視覚的分離拡散オートエンコーダ:基盤モデルのためのスケーラブルな反事実生成
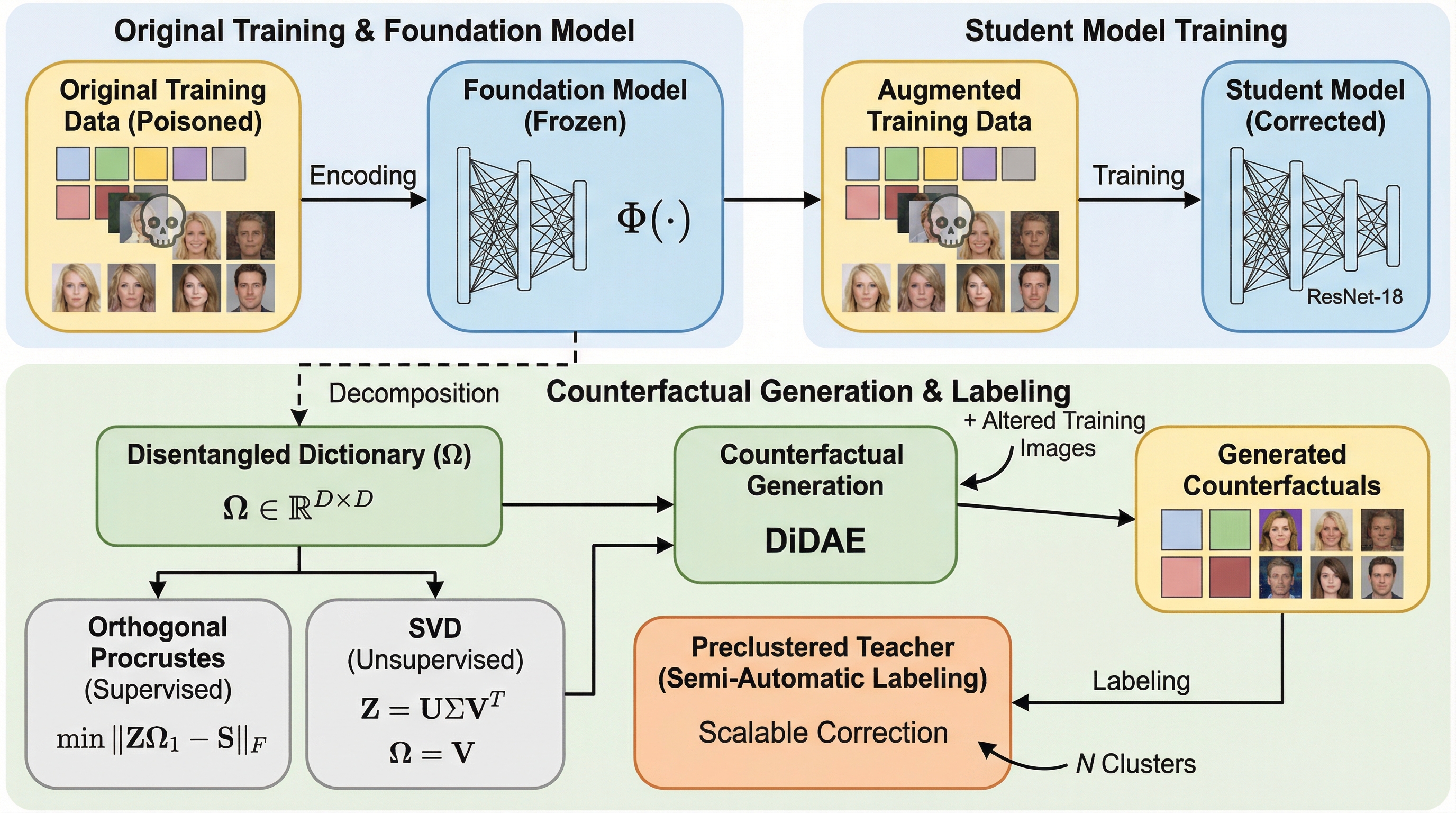
基盤モデルが「賢いハンス」現象や偽の相関に依存する問題を解決するため、視覚的分離拡散オートエンコーダ(DiDAE)が提案されました。この手法は、凍結された基盤モデルの潜在空間を分離辞書学習によって解釈可能な方向に分解し、勾配計算を必要としない高速かつ精密な反事実的画像の生成を可能にします。
TL;DR(結論)
基盤モデルが「賢いハンス」現象や偽の相関に依存する問題を解決するため、視覚的分離拡散オートエンコーダ(DiDAE)が提案されました。この手法は、凍結された基盤モデルの潜在空間を分離辞書学習によって解釈可能な方向に分解し、勾配計算を必要としない高速かつ精密な反事実的画像の生成を可能にします。 生成された多様な反事実的データを用いて反事実的知識蒸留(CFKD)を行うことで、ラベルが不足している不均衡なデータセットにおいても、ショートカット学習を効果的に抑制し、下流タスクの性能を大幅に向上させることが確認されました。 従来の勾配ベースの手法と比較して、DiDAEは生成速度と意味的な分離性能の両面で優れており、大規模な基盤モデルの修正を現実的な計算コストで実現するスケーラブルなフレームワークとして機能することが実証されました。
なぜこの問題か
深層学習モデルは特定のベンチマークで驚異的な性能を発揮しますが、分布外のデータに対しては脆弱であり、本来注目すべき因果的な特徴ではなく、背景のテクスチャや特定のタグといった統計的な近道(ショートカット)を学習してしまう「賢いハンス」戦略を採用することが多々あります。CLIPのような強力な基盤モデルであっても、背景のテクスチャなどの非因果的なアーティファクトを系統的にエンコードしていることが近年の研究で示されており、これが実社会での信頼性を損なう要因となっています。本来の目的とは無関係な特徴に依存するモデルは、学習データと異なる環境では正しく機能せず、予期せぬ誤判定を招くリスクを孕んでいます。 既存の対策手法の多くは、過小評価されているサブグループを再重み付けするために明示的なグループラベルに依存していますが、これらのラベルが利用できない場合や、交絡変数が不明な場合には、手法の拡張性が著しく制限されるという課題がありました。説明可能AI(XAI)の分野では、反事実的知識蒸留(CFKD)という代替案が提示されており、反事実的な例を生成することで交絡因子への依存を露呈させ、それを取り除くことが試みられています。…
核心:何を提案したのか
本論文では、これらの制限を克服するために、視覚的分離拡散オートエンコーダ(DiDAE)という新しいフレームワークを提案しています。DiDAEは、凍結された基盤モデルの周囲を分離辞書学習で包み込むような構成をとっており、基盤モデルの潜在空間を解釈可能な分離された方向に分解することで、勾配更新を行うことなく、高速かつ精密な意味的操作を可能にします。このアプローチにより、モデルの内部表現を直接的かつ効率的に制御する手段が提供されます。 具体的には、まず基盤モデルの埋め込みを分離辞書の解釈可能な方向に沿って編集し、その後、拡散オートエンコーダを介して画像としてデコードします。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related