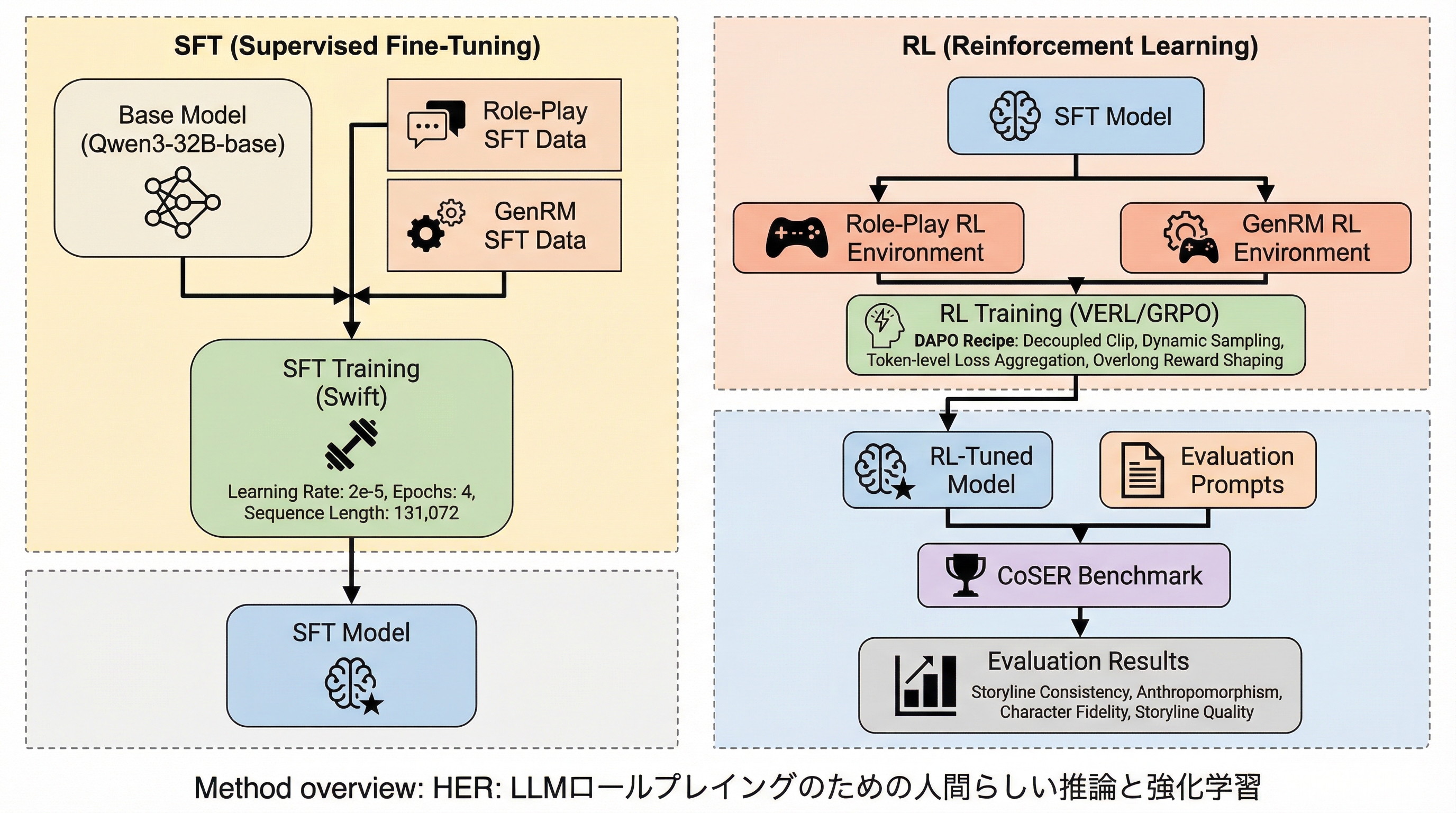
HER: LLMロールプレイングのための人間らしい推論と強化学習
HER(Human Emulation Reasoning)は、LLMのロールプレイングにおいてキャラクターの内面的な思考を高度にシミュレートするための統合フレームワークであり、隠された三人称視点の「システム思考」と、公開される一人称視点の「ロール思考」を分離した二層構造の思考プロセスを導入しています。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
HER(Human Emulation Reasoning)は、LLMのロールプレイングにおいてキャラクターの内面的な思考を高度にシミュレートするための統合フレームワークであり、隠された三人称視点の「システム思考」と、公開される一人称視点の「ロール思考」を分離した二層構造の思考プロセスを導入しています。
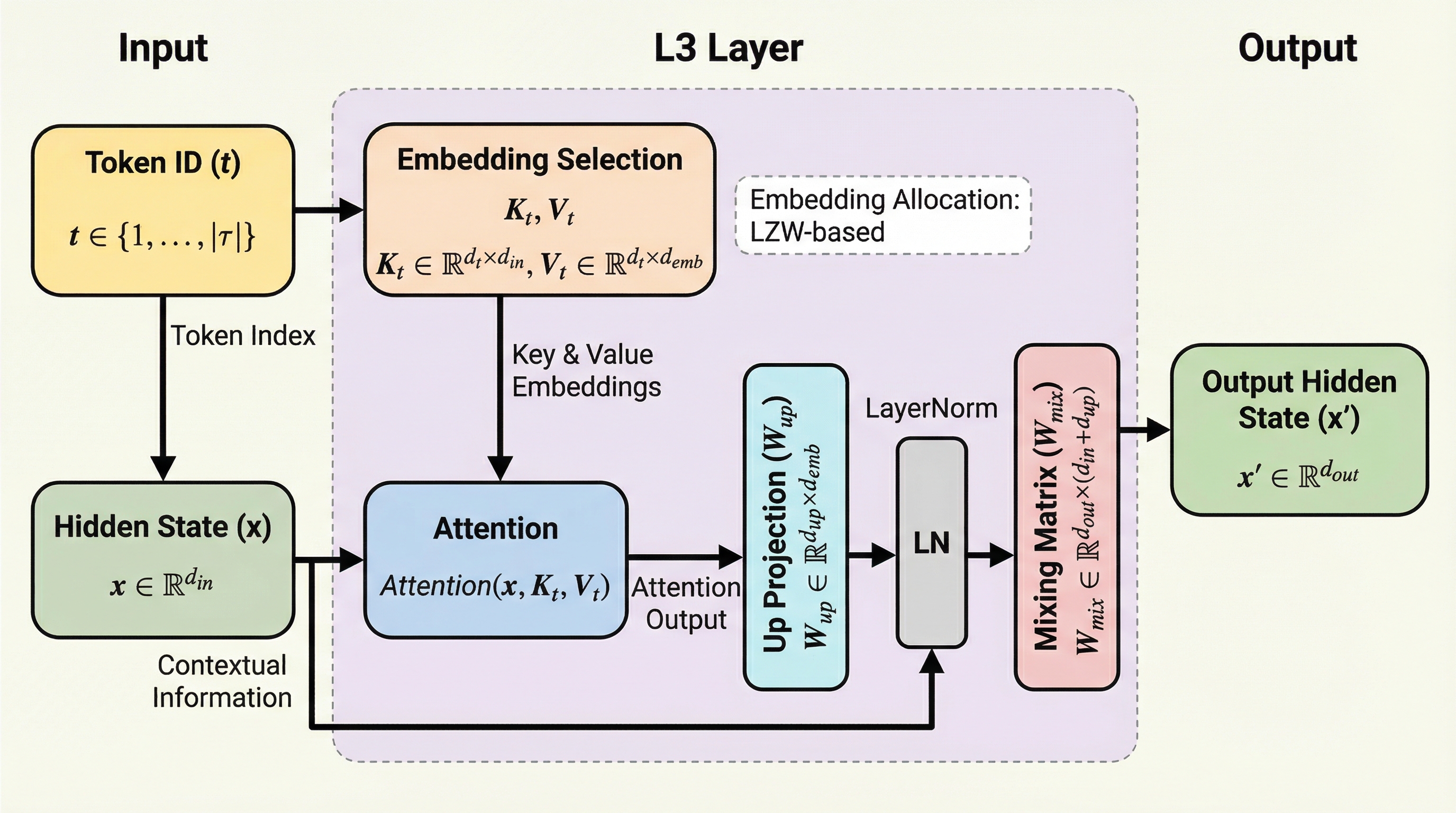
L3(Large Lookup Layer)は、従来のMixture-of-Experts(MoE)が抱える動的ルーティングに伴うハードウェア効率の低下や学習の不安定さを解消するために提案された、新しいスパースアーキテクチャである。
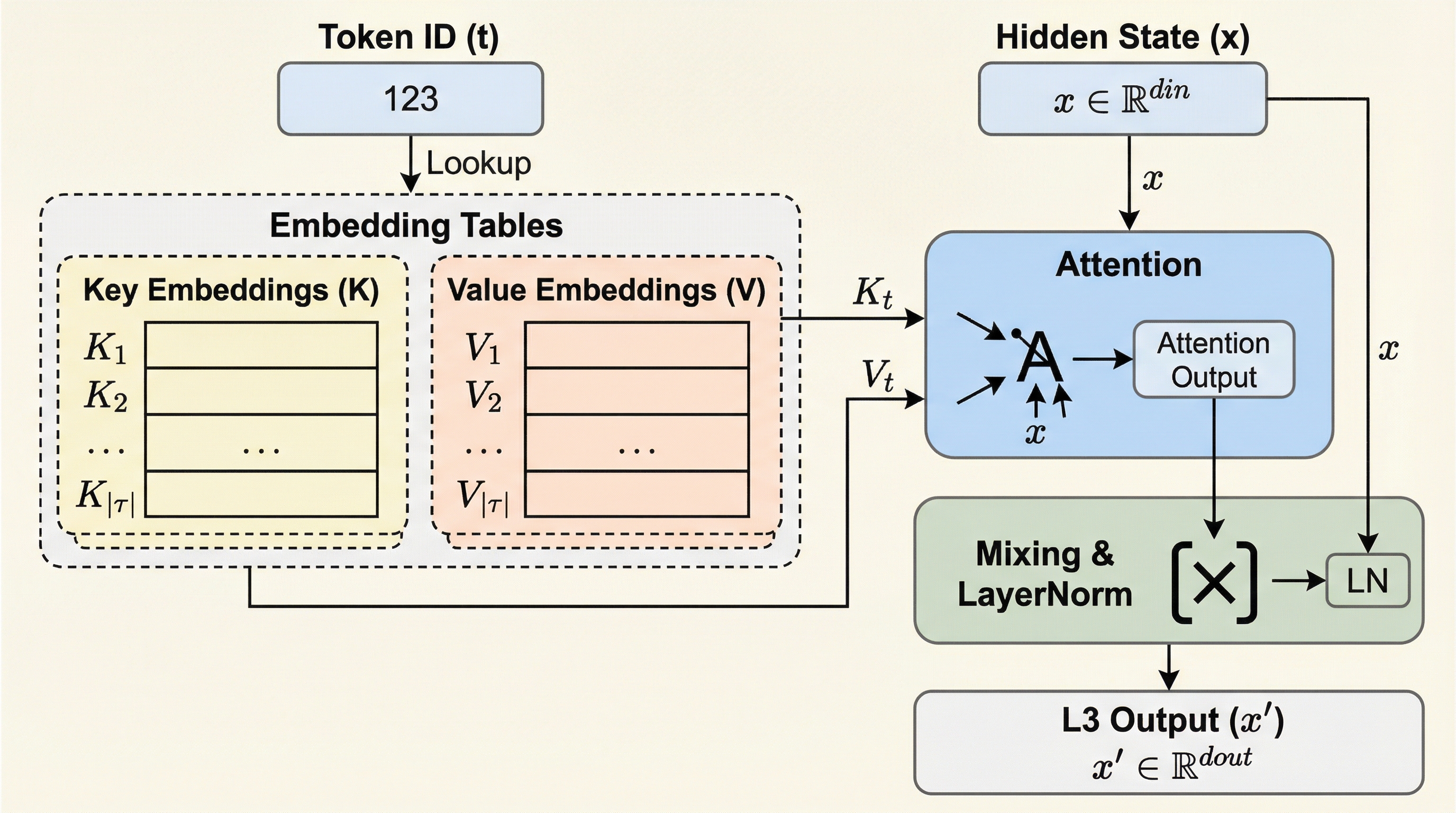
L$^3$(Large Lookup Layer)は、従来のMixture-of-Experts(MoE)が抱えるハードウェア効率の低下や学習の不安定さを克服するために提案された、新しいスパースなデコーダ層のアーキテクチャである。
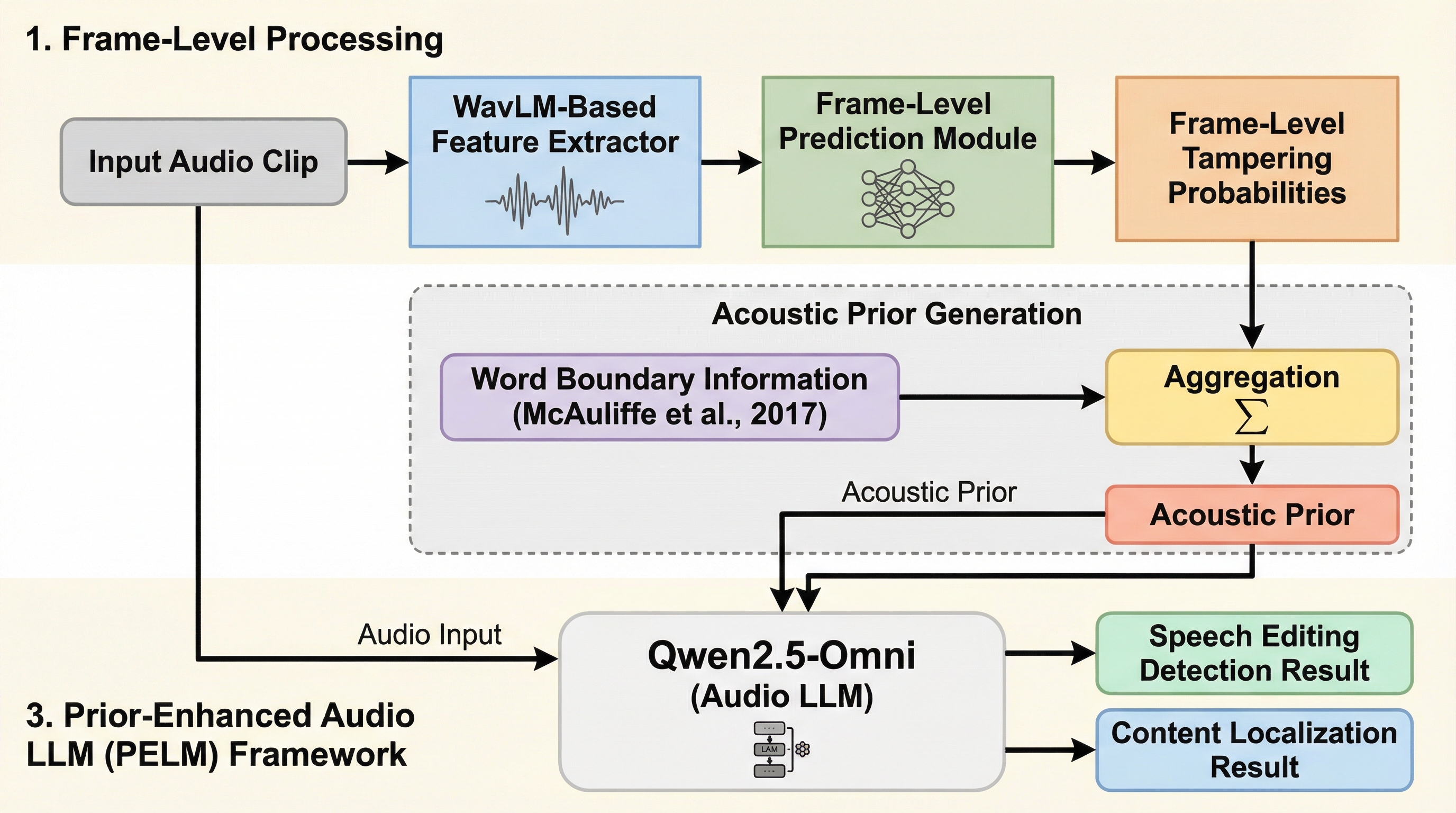
音声の一部を削除・挿入・置換する巧妙な編集を検出するため、大規模言語モデル(LLM)を活用して論理的な改ざんを施した高品質な二言語データセット「AiEdit」を構築しました。 このデータセットを基に、音声編集の検出と改ざん箇所の特定を「音声応答タスク」として統合し、単語レベルの音響的先験情報と一貫性を捉える損失関数を導入した新フレームワーク「PELM」を開発しました。 検証の結果、PELMは従来のオーディオLLMが陥りやすい誤検知や意味内容への偏重を克服し、既存手法を大幅に上回る精度で、継ぎ目のない高度な音声改ざんを識別・特定することに成功しました。
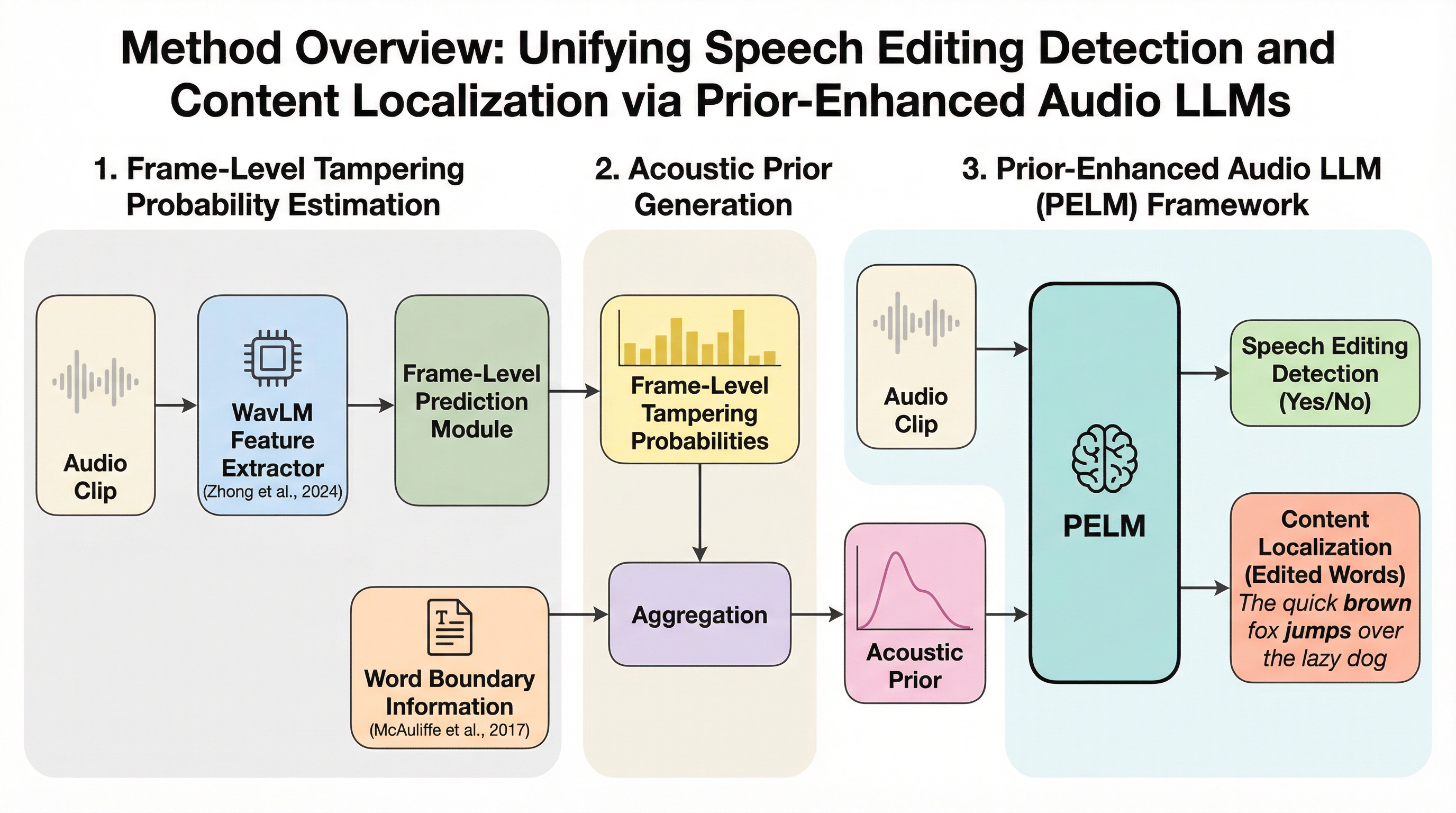
従来の音声編集検出は手動編集による継ぎ目の痕跡に依存していたが、最新のニューラル音声編集技術が生成する自然な音響遷移の検出は困難であったため、大規模言語モデルを活用して精密な意味改ざん論理を駆動し、複数の高度な生成手法を統合した高品質な二言語データセット「AiEdit」を構築した。
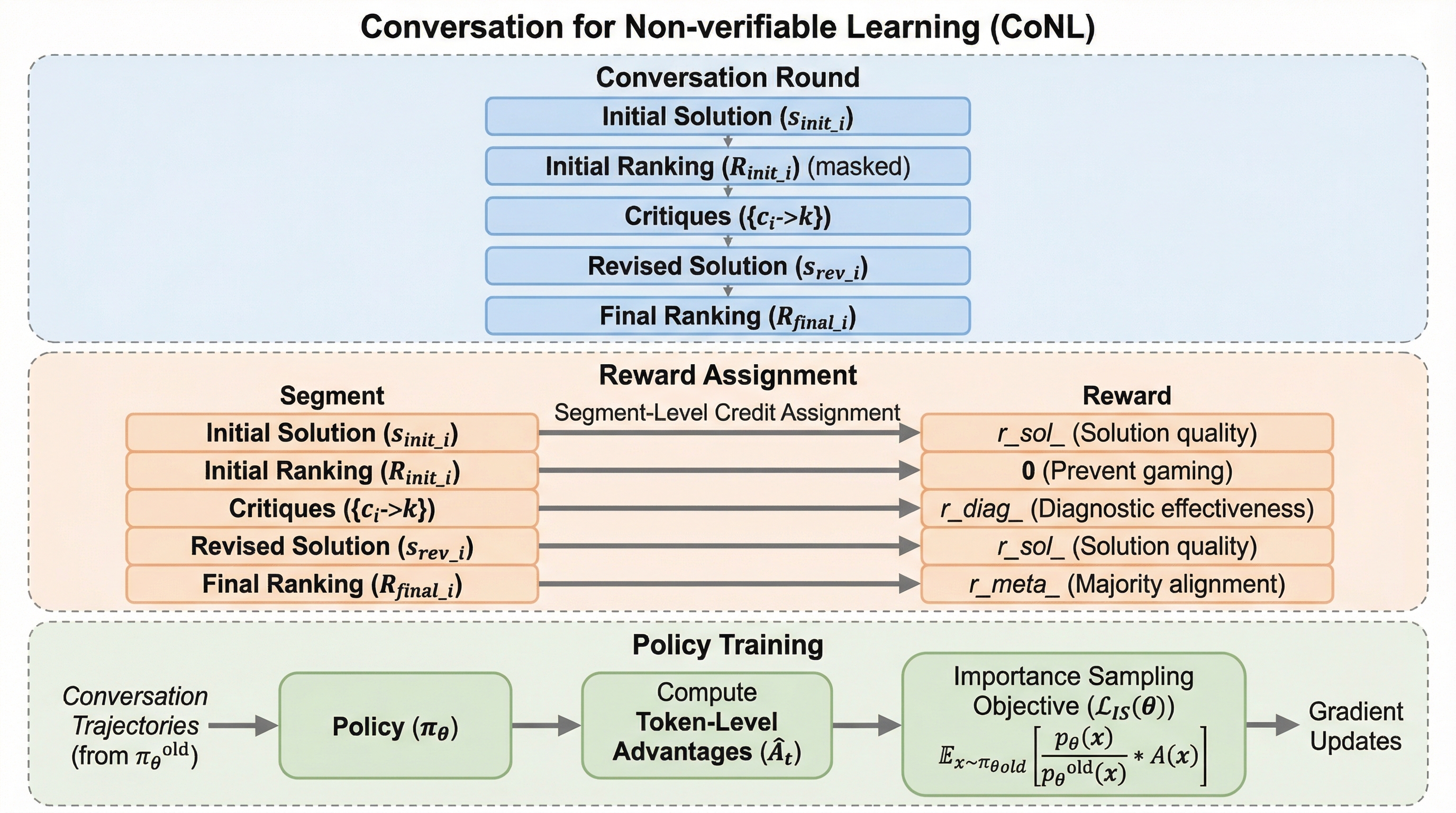
クリエイティブな執筆や倫理的推論といった正解が検証不可能なタスクにおいて、大規模言語モデルを訓練することは、客観的な正解ラベルが存在しないため非常に困難である。既存の「LLM-as-Judge」手法は評価者自身の能力やバイアスに性能が制限されるという課題を抱えていたが、本研究は他者の回答を改善させたかどうかで批判の質を測定する「診断的報酬」を導入した。 提案手法「CoNL」は、マルチエージェントの自己対話を通じて生成、評価、メタ評価を統合するフレームワークであり、外部の評価者や正解データに頼ることなく、対話の力学から得られる信号を用いてモデルを自律的に進化させる。5つのベンチマークを用いた実験の結果、CoNLは従来の自己報酬型手法を最大8.3パーセント上回る性能向上を達成し、学習の安定性を維持しながら正解報酬を用いた強化学習に近い成果を収めた。 この手法は、ピアレビューのような相互監視のプロセスを学習信号に変えることで、検証不可能な領域におけるモデルの限界を突破し、より高品質で信頼性の高い回答の生成を可能にするものである。従来の自己報酬型モデルが陥りがちだった回答の肥大化(冗長性バイアス)を抑制し、評価能力そのものを訓練可能なスキルとして定義した点に大きな革新性がある。
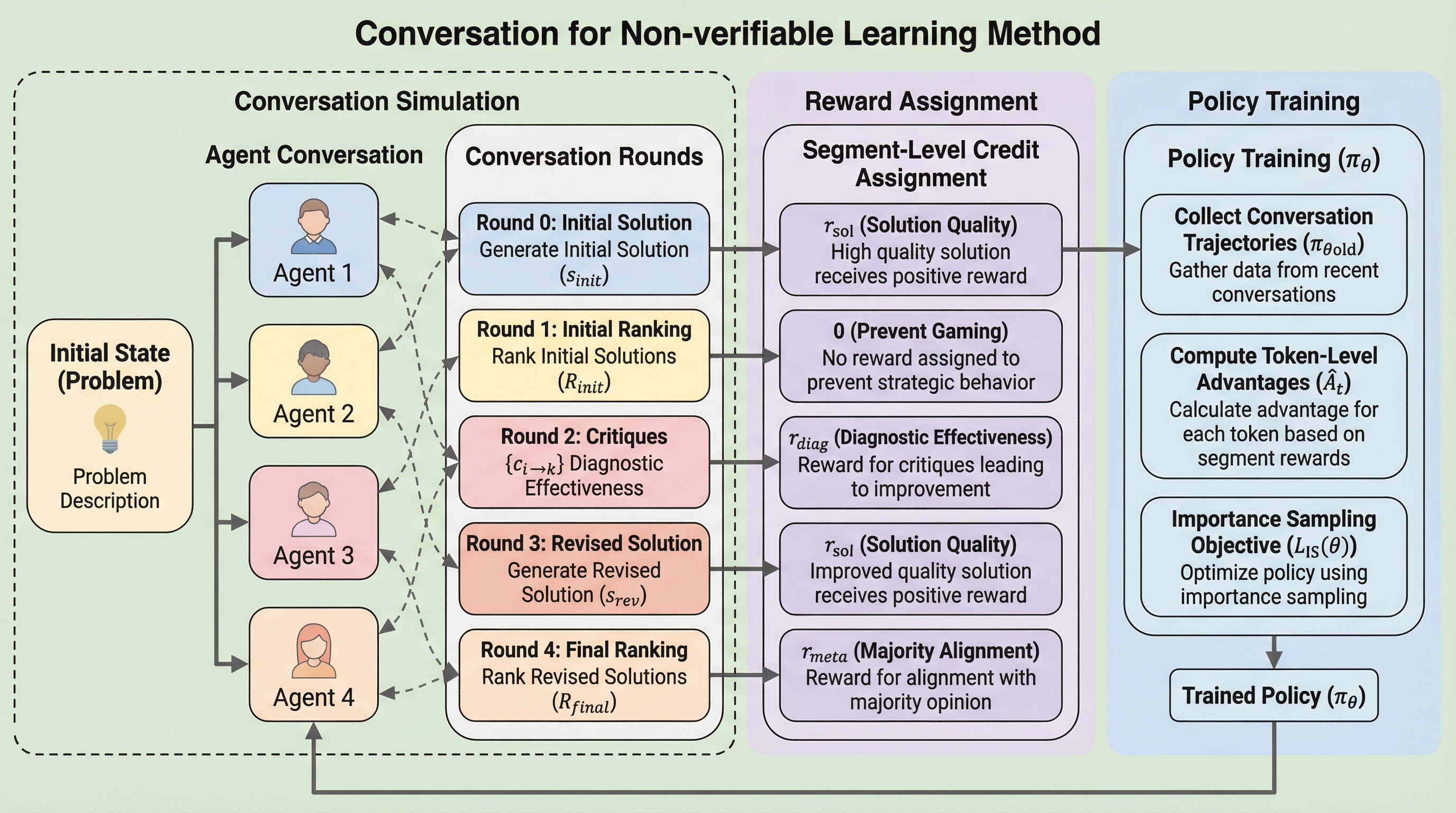
数学やプログラミングのような明確な正解がない「検証不可能なタスク」において、大規模言語モデル(LLM)が自身の評価能力を自律的に向上させるための新しい学習フレームワーク「CoNL」が提案されました。
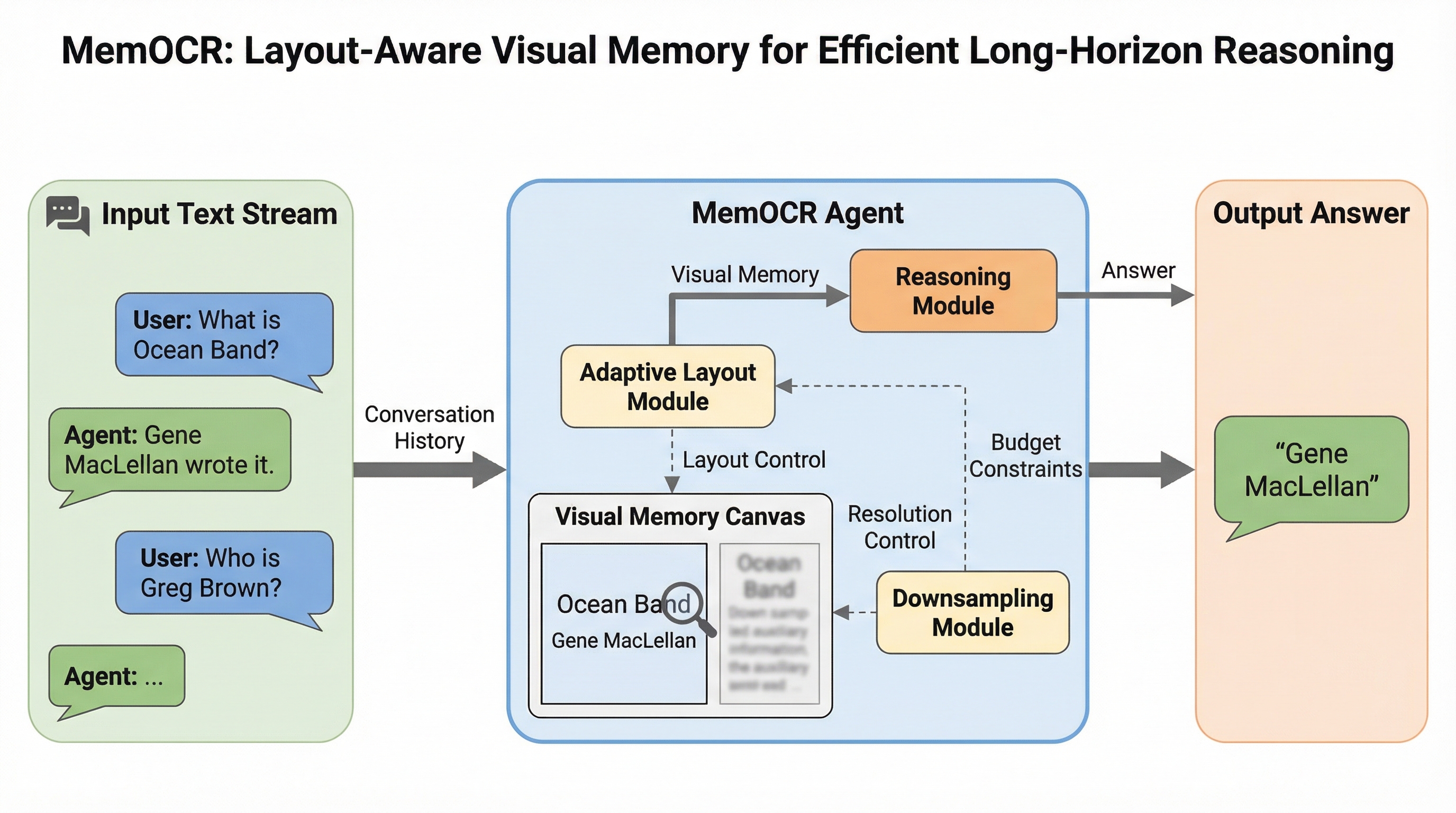
大規模言語モデル(LLM)エージェントの長期推論において、従来のテキスト形式のメモリは情報の重要度に関わらず一律のトークンを消費するため、限られたコンテキスト窓を低価値な詳細情報で浪費するという課題がありました。
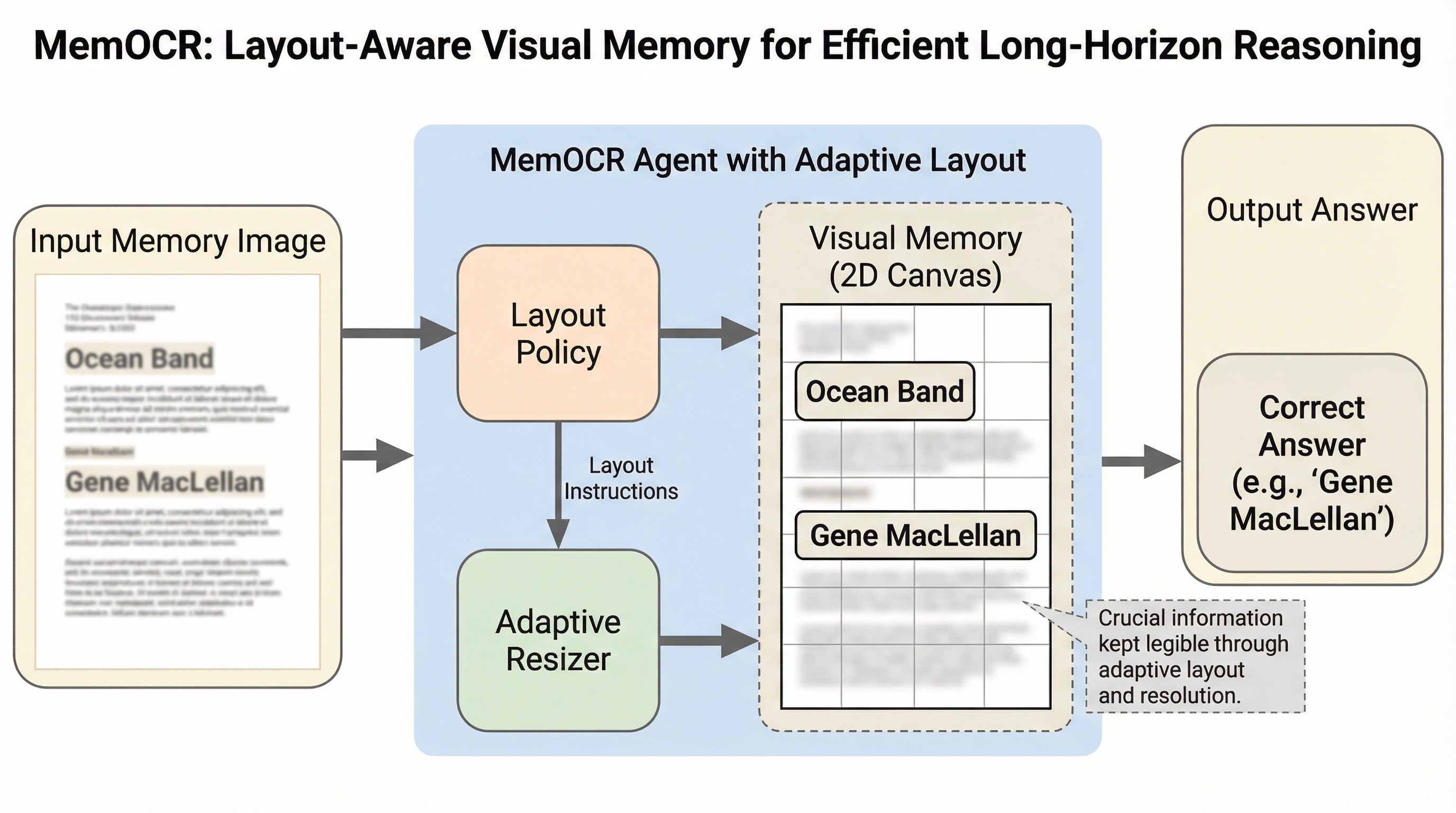
従来のテキストベースのメモリシステムは、情報の重要度に関わらず全てのトークンが均一なコストを消費する「均一な情報密度」という制約を抱えており、限られた予算内で重要な証拠と補助的な詳細が競合する課題がありました。
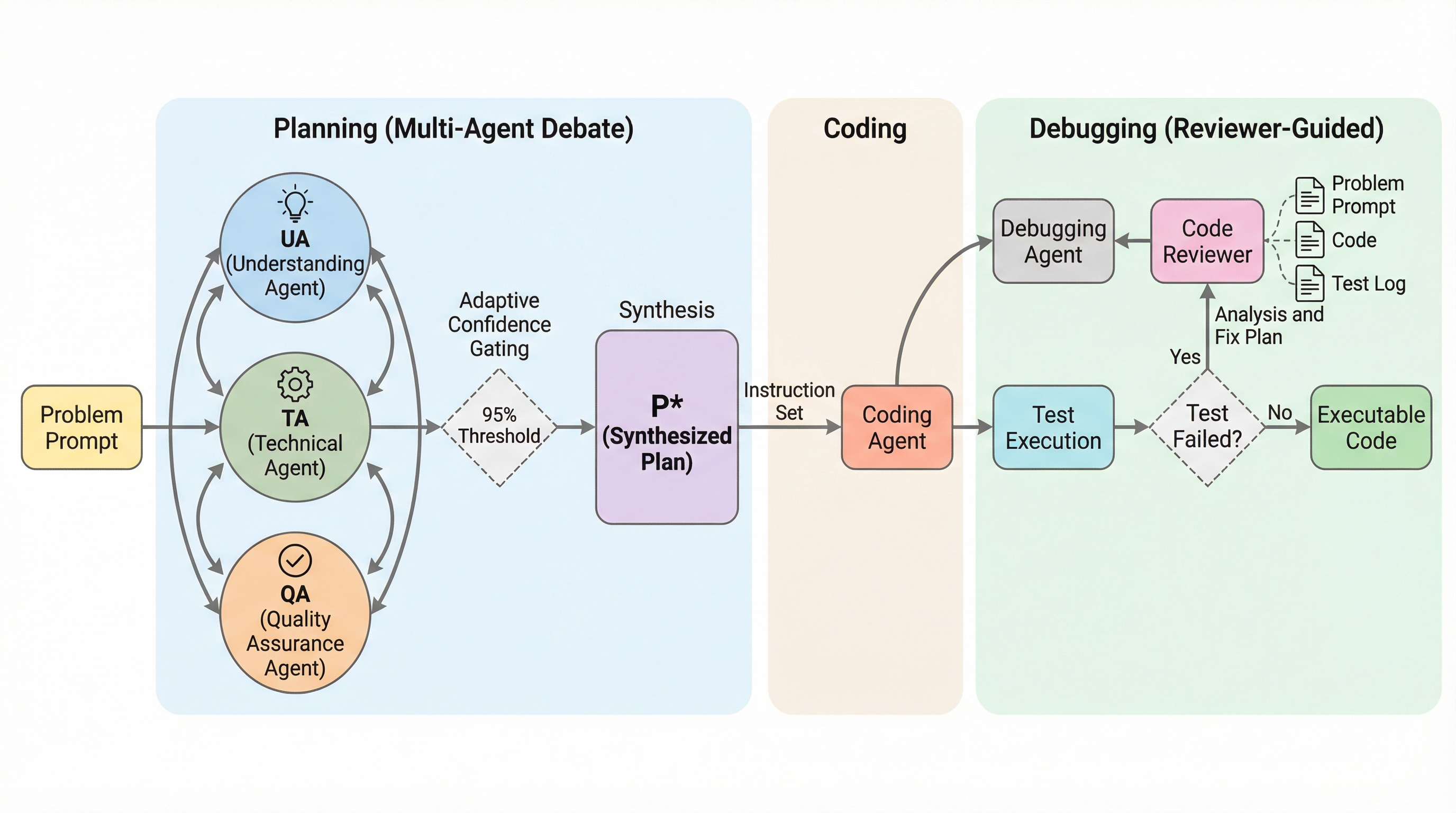
DebateCoderは、Pangu-1Bのような小規模言語モデル(SLM)が複雑なプログラミングタスクで直面する「推論のボトルネック」や、自身の誤りを修正できずに停滞する「失敗ループ」を打破するために開発された、革新的なマルチエージェント協調フレームワークである。