大規模言語モデルの「暗黙的計画」能力を測定する新手法:1Bパラメータモデルでも確認
大規模言語モデルは、単に次の単語を予測するだけでなく、将来出力すべき内容を事前に準備する「暗黙的計画」の能力を備えていることが明らかになりました。 本研究では、モデルの内部状態を操作する簡便な手法を用いることで、10億パラメータ程度の比較的小規模なモデルにおいても、この計画能力が普遍的に存在することを定量的に実証しました。 この手法により、特定の韻を踏む際や質問に回答する際に、数トークン手前の段階で冠詞や中間表現を動的に調整しているメカニズムが解明され、AIの安全性と制御の理解に新たな道を開きました。
TL;DR(結論)
大規模言語モデルは、単に次の単語を予測するだけでなく、将来出力すべき内容を事前に準備する「暗黙的計画」の能力を備えていることが明らかになりました。 本研究では、モデルの内部状態を操作する簡便な手法を用いることで、10億パラメータ程度の比較的小規模なモデルにおいても、この計画能力が普遍的に存在することを定量的に実証しました。 この手法により、特定の韻を踏む際や質問に回答する際に、数トークン手前の段階で冠詞や中間表現を動的に調整しているメカニズムが解明され、AIの安全性と制御の理解に新たな道を開きました。
なぜこの問題か
人間が言語を生成する際、次に発する言葉をあらかじめ頭の中で計画し、それに合わせて現在の言葉を選ぶという戦略をとることは一般的です。これに対し、トランスフォーマー型の大規模言語モデルが同様の計画メカニズムを持っているかどうかは、AIの知能の本質を探る上で極めて重要な問いとなっています。これまでの研究では、モデルが次の単語を予測するように訓練されている一方で、将来の特定の単語を出力しやすくするために、現在の中間的な単語を選択するような振る舞いが見られることが示唆されてきました。しかし、こうした「暗黙的計画」の能力を詳細に調査するためには、特定のモデルに依存した複雑な解析手法や、膨大な計算コストが必要となることが多く、多様なモデル間での比較や普遍性の検証が困難であるという課題がありました。 特に、モデルがどのようにして将来の目標に向けて現在の出力を調整しているのかという内部メカニズムの解明は、AIの安全性や制御可能性を向上させるためにも不可欠な要素です。もしモデルが隠れた計画を立てているのであれば、それは表面上のテキストだけでは判断できない意図が内部に存在することを意味します。…
核心:何を提案したのか
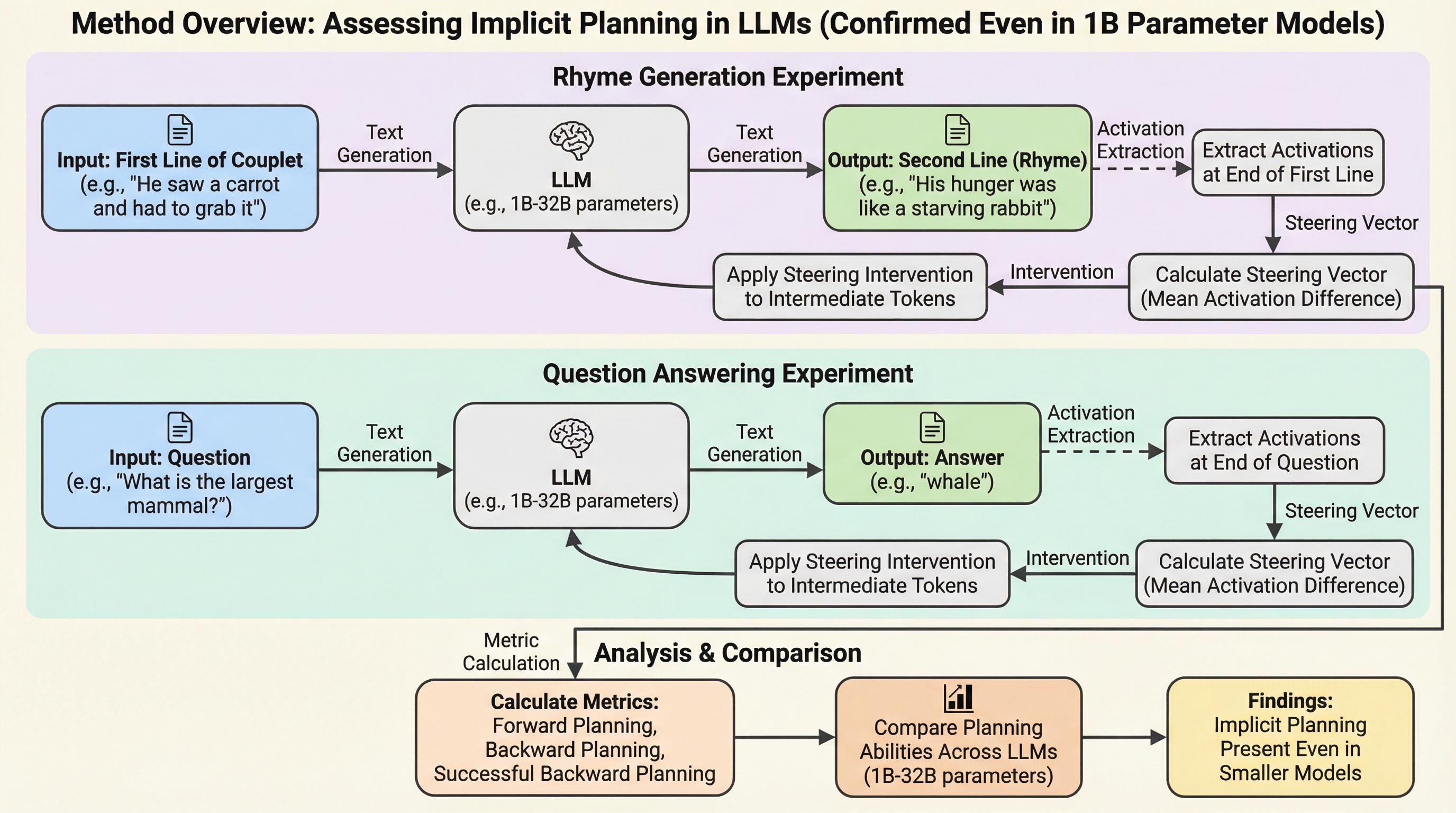
本研究の核心は、大規模言語モデルにおける暗黙的計画能力を測定するための、極めてシンプルかつスケーラブルな新しい手法を提案した点にあります。具体的には、モデルの内部的な活性化状態を直接操作する「平均活性化差分ステアリング」という手法を採用しました。これは、特定の目標(例えば特定の韻や特定の回答)を持つテキストを生成する際のモデルの内部状態と、そうでない場合の内部状態の差分を計算し、その差分ベクトルを生成プロセスに介入させることで、モデルの挙動がどのように変化するかを観察するものです。この手法の最大の特徴は、先行研究で用いられていた複雑な辞書学習や計算負荷の高いトランスコーダーを必要とせず、多様なオープンウェイトモデルに対して容易に適用できる点にあります。 研究チームは、この手法を用いて、韻を踏む詩の生成と質問応答という二つのタスクを対象とした大規模なデータセットを構築しました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related