コードの複雑さとLLMの推論能力:データ中心のアプローチによる分析
大規模言語モデル(LLM)の推論能力を向上させるためには、学習に用いるコードの「構造的複雑さ」を適切に制御することが極めて重要であり、単にデータの量や多様性を増やすだけでは不十分であることが明らかになりました。
TL;DR(結論)
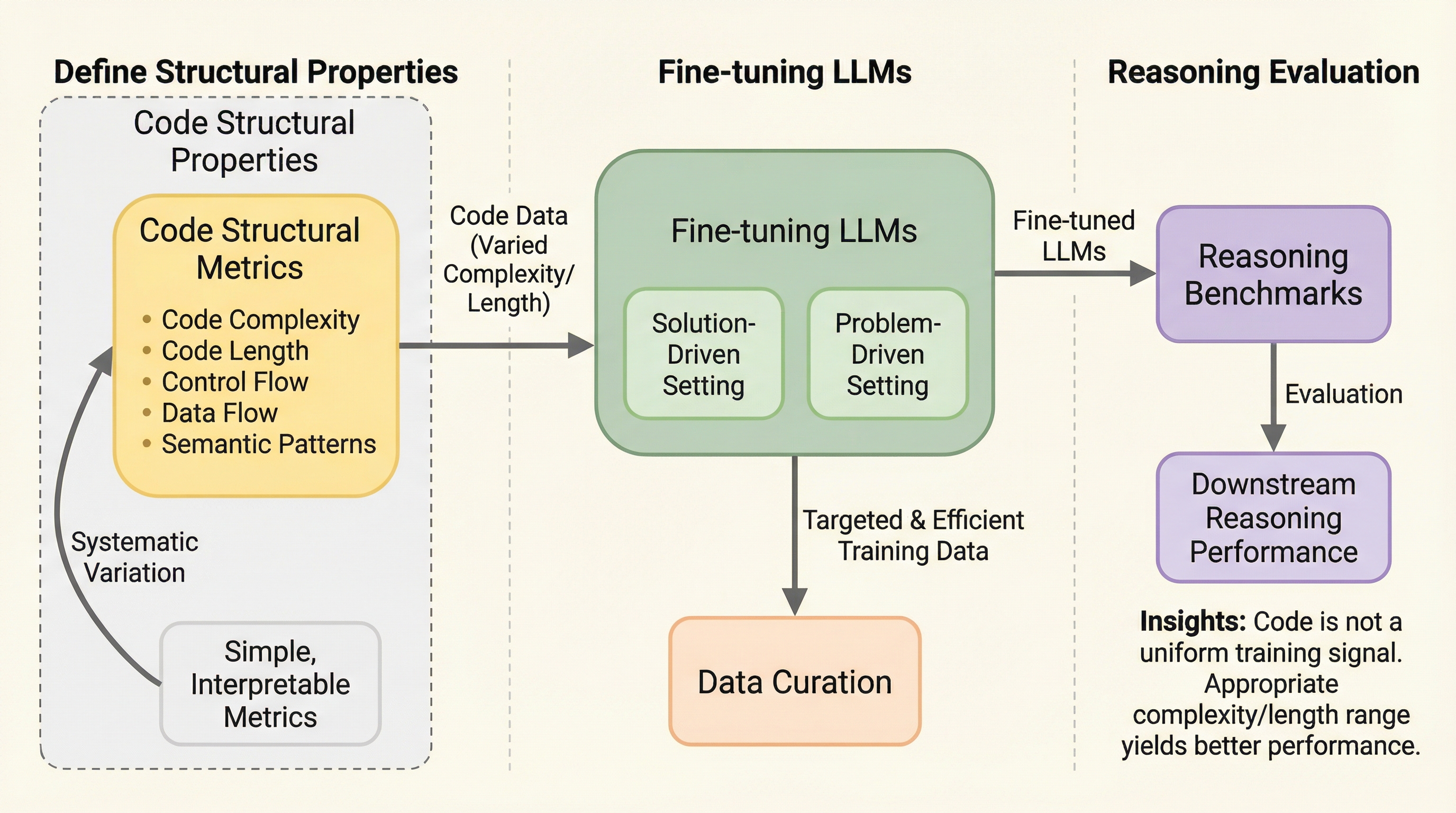
大規模言語モデル(LLM)の推論能力を向上させるためには、学習に用いるコードの「構造的複雑さ」を適切に制御することが極めて重要であり、単にデータの量や多様性を増やすだけでは不十分であることが明らかになりました。 実験の結果、モデルの性能向上とコードの複雑さの間には「非単調な関係」が存在し、中間程度の複雑さを持つデータで性能がピークに達する一方で、単純すぎたり複雑すぎたりするデータでは効果が薄れる傾向が確認されました。 全実験の83%において、多様な複雑さを混ぜたデータセットよりも、特定の複雑さの範囲に限定したデータでファインチューニングを行う方が高い推論性能を示しており、モデルごとに最適な「構造的情報の密度」を選択するデータ中心のアプローチが有効です。
なぜこの問題か
大規模言語モデル(LLM)が数学的、論理的、あるいは多分野にわたる複雑な問題を解決する際、思考の連鎖(Chain-of-Thought)と呼ばれる中間的な推論ステップを生成する能力がその鍵を握っています。近年の研究では、自然言語だけでなくプログラミングコードを用いた学習が、これらの推論スキルをさらに強化することが示唆されてきました。しかし、これまでの研究の多くはコードを単なる一般的なトレーニング信号として扱っており、コードが持つどのような具体的な特性が実際に推論能力の向上に寄与しているのかという根本的な問いは未解決のままでした。 コードは、制御フロー、分岐、中間計算といった要素を自然に表現する構造を持っており、これはマルチステップの推論を構築するための強力な構造的信号となります。本研究では、コードの「構造的複雑さ」が、ファインチューニング中にモデルが多段階の推論プロセスを内部化する方法を形作っているのではないかという仮説を立てました。より複雑なプログラムは、より深い分岐や豊かな実行パスを持っており、これが構造化された推論トレースの暗黙的な形式として機能し、モデルを多段階の分解パターンにさらす可能性があると考えられます。…
核心:何を提案したのか
本研究では、コードの構造的複雑さがLLMの推論能力に与える影響を解明するために、データ中心のアプローチによる体系的な調査を提案しました。具体的には、ソフトウェア工学の分野で確立されている「サイクロマティック複雑度(Cyclomatic Complexity)」と「論理コード行数(Logical Lines of Code)」という2つの指標を用いて、コードの構造的特性を定量化しました。サイクロマティック複雑度はプログラム内の独立した実行パスの数を捉え、論理コード行数はフォーマットに依存しない実行可能なロジックの量を反映します。 実験では、複雑さの発生源を切り分けるために2つの相補的な設定を構築しました。1つ目は「解決策主導の複雑さ(Solution-driven complexity)」です。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related