セミカスケード型全二重対話システムのためのユニットベースエージェント
複雑な対話を「会話ユニット」という最小単位に分解し、マルチモーダル大規模言語モデル(MLLM)が「継続」か「切り替え」かを判断することで、人間のように自然な全二重音声対話を可能にする新しいフレームワークを提案した。
TL;DR(結論)
複雑な対話を「会話ユニット」という最小単位に分解し、マルチモーダル大規模言語モデル(MLLM)が「継続」か「切り替え」かを判断することで、人間のように自然な全二重音声対話を可能にする新しいフレームワークを提案した。音声活動検知(VAD)や話者照合(SV)、非同期の自動音声認識(ASR)を組み合わせたセミカスケード構成を採用しており、追加の学習を必要としない「トレインフリー」かつ既存のコンポーネントを自由に統合できる「プラグアンドプレイ」な特性を持つ。HumDialデータセットを用いた検証では、従来のシステムと比較して応答遅延を大幅に短縮し、割り込みや相槌への適切な対応を実現したことで、Humanlike Spoken Dialogue Systems Challengeの全二重対話トラックにおいて第2位の成績を収めた。
なぜこの問題か
現実世界における音声対話は、人間同士のような流暢さを実現するために依然として多くの課題を抱えている。特に、ユーザーとマシンが交互にしか話せない従来の「半二重(half-duplex)」方式は、自然なコミュニケーションを阻害する大きな要因となっている。これに対し、双方向が同時に発話可能な「全二重(full-duplex)」方式は、より人間らしい対話を実現するための重要なパラダイムである。全二重対話を実現するための既存のアプローチには、大きく分けてエンドツーエンドモデルとカスケード型パイプラインの二つが存在する。エンドツーエンドモデルは、ユーザーとエージェントの音声を一括で処理するため、感情や韻律といった非言語的な音響情報を保持しやすいという利点があるが、一方で膨大な学習データと計算資源を必要とする。 対照的に、音声合成(TTS)、自動音声認識(ASR)、大規模言語モデル(LLM)などを組み合わせるカスケード型パイプラインは、既存の技術を統合しやすく、制御も容易であるため実用性が高い。しかし、多段階の処理を経ることで音響情報が失われやすく、各モジュールの処理待ちによって応答の遅延が増大するという欠点がある。…
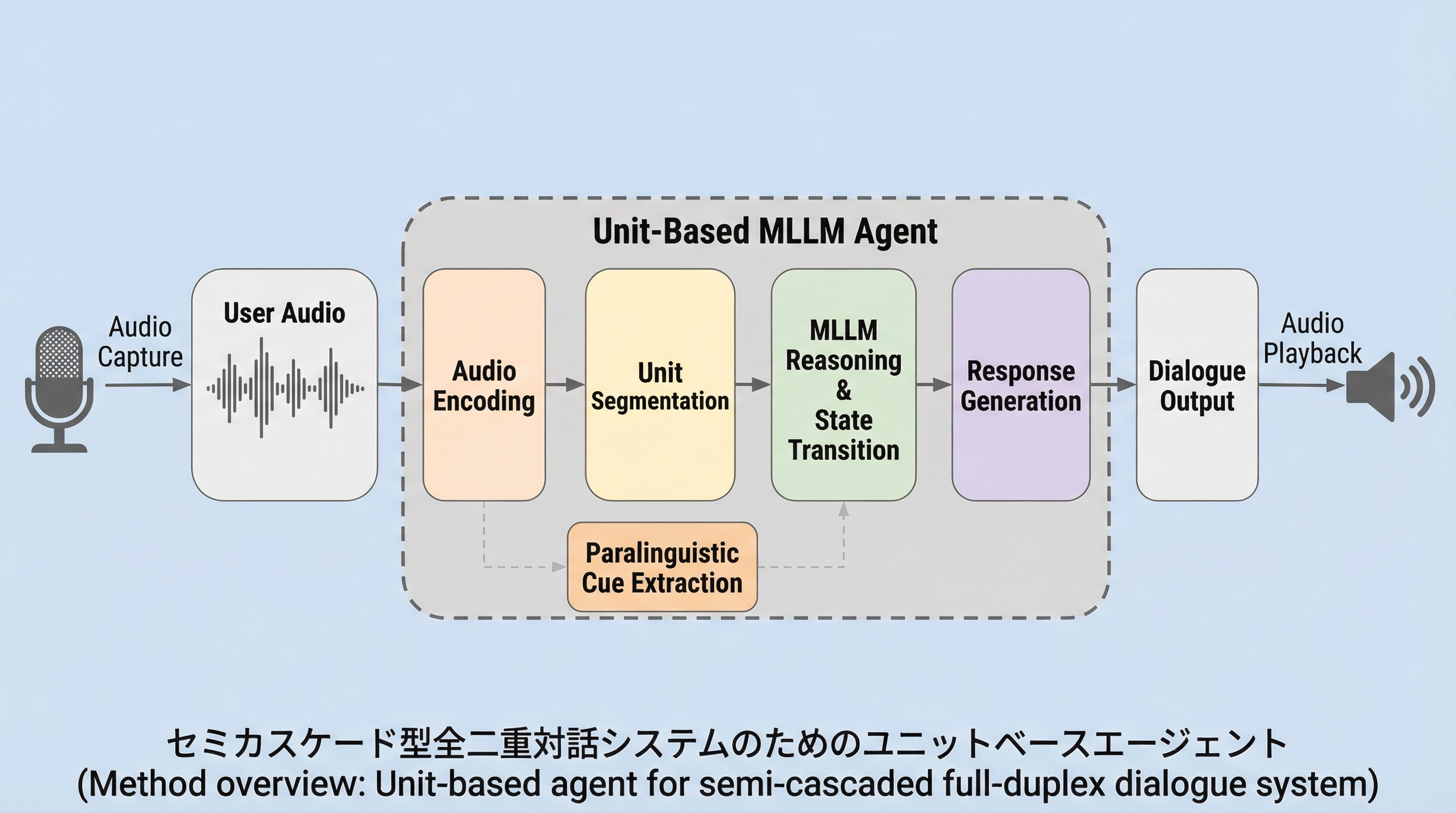
核心:何を提案したのか
本研究の核心は、複雑な対話の流れを「会話ユニット」と呼ばれる最小の構成単位に分解し、各ユニット内での状態遷移を管理するユニットベースのフレームワークを提案したことにある。このフレームワークでは、対話を「聞く(listen)」と「話す(speak)」という二つの状態を持つユニットの連続として定義している。システムは常に「聞く」状態から新しいユニットを開始し、内部のMLLMが「継続(continue)」または「切り替え(switch)」という二つのアクションのいずれかを選択することで、動的に状態を制御する。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related