L$^3$:大規模ルックアップ層
L$^3$(Large Lookup Layer)は、従来のMixture-of-Experts(MoE)が抱えるハードウェア効率の低下や学習の不安定さを克服するために提案された、新しいスパースなデコーダ層のアーキテクチャである。
TL;DR(結論)
L$^3$(Large Lookup Layer)は、従来のMixture-of-Experts(MoE)が抱えるハードウェア効率の低下や学習の不安定さを克服するために提案された、新しいスパースなデコーダ層のアーキテクチャである。この手法は、トークナイザーの埋め込みテーブルが持つ「静的な疎性」という利点をデコーダ層へと拡張し、特定のトークンIDに対して固定された複数の埋め込みベクトルを割り当て、それを現在の文脈(隠れ状態)に基づいて動的に集約することで、計算コストを抑えつつ極めて高い表現力を実現している。最大26億の活性パラメータを用いた大規模な事前学習実験の結果、L$^3$は同等の計算量を持つ密なモデルや従来のMoEモデルを言語モデリングの精度および多様な下流タスクの性能において一貫して上回り、さらにCPUオフロードやプリフェッチといったシステム的な最適化を容易にすることで、限られた計算リソースでの大規模モデル運用に新たな可能性を提示した。
なぜこの問題か
現代の言語モデルの性能向上において、モデルの総パラメータ数を増やしつつ、実際の計算に使用する「活性パラメータ数」を一定に保つ「スパース性(疎性)」の導入は、計算効率と精度の両立を図るための鍵となっている。その主流であるMixture-of-Experts(MoE)は、入力トークンごとに異なる「専門家(エキスパート)」を選択する動的なルーティングによって高い性能を達成してきたが、この動的な仕組みがシステム上の大きな負担となっている。具体的には、どの専門家が選ばれるかが実行時まで確定しないため、ハードウェアの計算リソースを最大限に活用するための最適化が困難であり、特定の専門家に負荷が集中することを防ぐために「補助的な損失関数」を導入して学習を安定させる必要があるなど、設計が複雑になりやすい。また、メモリ節約のためにパラメータをCPUへ退避させるオフロード技術を適用しようとしても、次にどのパラメータが必要になるかを事前に予測できないため、通信のオーバーヘッドが無視できないレベルで発生し、推論速度の低下を招いてしまう。…
核心:何を提案したのか
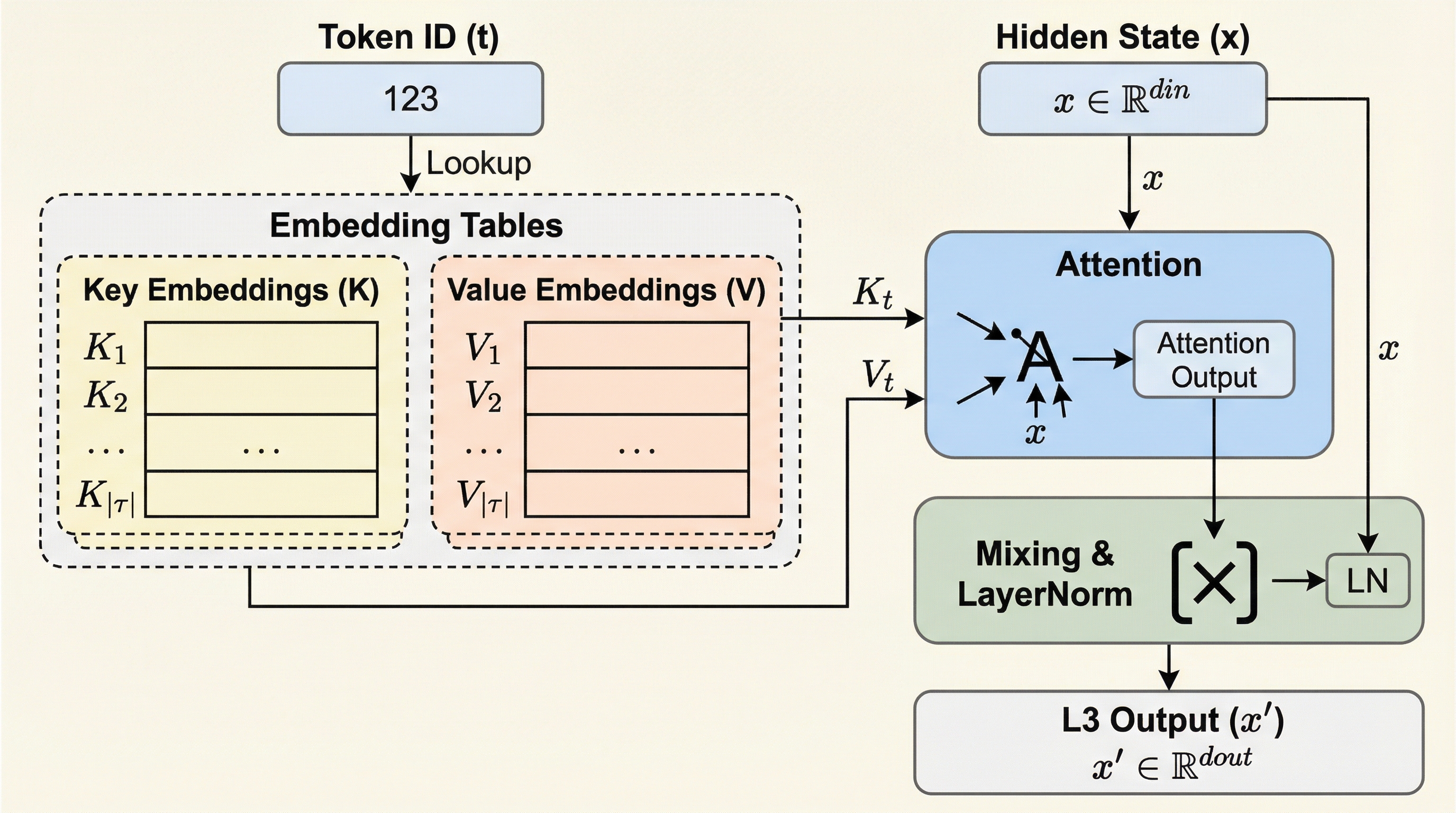
本研究では、従来の埋め込みテーブルの概念をデコーダ層の内部へと一般化した「Large Lookup Layer(L$^3$)」を提案している。L$^3$は、学習された膨大な埋め込みベクトルの集合を「ルックアップテーブル」として活用し、モデルが情報を効率的にキャッシュできるようにする新しいスパース性の形態である。この手法の核心は、静的なトークンベースのルーティングと、文脈に依存した集約プロセスを組み合わせた点にある。具体的には、特定のトークンIDに対してあらかじめ固定された複数の埋め込み(キーと値のペア)を割り当てておき、それらを現在の隠れ状態(文脈)とのアテンション計算によって重み付けして統合する。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related