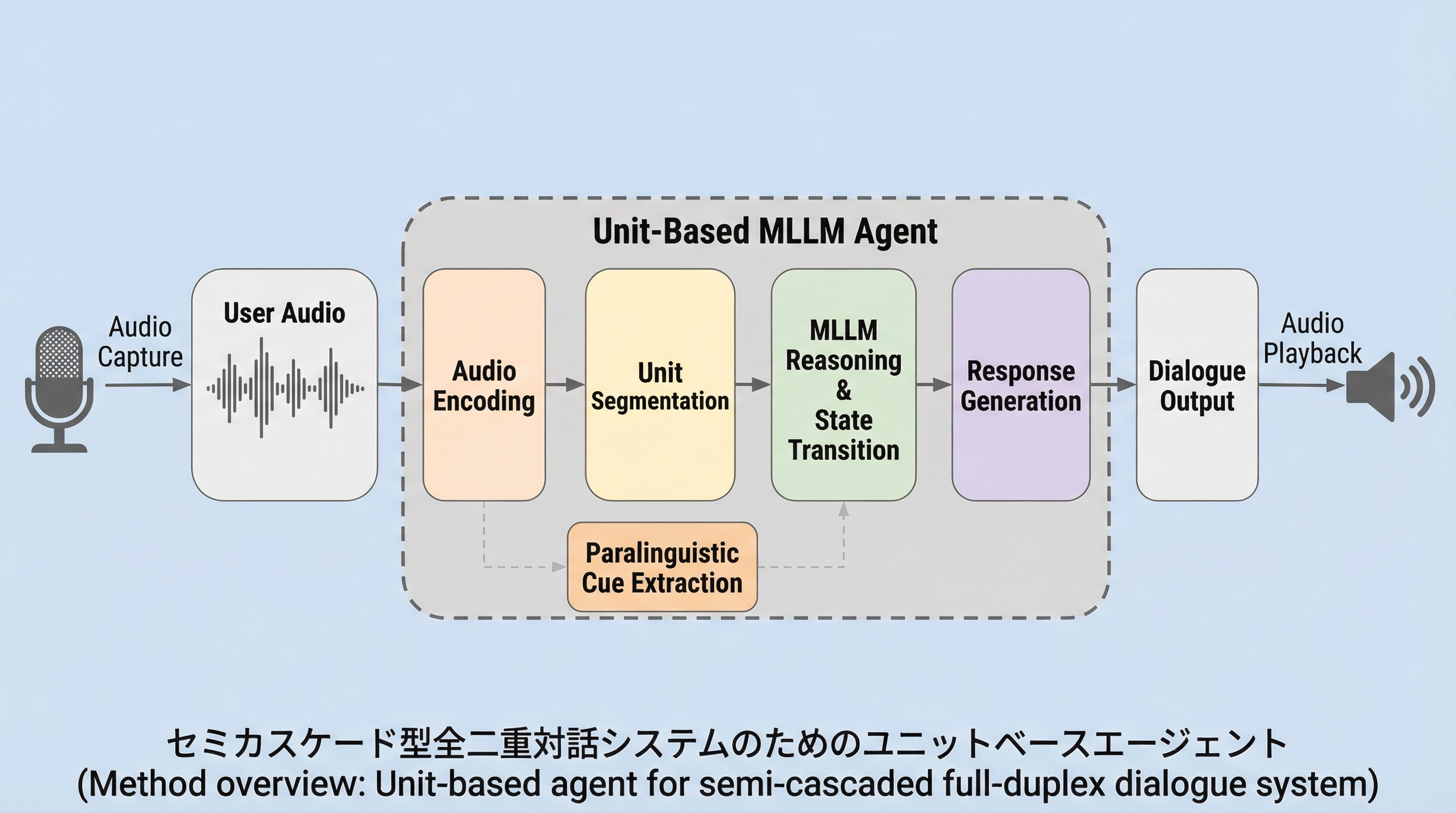
複雑な対話を「会話ユニット」という最小単位に分解し、マルチモーダル大規模言語モデル(MLLM)が「継続」か「切り替え」かを判断することで、人間のように自然な全二重音声対話を可能にする新しいフレームワークを提案した。
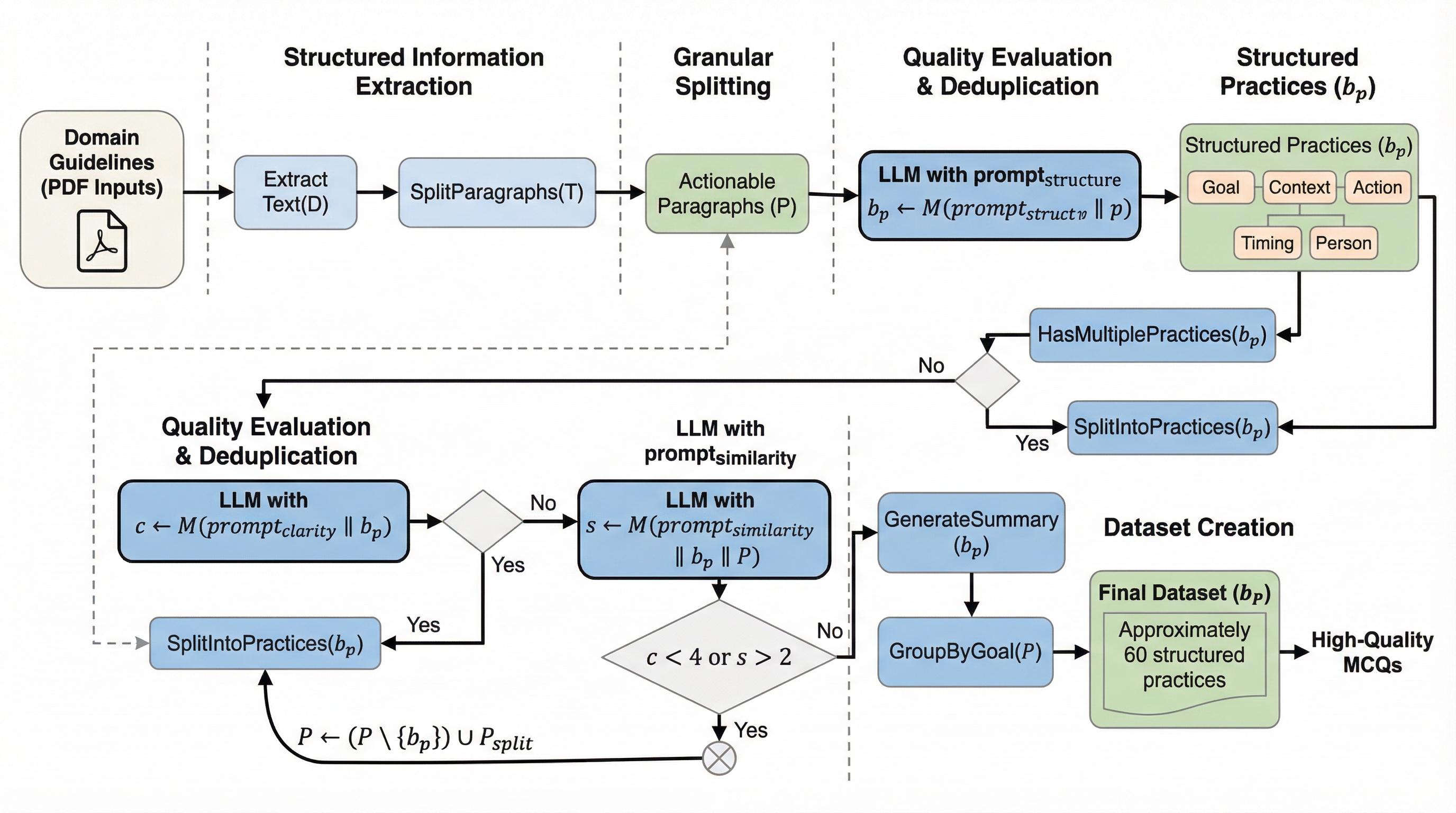
本研究は、専門家のガイドラインからブルームの分類学に基づいた評価問題を自動生成するフレームワーク「BLOOMQA」を開発し、既存の試験データに依存しない新しい評価手法を確立しました。教育、栄養学、介護の3つの実務ドメインにおいて、指針への違反を題材とした多肢選択式問題と対話データを合計約6万件生成し、大規模言語モデル(LLM)の推論能力を多角的な認知レベルで測定可能にしました。検証の結果、LLMは「分析」のような高次の推論で高い性能を示す一方で、「記憶」のような基礎的な項目で失敗するという、人間の学習プロセスとは異なる非直感的な挙動を示すことが明らかになりました。
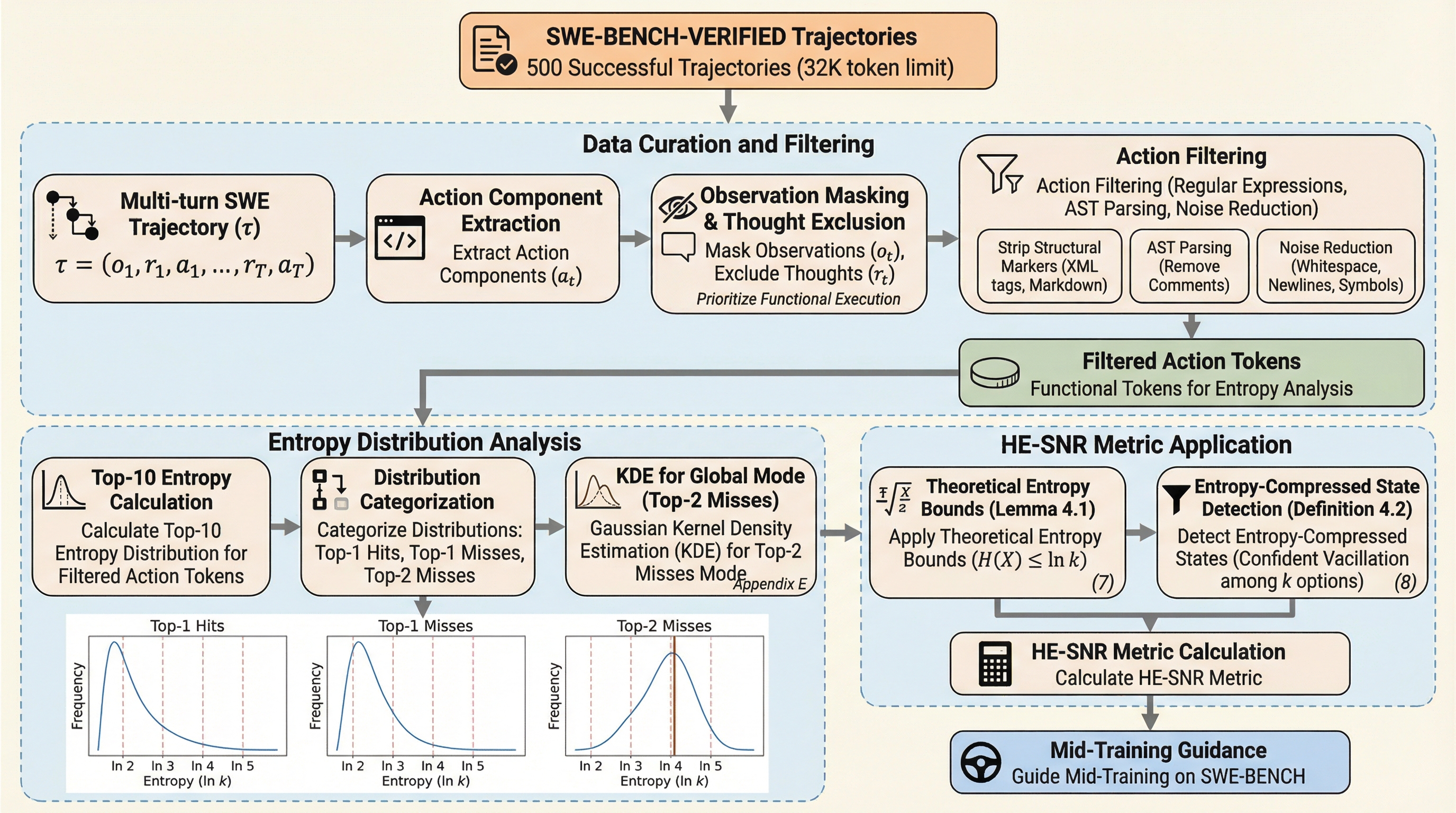
ソフトウェアエンジニアリング能力を評価する最難関ベンチマークであるSWE-benchにおいて、モデルの中間学習(Mid-Training)段階での潜在能力を正確に測定するための新しい指標として、エントロピー圧縮仮説に基づく「HE-SNR(高エントロピー信号対雑音比)」が提案されました。
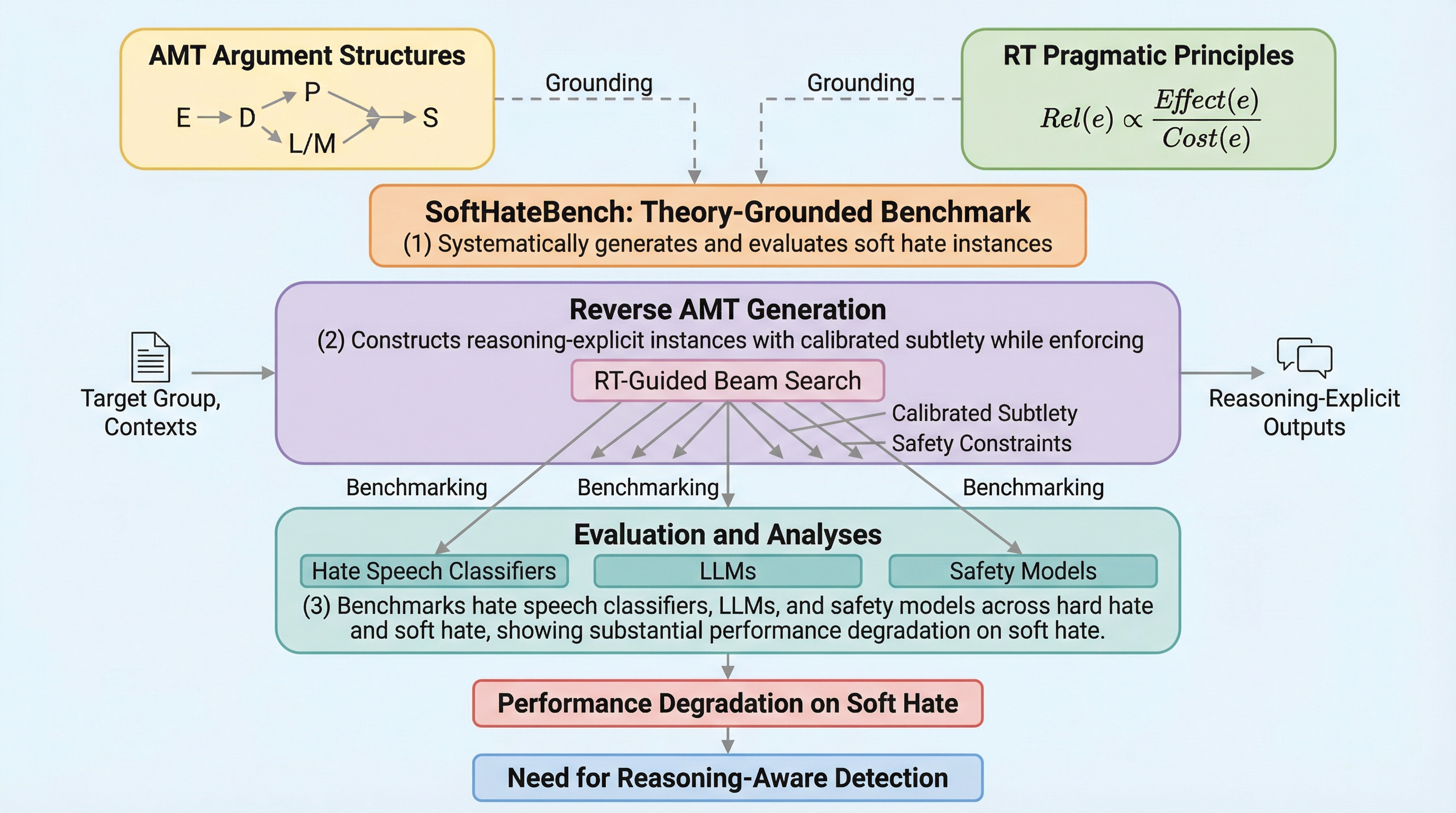
従来のコンテンツモデレーションは、露骨な罵倒や脅迫を含む「ハードなヘイトスピーチ」の検出には長けていますが、表面上は理性的で規約に違反しないように装いつつ、論理的な推論を通じて特定の集団を排除しようとする「ソフトなヘイトスピーチ」を見逃す傾向にあります。
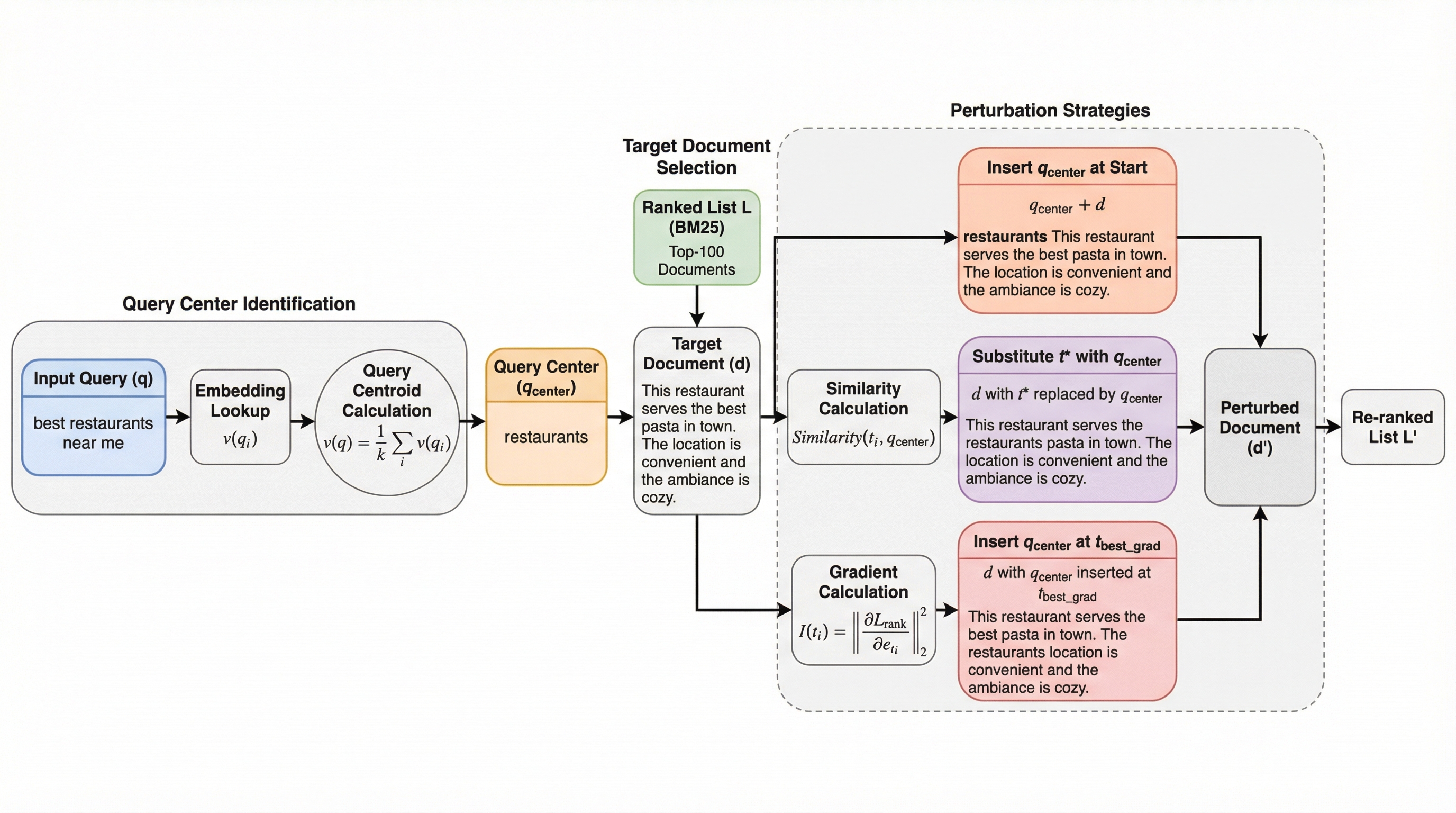
ニューラルランキングモデル(NRM)は、クエリに関連する特定の1単語を挿入または置換するだけで、検索順位を大幅に操作される脆弱性があることが明らかになりました。 本研究では「クエリセンター」という概念を導入し、ヒューリスティックな手法や勾配を用いた手法によって、わずか1トークンの変更で最大91%の攻撃成功率を達成しています。 特に検索順位の中間に位置する文書が最も攻撃に対して脆弱である「ゴルディロックス・ゾーン」の存在が確認され、既存のランキングモデルの堅牢性に重大な課題を投げかけています。