ブルームの分類学に基づくドメインガイドラインからの自動ベンチマーク生成
本研究は、専門家のガイドラインからブルームの分類学に基づいた評価問題を自動生成するフレームワーク「BLOOMQA」を開発し、既存の試験データに依存しない新しい評価手法を確立しました。教育、栄養学、介護の3つの実務ドメインにおいて、指針への違反を題材とした多肢選択式問題と対話データを合計約6万件生成し、大規模言語モデル(LLM)の推論能力を多角的な認知レベルで測定可能にしました。検証の結果、LLMは「分析」のような高次の推論で高い性能を示す一方で、「記憶」のような基礎的な項目で失敗するという、人間の学習プロセスとは異なる非直感的な挙動を示すことが明らかになりました。
TL;DR(結論)
本研究は、専門家のガイドラインからブルームの分類学に基づいた評価問題を自動生成するフレームワーク「BLOOMQA」を開発し、既存の試験データに依存しない新しい評価手法を確立しました。教育、栄養学、介護の3つの実務ドメインにおいて、指針への違反を題材とした多肢選択式問題と対話データを合計約6万件生成し、大規模言語モデル(LLM)の推論能力を多角的な認知レベルで測定可能にしました。検証の結果、LLMは「分析」のような高次の推論で高い性能を示す一方で、「記憶」のような基礎的な項目で失敗するという、人間の学習プロセスとは異なる非直感的な挙動を示すことが明らかになりました。
なぜこの問題か
オープンエンドな質問応答(QA)の評価は、単なる事実の想起を超えた、文脈に応じた推論能力を測定するために不可欠な要素です。しかし、教育戦略や栄養指導、介護といった実践ベースのドメイン(実務ドメイン)において、この評価は極めて困難であるという課題がありました。これらの分野における知識は手続き的であり、専門的な判断に基づいているため、数学のような構造化された分野とは異なり、問題の体系的な生成が容易ではありません。既存のLLMベンチマークの多くは、人間が作成した既存の試験データセットを収集することに依存しています。例えば、医学分野のMedQAや栄養学のFoodSkyなどは、資格試験や免許試験の問題を利用しています。しかし、このような高品質な試験問題バンクが存在する分野は限られており、リソースが存在しない多くの実務ドメインではベンチマークの構築が困難でした。 また、既存の試験問題に頼る手法は、コストが高く、新しいドメインへの適応性やスケーラビリティに欠けるという問題も指摘されています。実務ドメインにおける専門性は、静的な事実の想起ではなく、複雑な文脈の中での推論を通じて発揮されるものです。…
核心:何を提案したのか
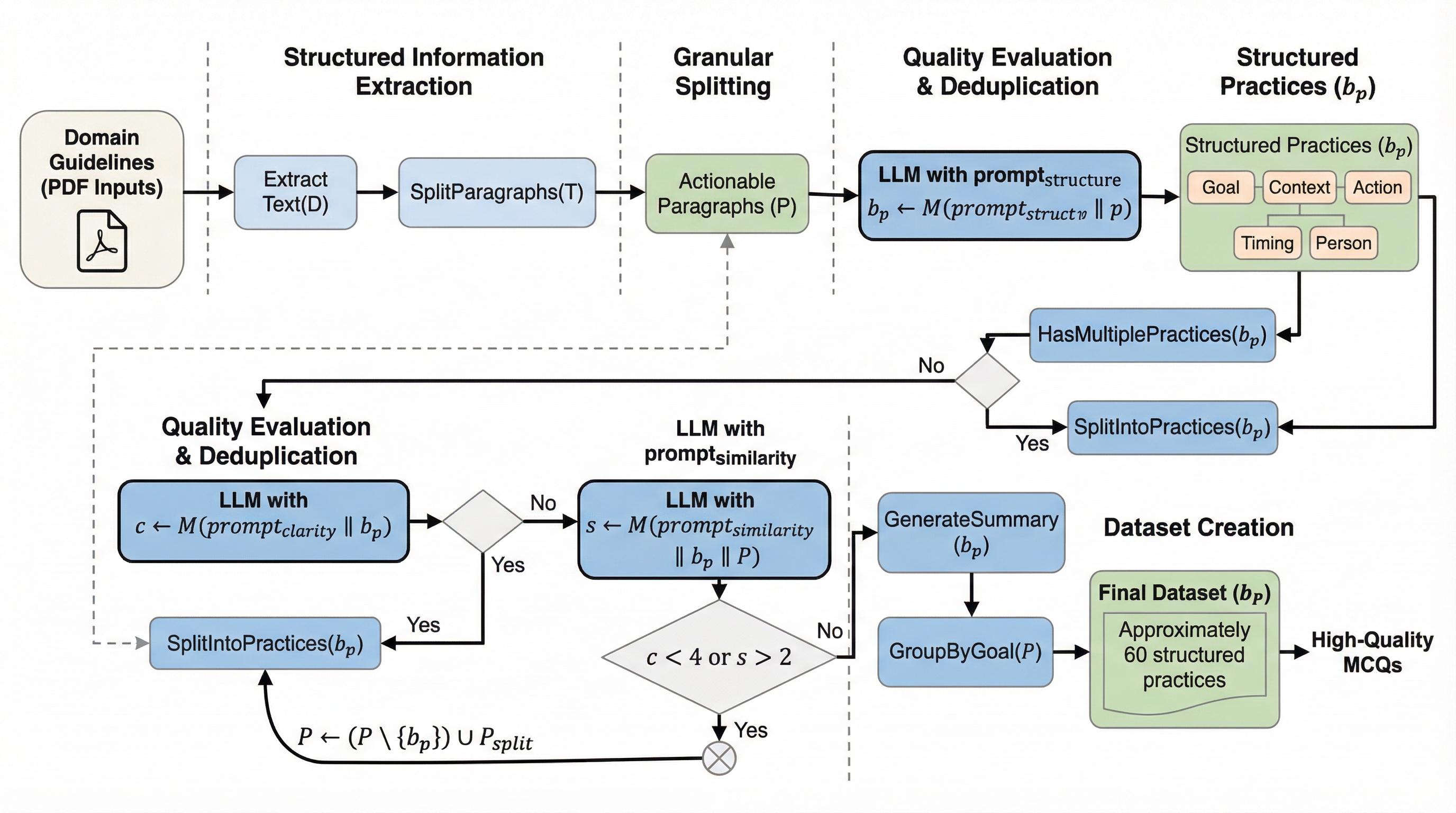
本研究は、専門家が執筆したガイドラインから、ブルームの分類学(Bloom’s Taxonomy)に沿ったベンチマークを自動生成する新しいフレームワーク「BLOOMQA」を提案しました。このフレームワークの最大の特徴は、既存の試験問題バンクを一切必要とせず、ドメインのベストプラクティスを「違反ベースのシナリオ」に変換し、それを多肢選択式問題(MCQ)や多ターン対話へと拡張する点にあります。これにより、専門的なリソースが乏しい分野であっても、信頼性の高い評価セットを構築することが可能になりました。 具体的には、まずガイドラインから実行可能な「プラクティス(実践指針)」を抽出します。次に、それらの指針が守られなかった状況を示す「違反シナリオ」を作成します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related