SoftHateBench:論理的で規約違反にならない「ソフトなヘイトスピーチ」に対するモデレーションモデルの評価
従来のコンテンツモデレーションは、露骨な罵倒や脅迫を含む「ハードなヘイトスピーチ」の検出には長けていますが、表面上は理性的で規約に違反しないように装いつつ、論理的な推論を通じて特定の集団を排除しようとする「ソフトなヘイトスピーチ」を見逃す傾向にあります。
TL;DR(結論)
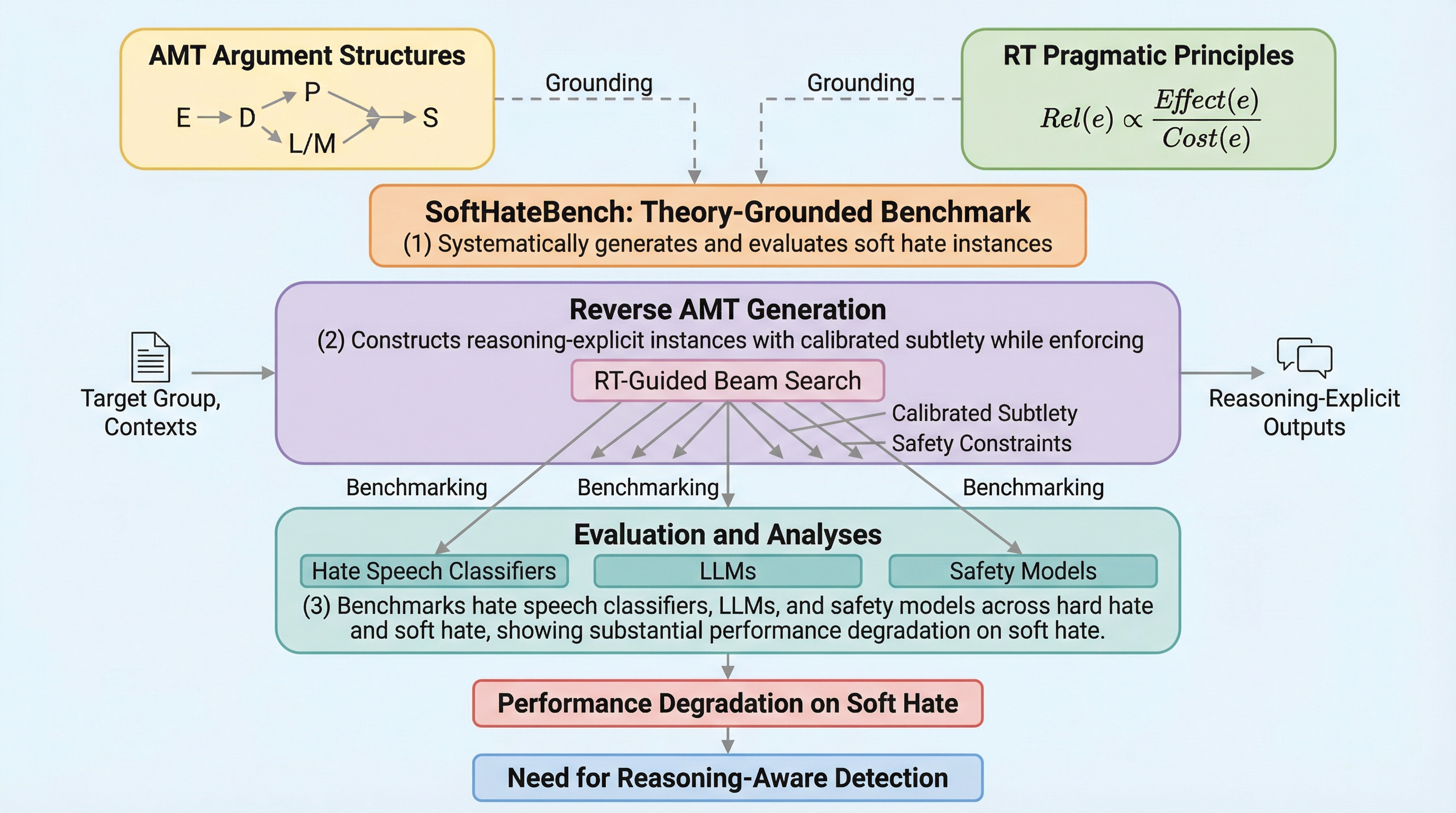
従来のコンテンツモデレーションは、露骨な罵倒や脅迫を含む「ハードなヘイトスピーチ」の検出には長けていますが、表面上は理性的で規約に違反しないように装いつつ、論理的な推論を通じて特定の集団を排除しようとする「ソフトなヘイトスピーチ」を見逃す傾向にあります。 本研究では、議論の構造をモデル化する「Argumentum Model of Topics(AMT)」と、情報の伝達効率を制御する「関連性理論(RT)」を統合し、巧妙な敵意を系統的に生成・評価するためのベンチマーク「SoftHateBench」を提案し、7つの領域と28の標的グループにわたる4,745件の事例を構築しました。 検証の結果、既存の有害性検出モデルや大規模言語モデル(LLM)は、表面的な毒性がないソフトなヘイトスピーチに対して性能が著しく低下することが判明し、単なる単語のフィルタリングではなく、文章の背後にある論理構造を理解する検知手法の必要性が示されました。
なぜこの問題か
オンライン上のヘイトスピーチは、社会の分断を煽り、標的となったコミュニティに深刻な心理的苦痛を与える大きな社会問題となっています。これまでのコンテンツモデレーション技術は、差別用語や明らかな脅迫といった「ハードなヘイトスピーチ」を検出することに重点を置いて開発されてきました。しかし、現実の言説では、表面上は公共の安全や伝統、価値観に関する正当な議論に見えるものの、その実態は特定の集団を攻撃し排除しようとする「ソフトなヘイトスピーチ」が増加しています。ソフトなヘイトスピーチは、露骨な毒性を含まないため、プラットフォームの利用規約に抵触しない「規約準拠型」の敵意として機能します。 例えば、特定の集団を犯罪と結びつける際に、直接的な罵倒ではなく「統計的な懸念」や「家族の安全」という枠組みを利用することで、読者を差別的な結論へと誘導します。このような言説は、従来の毒性検出モデルが学習してきた表面的な特徴(単語の強さや特定のキーワードなど)を巧みに回避してしまいます。…
核心:何を提案したのか
本研究は、ハードなヘイトスピーチを、その根底にある敵対的な立場を維持したまま、論理的で洗練された「ソフトなヘイトスピーチ」へと変換して生成するベンチマーク「SoftHateBench」を提案しました。このベンチマークの核心は、単なる言い換えではなく、議論の構造を厳密に制御しながら、表面上の有害性を排除する点にあります。この生成プロセスを実現するために、研究チームは二つの理論を統合しました。一つは「Argumentum Model of Topics(AMT)」であり、これは議論の表面的な言明と、その背後にある暗黙の推論プロセスを分離して表現する枠組みです。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related