L$^3$: 大規模ルックアップ層
L3(Large Lookup Layer)は、従来のMixture-of-Experts(MoE)が抱える動的ルーティングに伴うハードウェア効率の低下や学習の不安定さを解消するために提案された、新しいスパースアーキテクチャである。
TL;DR(結論)
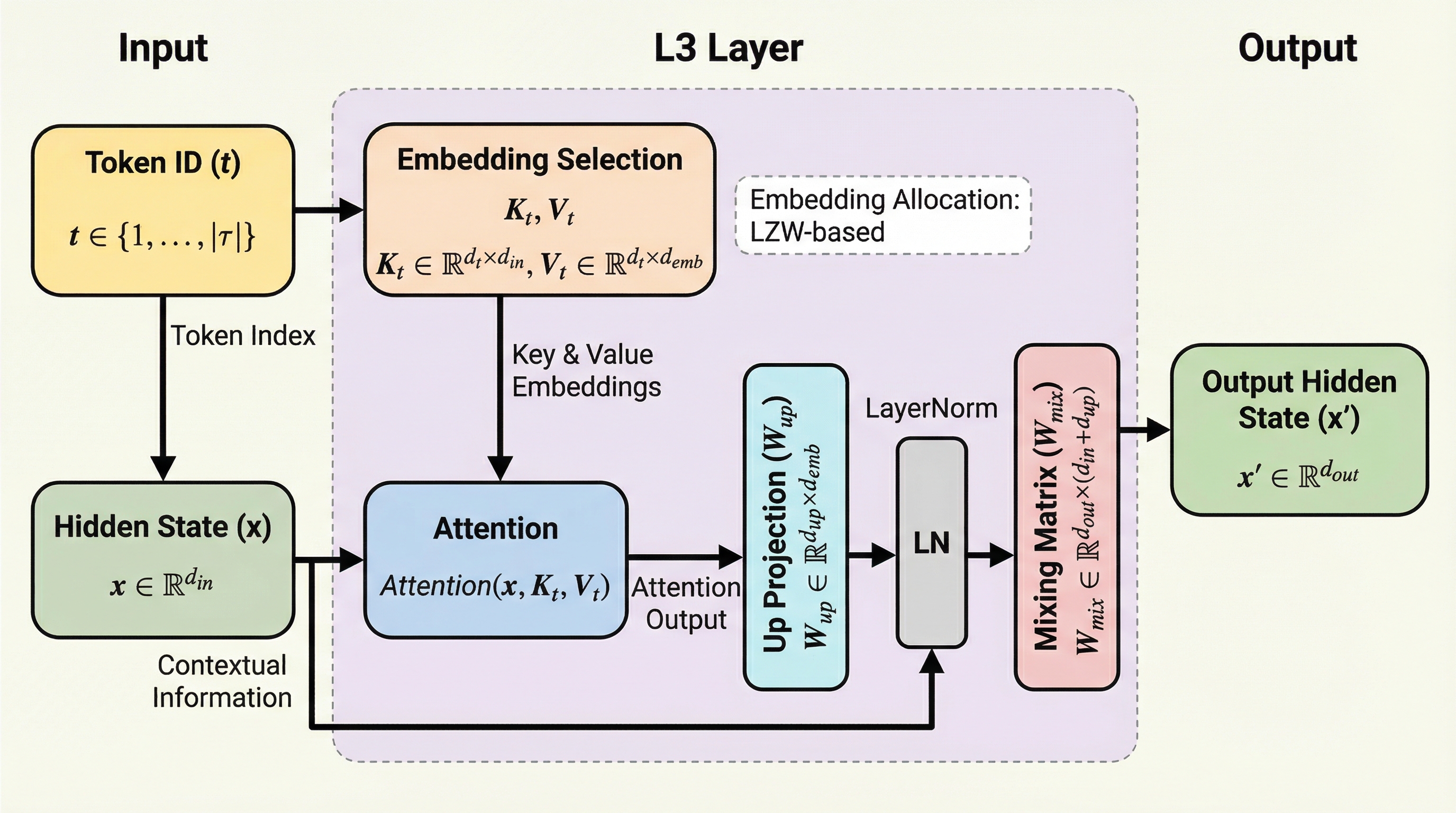
L3(Large Lookup Layer)は、従来のMixture-of-Experts(MoE)が抱える動的ルーティングに伴うハードウェア効率の低下や学習の不安定さを解消するために提案された、新しいスパースアーキテクチャである。トークンIDに基づいた静的なルーティングと、現在の隠れ状態を用いたコンテキスト依存の埋め込み集約を組み合わせることで、計算に必要なパラメータを事前に特定し、効率的なメモリ管理と高速な推論を実現している。 情報理論に基づいたLZW(Lempel-Ziv-Welch)アルゴリズムの変種を用いて、トークンの出現頻度や文脈上のパターンに応じて埋め込みを最適に配分する手法を導入しており、これにより言語モデルの性能を最大限に引き出すことに成功している。 2.6Bのアクティブパラメータを持つモデルを用いた大規模な実験において、L3は同等の計算量を持つ密なモデルやMoEモデルを一貫して上回る性能を示し、CPUへのオフロードや高速なトレーニングを可能にするシステム親和性の高さも実証された。
なぜこの問題か
現代の言語モデル開発において、モデルのスパース性を高めることは、計算資源を効率的に活用しながら表現能力を向上させるための極めて重要な手段となっている。一般的に、このスパース性はMixture-of-Experts(MoE)アーキテクチャによって実現されており、各トークンを動的に特定の「エキスパート」層へとルーティングする手法が主流である。しかし、MoEにはいくつかの重大な欠点が存在する。まず、動的なルーティングはハードウェア効率を低下させる要因となる。トークンがどのエキスパートに送られるかは、計算がその層に到達するまで確定しないため、パラメータのプリフェッチや効率的なオフロードが困難である。また、MoEの学習は不安定になりやすく、特定の専門家に負荷が集中する「崩壊」を防ぐために、補助的な損失関数を導入するなどの複雑な調整が必要となる。さらに、大規模なMoEモデルは数兆個のパラメータを持つことがあり、これらを複数のデバイスに分散して保持するための高度なシャーディング技術が求められる。負荷分散が不適切な場合、デバイスの利用率が低下し、モデルの品質に悪影響を及ぼす可能性もある。…
核心:何を提案したのか
本研究で提案されたL3(Large Lookup Layer)は、トークナイザーの埋め込みテーブルという概念を一般化し、デコーダー層の内部で機能するように設計された新しいスパースレイヤーである。L3の核心は、トークン固有の膨大な埋め込みの集合を学習可能なルックアップテーブルとして保持し、モデルが情報を効率的にキャッシュできるようにすることにある。L3の最大の特徴は、MoEのようなコンテキスト依存の動的ルーティングではなく、トークンIDに基づいた「静的なルーティング」を採用している点である。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related