MoHETS: 異種混合エキスパートを用いた長期時系列予測
MoHETSは、多変量時系列データの複雑な多スケール構造を捉えるために、構造の異なる専門家ネットワークを組み合わせた「異種混合エキスパート(MoHE)」を導入したエンコーダーのみのTransformerモデルである。
TL;DR(結論)
MoHETSは、多変量時系列データの複雑な多スケール構造を捉えるために、構造の異なる専門家ネットワークを組み合わせた「異種混合エキスパート(MoHE)」を導入したエンコーダーのみのTransformerモデルである。 大域的な傾向を維持する共有の奥行き方向畳み込みエキスパートと、局所的な周期性を解析するルーティングされたフーリエ変換ベースのエキスパートを動的に使い分けることで、従来の均一な構造を持つモデルの限界を克服している。 外部変数を取り込むクロスアテンションや軽量な畳み込みパッチデコーダーを採用し、主要なベンチマークにおいて平均二乗誤差を12%削減するとともに、未知の予測期間に対する高い汎用性と学習の安定性を実証した。
なぜこの問題か
現実世界の多変量時系列データは、極めて複雑で多層的な構造を持っている。これには、数ヶ月から数年にわたる長期的な大域的トレンド、日次や週次で繰り返される局所的な周期性、そして時間の経過とともに統計的性質が激しく変化する非定常な挙動が含まれる。エネルギー管理、金融計画、ヘルスケア、気候分析といった多様なドメインにおいて、これらの要素を正確に予測することは意思決定の根幹をなすが、従来の統計的手法であるARIMAやベクトル自己回帰などでは、非線形なパターンや高次元の相互作用を十分に捉えることが困難であった。近年の深層学習、特にTransformerアーキテクチャの登場により、長距離の依存関係をモデル化する能力は飛躍的に向上したものの、標準的なTransformerには時系列データ特有の課題に対する根本的な不適合が存在している。 自然言語処理のために設計された従来のTransformerは、すべてのトークンに対して均一な処理、具体的には同一の構造を持つ多層パーセプトロン(MLP)を適用する「一律の対応」を前提としている。…
核心:何を提案したのか
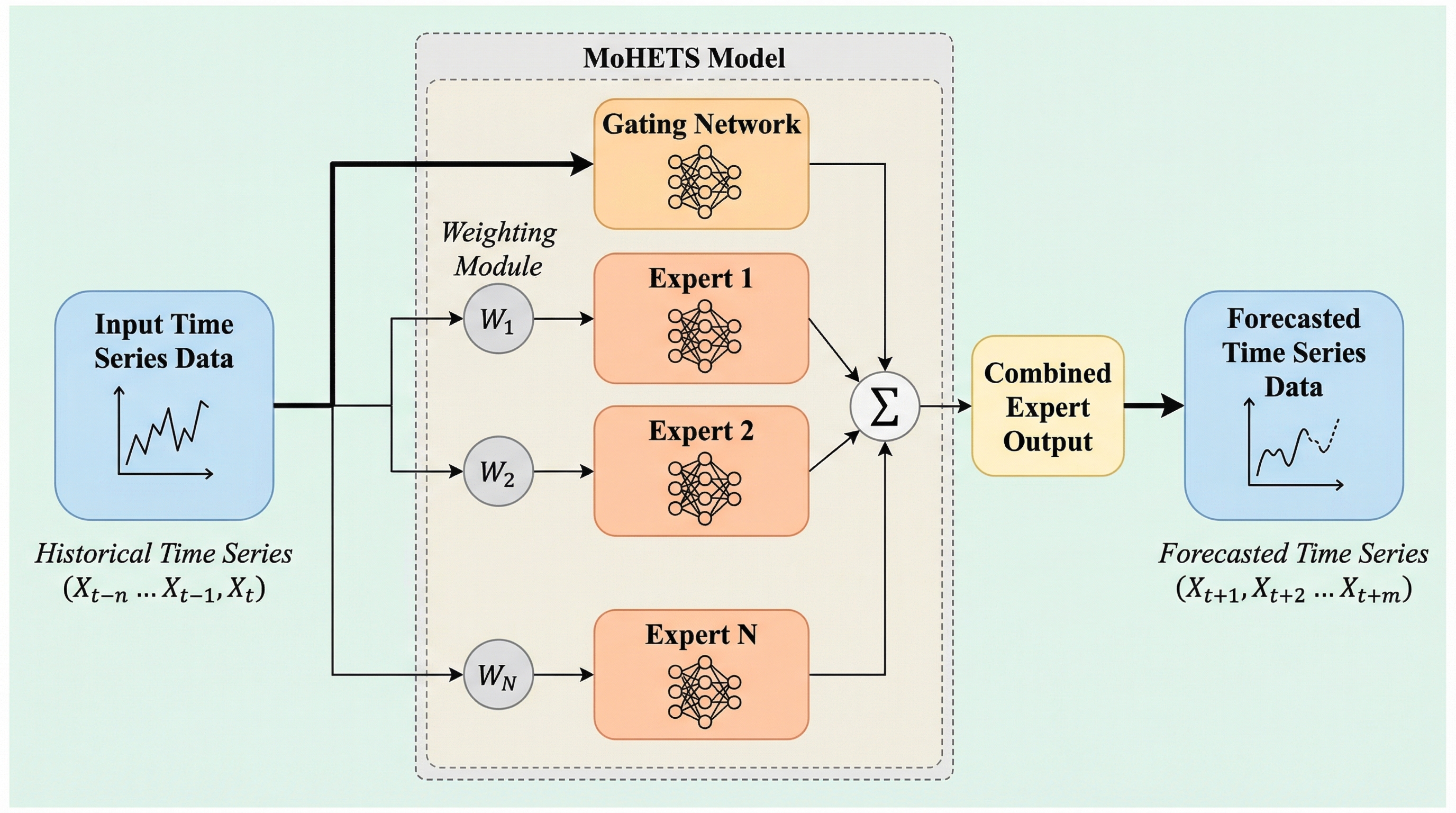
本論文では、時系列データの固有の性質に直接適合するように設計された新しいエンコーダーのみのTransformerモデルである「MoHETS」を提案している。このモデルの最大の特徴は、従来の均一なエキスパート設計を打破し、アーキテクチャ的に異なる演算子を組み合わせた「異種混合エキスパート(MoHE)」レイヤーを導入した点にある。MoHEは、入力されたデータのパッチを、その信号特性に基づいて最適な専門家ネットワークへと動的にルーティングする仕組みを持つ。具体的には、シーケンス全体の連続性と大域的なトレンドを維持するための「共有エキスパート」として奥行き方向畳み込み(Depthwise Convolution)を採用している。一方で、局所的な周期構造やスペクトルパターンを解析するための「ルーティングされたエキスパート」として、フーリエ変換ベースのネットワークを配置している。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related