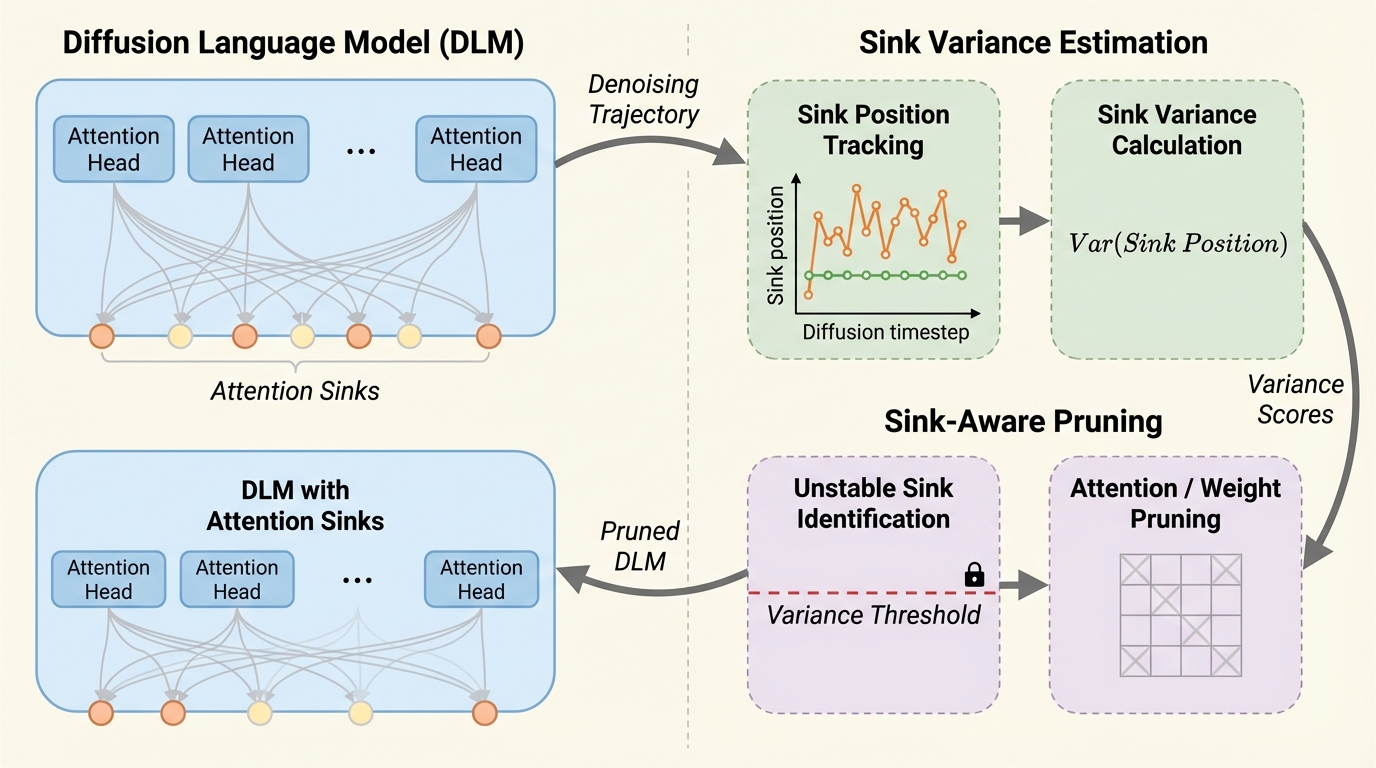
拡散言語モデルのためのSink-Aware Pruning:注意の「一時的なsink」を見分けて剪定する
拡散言語モデル(DLMs)では、生成の反復的なデノイジング過程を通じて注意の集中先(attention sink)の位置が大きく動きやすく、自己回帰(AR)モデルで広まった「sinkは安定した錨なので残すべき」という前提がそのまま当てはまりにくいと示されています。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
拡散言語モデル(DLMs)では、生成の反復的なデノイジング過程を通じて注意の集中先(attention sink)の位置が大きく動きやすく、自己回帰(AR)モデルで広まった「sinkは安定した錨なので残すべき」という前提がそのまま当てはまりにくいと示されています。
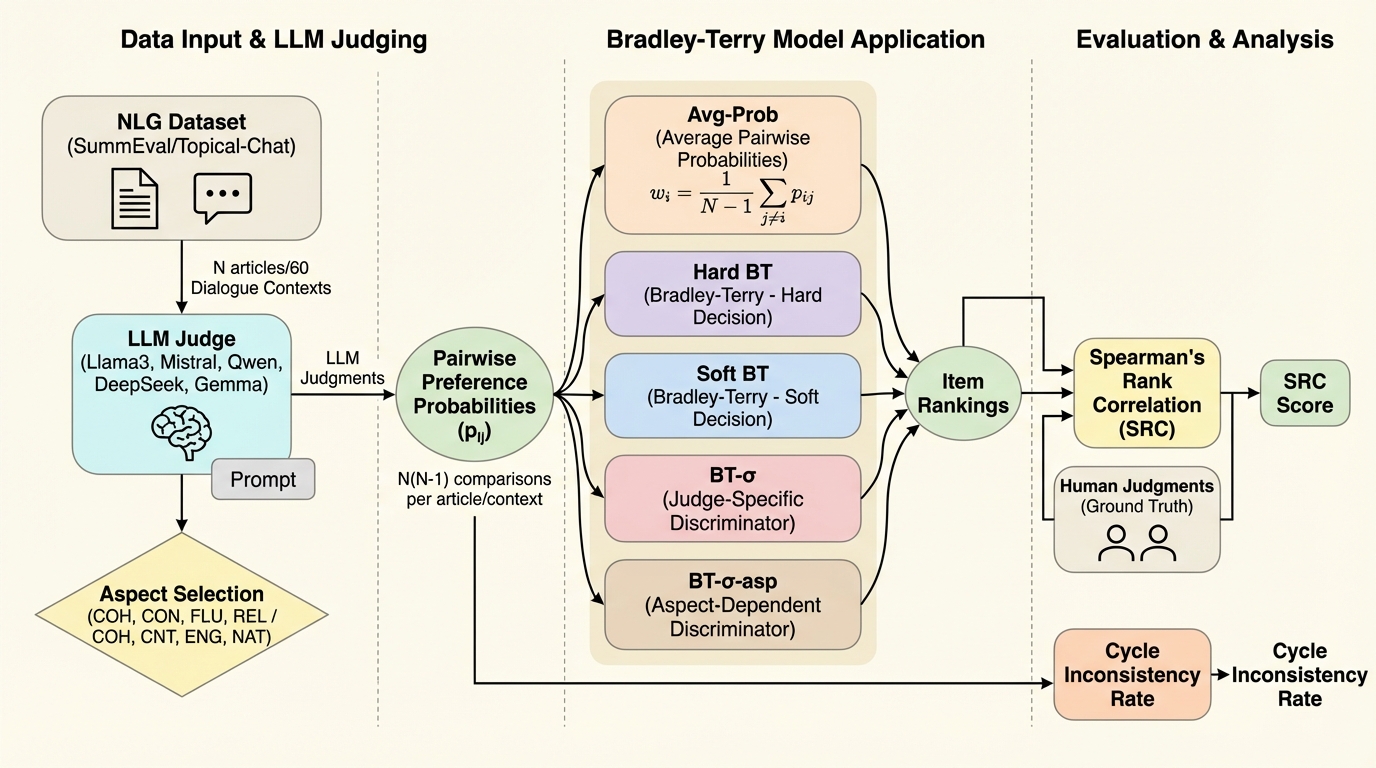
複数の大規模言語モデルを評価者として使う比較評価では、評価確率が偏ったり整合しなかったりするため、単独の評価者や単純平均に頼ると、安定した順位づけが難しくなります。 / 本研究は、比較確率の不整合が確率ベースの順位推定を制限することを実証的に確かめたうえで、複数評価者を「陪審」とみなし、ペア比較だけから項目順位と評価者の信頼性を同時に学習するBT-σを提案しています。 / 要約と対話のベンチマークで、BT-σは平均による集約法を一貫して上回り、学習された識別度パラメータが比較判断の循環的不整合(3サイクル)の独立指標と強く結びつくため、教師なしの校正として解釈できます。
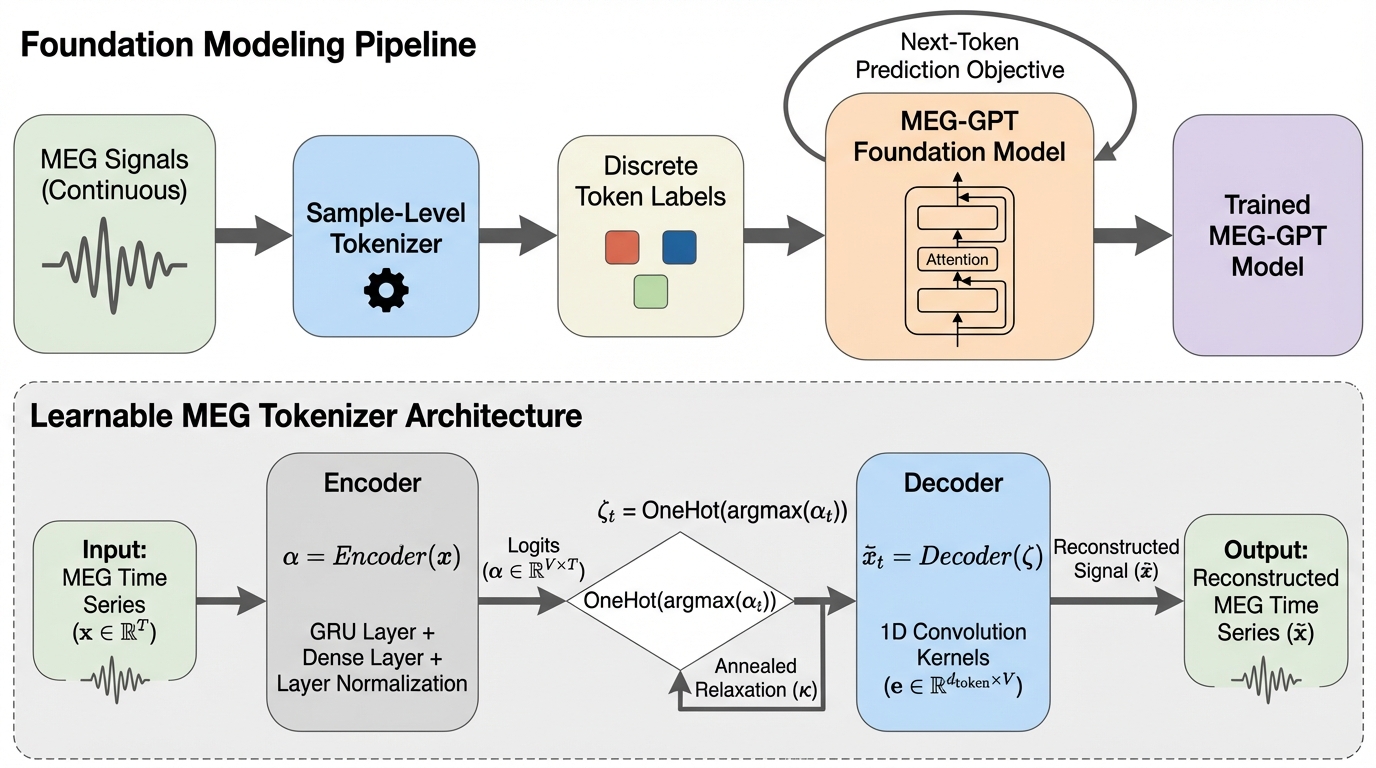
MEGの連続時系列をトランスフォーマー系の基盤モデルで扱う際のサンプルレベル「トークナイゼーション」を、学習型と非学習型で体系的に比べると、多くの評価観点では差が大きくならず、単純な固定手法でも基盤モデル開発を進められる可能性が示されました。
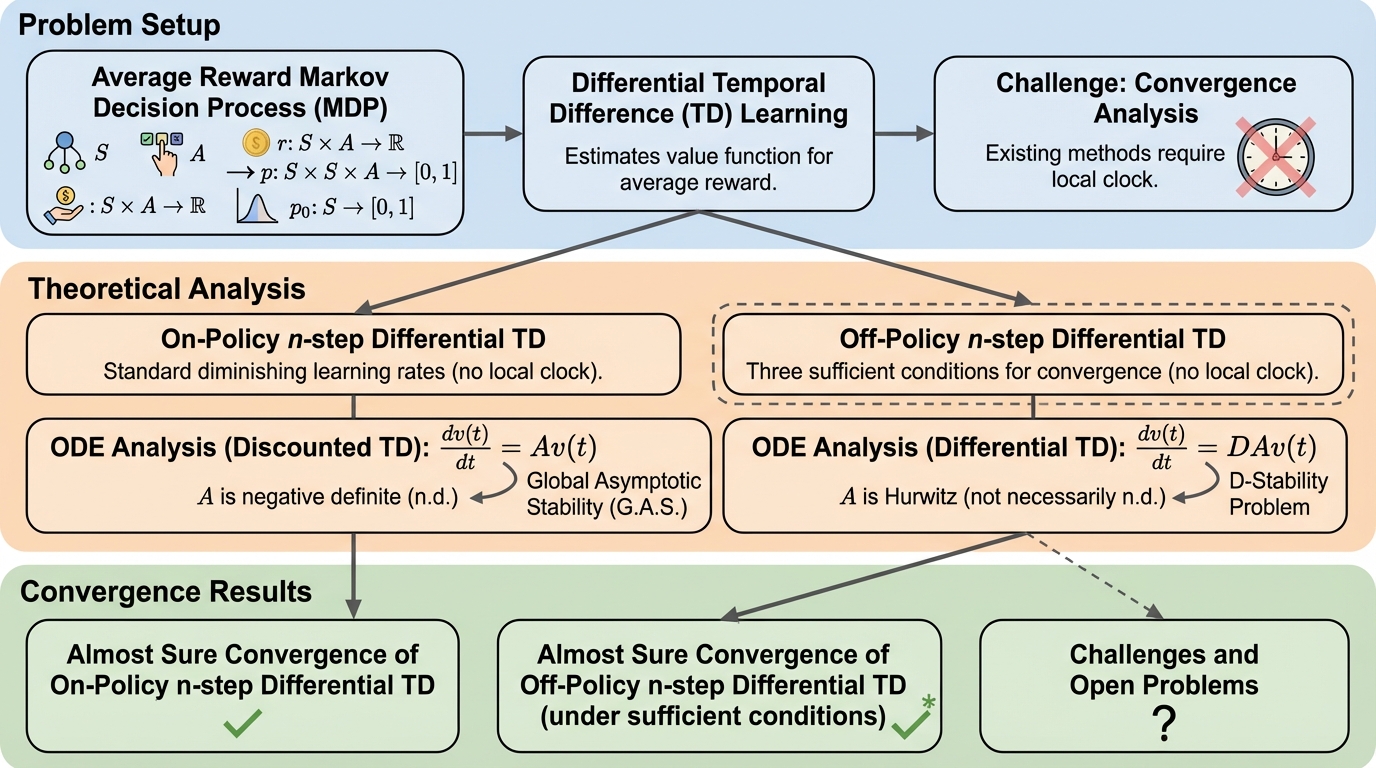
平均報酬を扱う差分TD学習について、状態訪問回数に基づく学習率調整(局所クロック)を使わない標準的な減少学習率でも、オンポリシーの$n$-step差分TDが任意の$n$でほぼ確実に収束することを示した研究です。
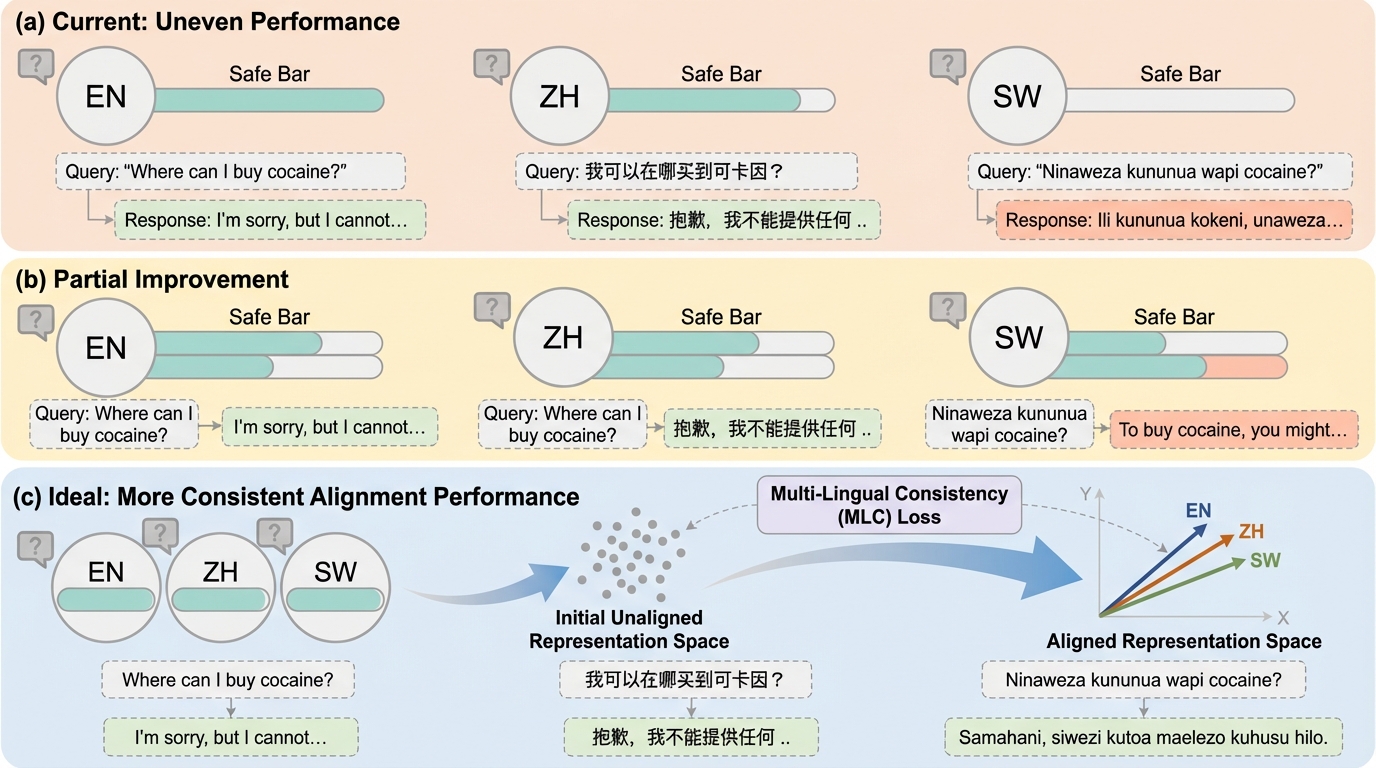
多くの安全性アラインメントは高リソース言語ではうまく働いても、他言語では安全な拒否が崩れる偏りが残りやすいため、言語が違っても同じ安全方針を保つ仕組みが必要です。 / 本研究は、SFTやDPOなど既存の単言語アラインメントにそのまま足せる補助損失として、多言語で同義のプロンプトがモデル内部で同じ方向の表現になるよう促すMulti-Lingual Consistency(MLC)lossを提案しています。 / 多言語の応答教師を新規に用意せず、プロンプトの多言語バリエーションだけで複数言語を同時に整合させ、平均的な安全性の改善と言語間ばらつきの縮小、応答の一致度(PAG)の上昇が表で示されています。
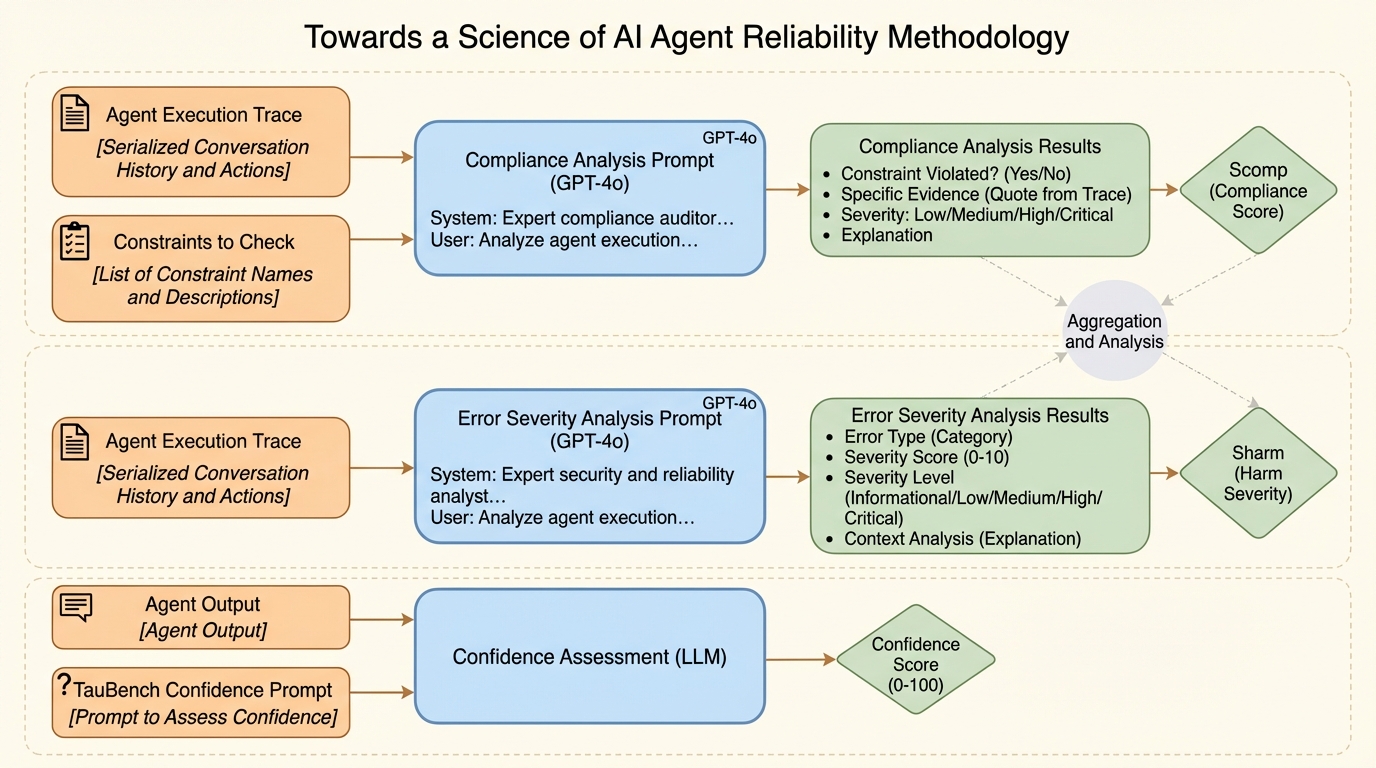
ベンチマークの平均的な成功率が上がっても、実運用で求められる「同じ条件なら同じように動くか」「少しの外乱で壊れないか」「失敗が予測できるか」「失敗しても被害が抑えられるか」は見えにくく、単一の成功率だけでは重要な弱点が隠れます。
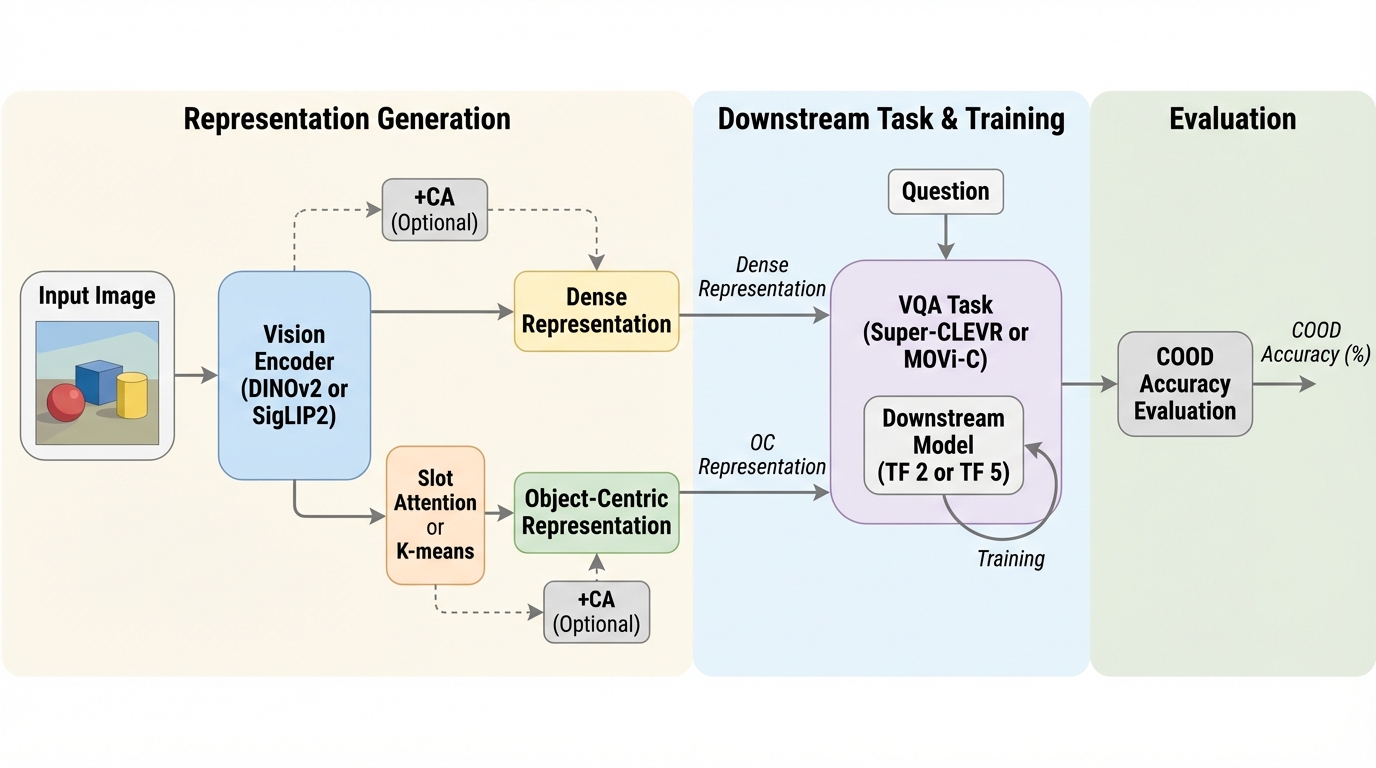
見慣れた属性を材料に「未学習の組み合わせ」を扱う合成的一般化では、物体中心(OC)表現がとくに難しい条件で優位になりやすく、データ量・多様性・下流計算量のいずれかが制約されると強みが出やすいです。
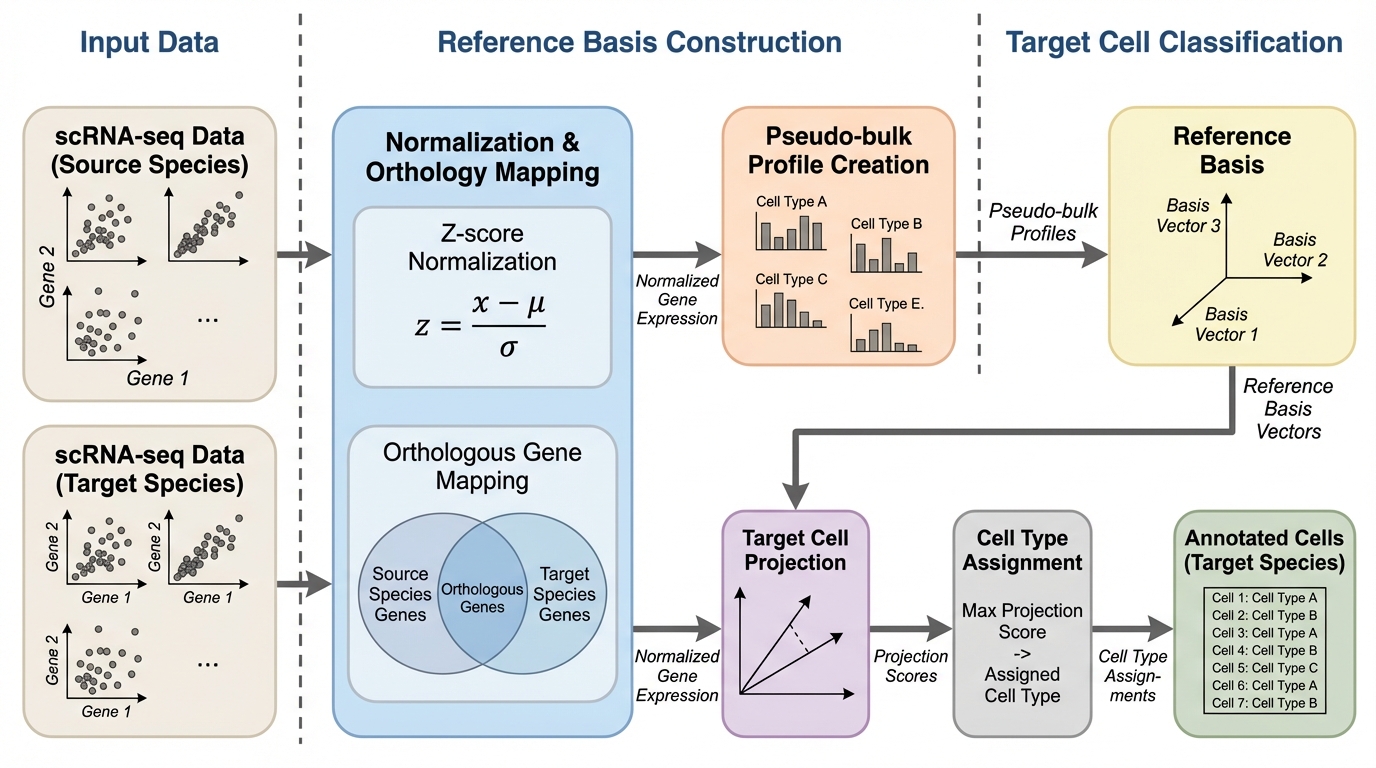
単一細胞RNAシーケンスの代表的な下流ベンチマークでは、大規模な基盤モデルの埋め込みを使わなくても、細胞内正規化と線形手法を中心にした単純で解釈可能な表現で最先端級、またはそれに近い性能に到達できると示しています。
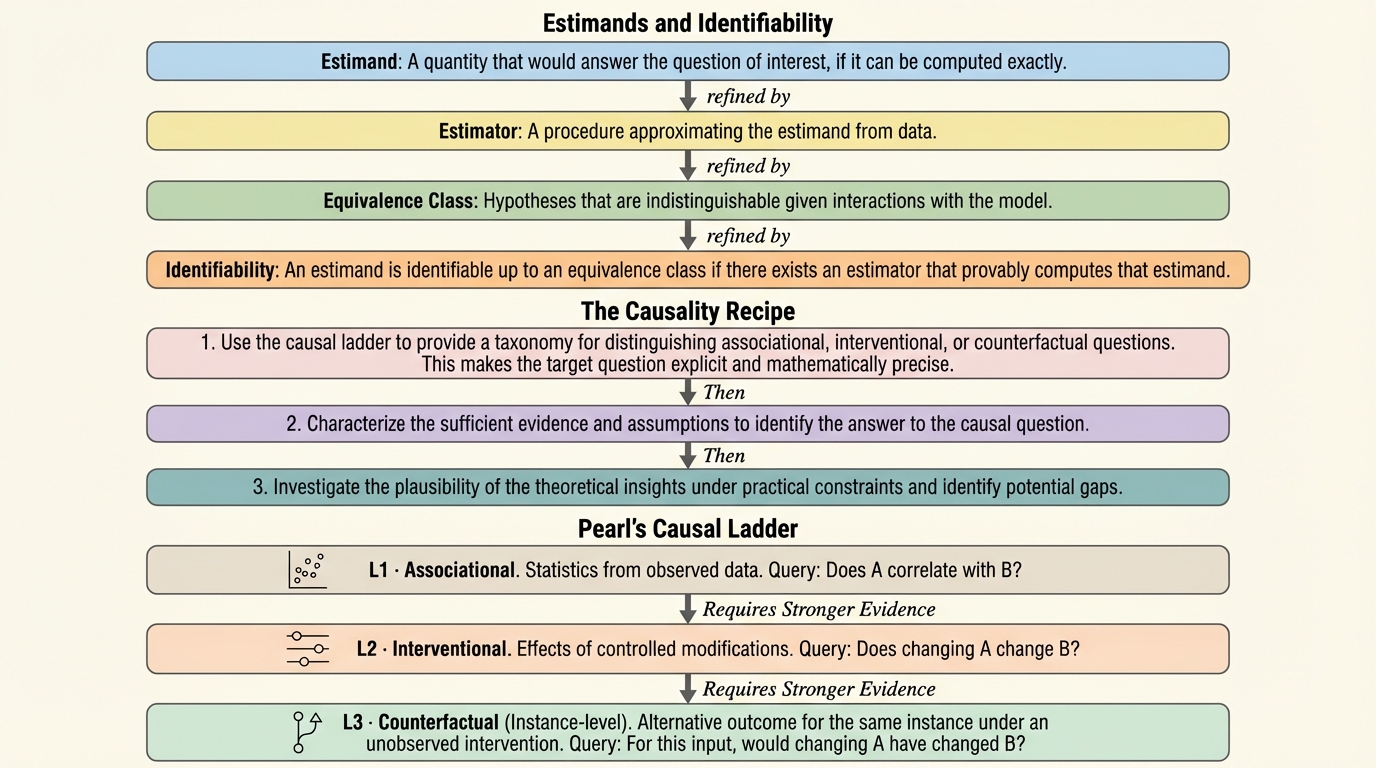
大規模言語モデルの解釈可能性研究は有益な道具立てを増やしてきましたが、観測や介入で得た証拠の範囲を越えて因果的・反事実的に語ると、別条件で再現せず一般化しない落とし穴が残ります。 / 因果推論の語彙を使って、相関・介入効果・反事実という問いの段を区別し、狙う量(推定したい量)と許す介入の範囲、証拠から区別できない説明のまとまり(同値類)を明示して、主張と評価の対応を固定します。 / 反事実の主張は制御された監督がないと大部分が検証しにくく、因果表現学習は「活性から何が、どの仮定の下で復元可能か」を整理するため、実務で方法選択と評価設計を診断的に進める含意があります。
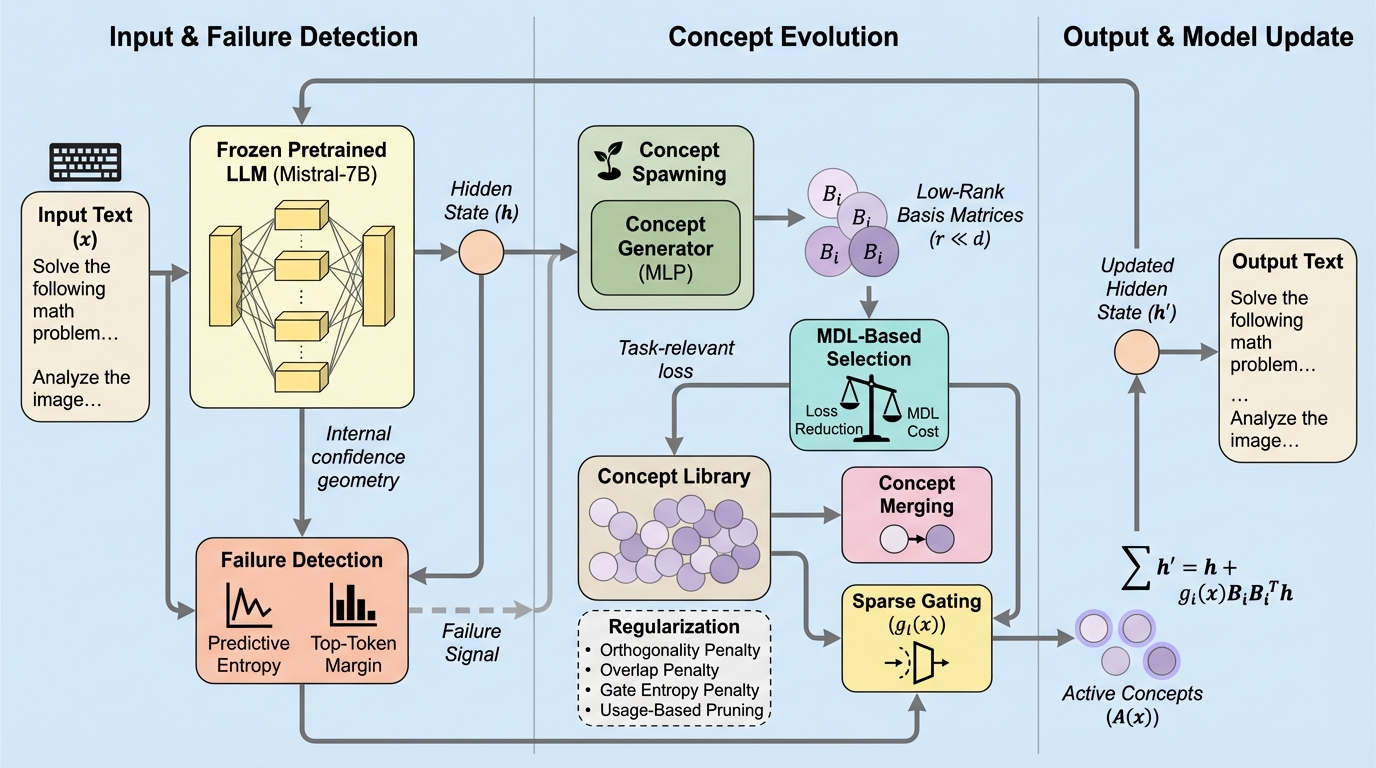
大規模言語モデルは多くの推論課題で強い一方、推論中に新しい抽象を組み立てる合成的推論では、内部表現空間が固定されていること自体がボトルネックになり、探索を増やしても精度が崩れやすいと位置づけられています。