検証不可能な学習のための対話:メタ評価を通じた自己進化型LLM
クリエイティブな執筆や倫理的推論といった正解が検証不可能なタスクにおいて、大規模言語モデルを訓練することは、客観的な正解ラベルが存在しないため非常に困難である。既存の「LLM-as-Judge」手法は評価者自身の能力やバイアスに性能が制限されるという課題を抱えていたが、本研究は他者の回答を改善させたかどうかで批判の質を測定する「診断的報酬」を導入した。 提案手法「CoNL」は、マルチエージェントの自己対話を通じて生成、評価、メタ評価を統合するフレームワークであり、外部の評価者や正解データに頼ることなく、対話の力学から得られる信号を用いてモデルを自律的に進化させる。5つのベンチマークを用いた実験の結果、CoNLは従来の自己報酬型手法を最大8.3パーセント上回る性能向上を達成し、学習の安定性を維持しながら正解報酬を用いた強化学習に近い成果を収めた。 この手法は、ピアレビューのような相互監視のプロセスを学習信号に変えることで、検証不可能な領域におけるモデルの限界を突破し、より高品質で信頼性の高い回答の生成を可能にするものである。従来の自己報酬型モデルが陥りがちだった回答の肥大化(冗長性バイアス)を抑制し、評価能力そのものを訓練可能なスキルとして定義した点に大きな革新性がある。
TL;DR(結論)
クリエイティブな執筆や倫理的推論といった正解が検証不可能なタスクにおいて、大規模言語モデルを訓練することは、客観的な正解ラベルが存在しないため非常に困難である。既存の「LLM-as-Judge」手法は評価者自身の能力やバイアスに性能が制限されるという課題を抱えていたが、本研究は他者の回答を改善させたかどうかで批判の質を測定する「診断的報酬」を導入した。 提案手法「CoNL」は、マルチエージェントの自己対話を通じて生成、評価、メタ評価を統合するフレームワークであり、外部の評価者や正解データに頼ることなく、対話の力学から得られる信号を用いてモデルを自律的に進化させる。5つのベンチマークを用いた実験の結果、CoNLは従来の自己報酬型手法を最大8.3パーセント上回る性能向上を達成し、学習の安定性を維持しながら正解報酬を用いた強化学習に近い成果を収めた。 この手法は、ピアレビューのような相互監視のプロセスを学習信号に変えることで、検証不可能な領域におけるモデルの限界を突破し、より高品質で信頼性の高い回答の生成を可能にするものである。従来の自己報酬型モデルが陥りがちだった回答の肥大化(冗長性バイアス)を抑制し、評価能力そのものを訓練可能なスキルとして定義した点に大きな革新性がある。
なぜこの問題か
数学やプログラミングのようなタスクとは異なり、クリエイティブな文章作成、自由形式の対話、倫理的な意思決定といった分野は、客観的な正解ラベルが存在しない「検証不可能」なタスクに分類される。これらのタスクで大規模言語モデルを訓練する場合、教師あり微調整や強化学習といった標準的な手法は、検証可能な信号が欠如しているために機能しにくいという根本的な問題がある。このギャップを埋めるために人間からのフィードバックを用いた強化学習(RLHF)が標準となっているが、人間の注釈コストは極めて高く、モデルの急速な進化に合わせて大規模に拡張することが困難である。 代替案として、モデル自身に報酬を生成させる「LLM-as-Judge」手法が注目されているが、そこには評価者自身の質がボトルネックになるという限界が存在する。評価者が優れた解決策を認識できない場合、有用な学習信号を提供できず、回答の質よりも長さなどの表面的な特徴を好むといった評価バイアスが解消されないまま残ってしまう。…
核心:何を提案したのか
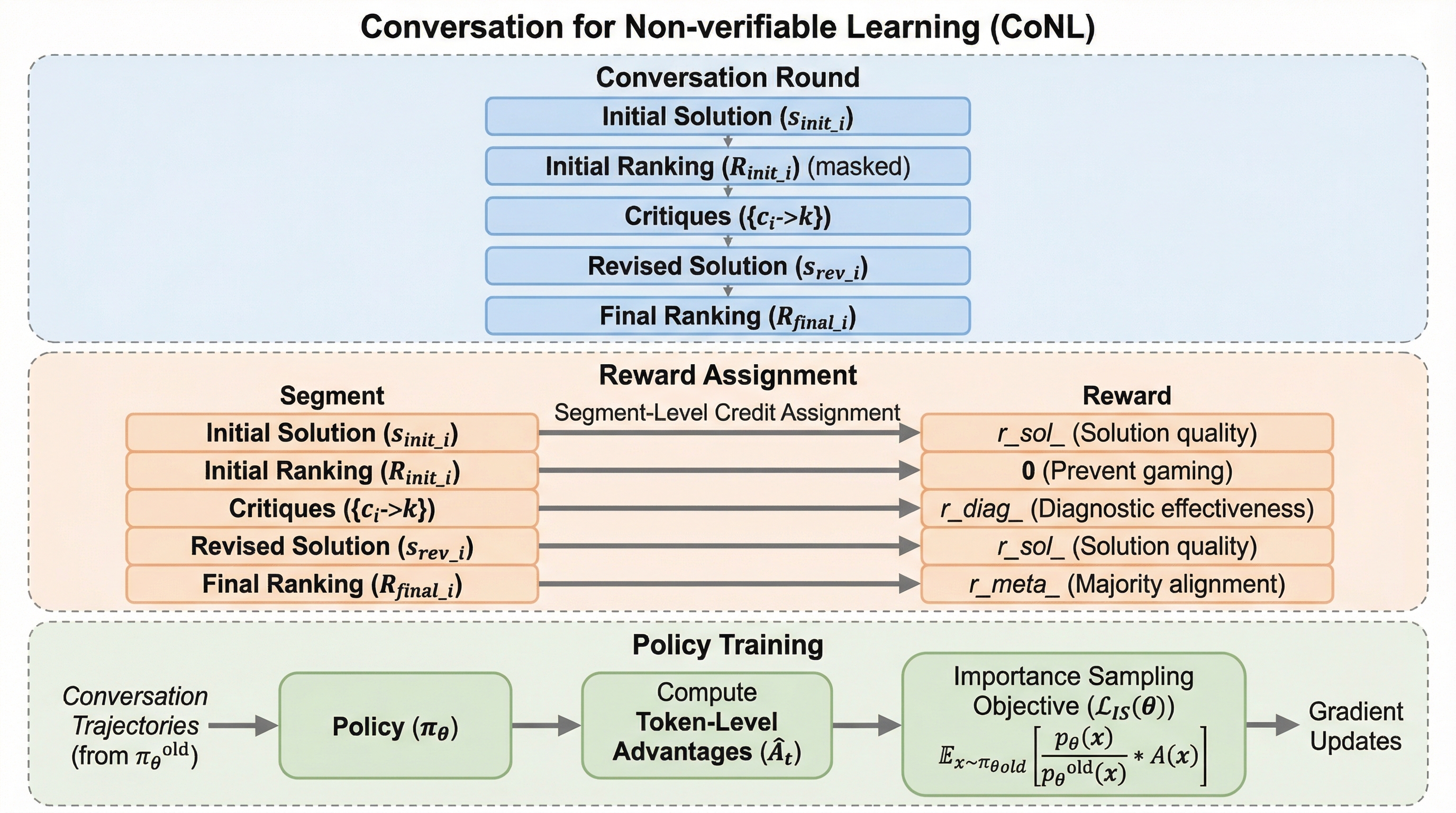
本研究は、生成、評価、メタ評価をマルチエージェントの自己対話を通じて統合するフレームワーク「CoNL(Conversation for Non-verifiable Learning)」を提案した。このアプローチの核心となる洞察は、批判の質は「それが他者の解決策を改善するのに役立ったかどうか」によって測定できるという点にある。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related