検証不可能な学習のための対話:メタ評価を通じた自己進化するLLM
数学やプログラミングのような明確な正解がない「検証不可能なタスク」において、大規模言語モデル(LLM)が自身の評価能力を自律的に向上させるための新しい学習フレームワーク「CoNL」が提案されました。
TL;DR(結論)
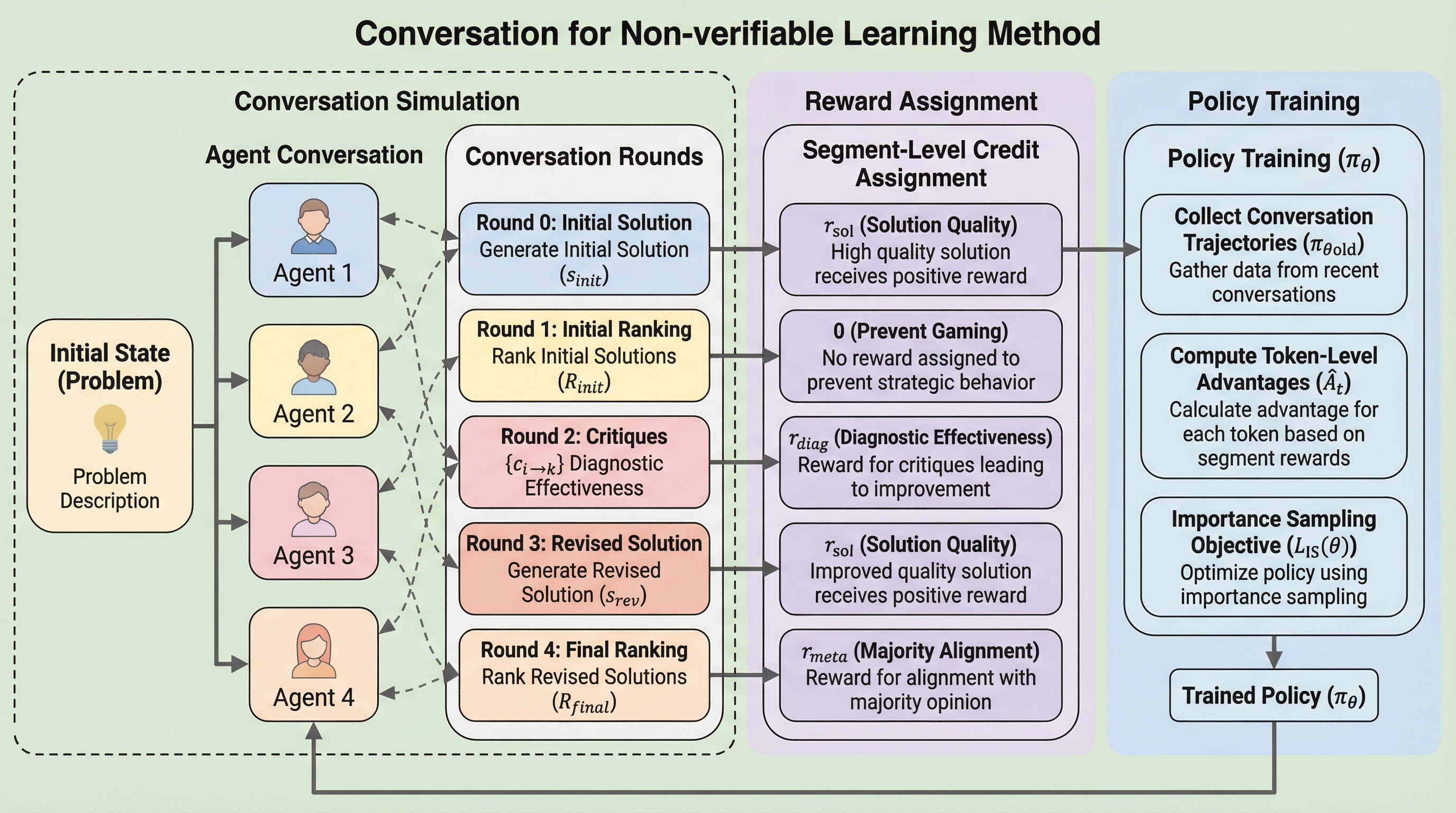
数学やプログラミングのような明確な正解がない「検証不可能なタスク」において、大規模言語モデル(LLM)が自身の評価能力を自律的に向上させるための新しい学習フレームワーク「CoNL」が提案されました。 この手法は、複数のエージェントが対話を通じて互いの回答を批判・修正し、その批判が他者の回答を実際に改善させた場合に報酬を与える「診断的報酬」という仕組みを導入することで、外部の正解ラベルや人間の介入なしに生成と評価の質を同時に高めます。 実験の結果、既存の自己報酬型モデルで問題となっていた「回答が不必要に長くなるバイアス」を抑制しつつ、主要な推論ベンチマークにおいて最大8.3ポイントの性能向上を達成し、正解ラベルを用いた学習に匹敵する成果を示しました。
なぜこの問題か
大規模言語モデル(LLM)の訓練において、数学の問題やコードの生成といったタスクは、出力が正しいかどうかを客観的なルールやテストで検証できるため、比較的学習が進めやすい領域です。しかし、クリエイティブな文章作成、オープンエンドな対話、あるいは複雑な倫理的判断といった「検証不可能なタスク」においては、何が「正解」であるかという客観的な基準が存在しません。これまで、こうした領域では人間の好みを反映させる強化学習(RLHF)が標準的な手法として用いられてきましたが、人間による評価は非常にコストが高く、モデルの規模が拡大し続ける現状において、人間がすべてのデータを評価し続けることはスケーリングの観点から限界に達しています。 この課題を解決するために、LLM自身を評価者として利用する「LLM-as-Judge」というアプローチが注目されていますが、ここには根本的なボトルネックが存在します。それは、評価者としてのモデルの性能が、そのモデル自身の初期の品質に強く依存してしまうという点です。もしモデルが優れた回答と劣った回答を正確に見分ける能力を持っていなければ、自分自身に対して誤った学習信号を送ることになり、結果として性能が向上しません。…
核心:何を提案したのか
本研究では、生成、評価、および評価能力そのものを改善する「メタ評価」のプロセスを、マルチエージェントによる自己対戦を通じて統合する新しいフレームワーク「CoNL(Conversation for Non-verifiable Learning)」を提案しています。このアプローチの核心的な洞察は、批判の質を「その批判が他者の解決策を改善させるのにどれだけ役立ったか」という客観的な変化によって測定できるという点にあります。これは、中央集権的な絶対者が正解を定義するのではなく、複数の参加者がコンテンツを生成し、互いに査読と修正を繰り返すことで全体の品質を担保するウィキペディアの共同編集モデルに近い考え方です。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related