MemOCR:効率的な長期推論のためのレイアウトを考慮した視覚メモリ
大規模言語モデル(LLM)エージェントの長期推論において、従来のテキスト形式のメモリは情報の重要度に関わらず一律のトークンを消費するため、限られたコンテキスト窓を低価値な詳細情報で浪費するという課題がありました。
TL;DR(結論)
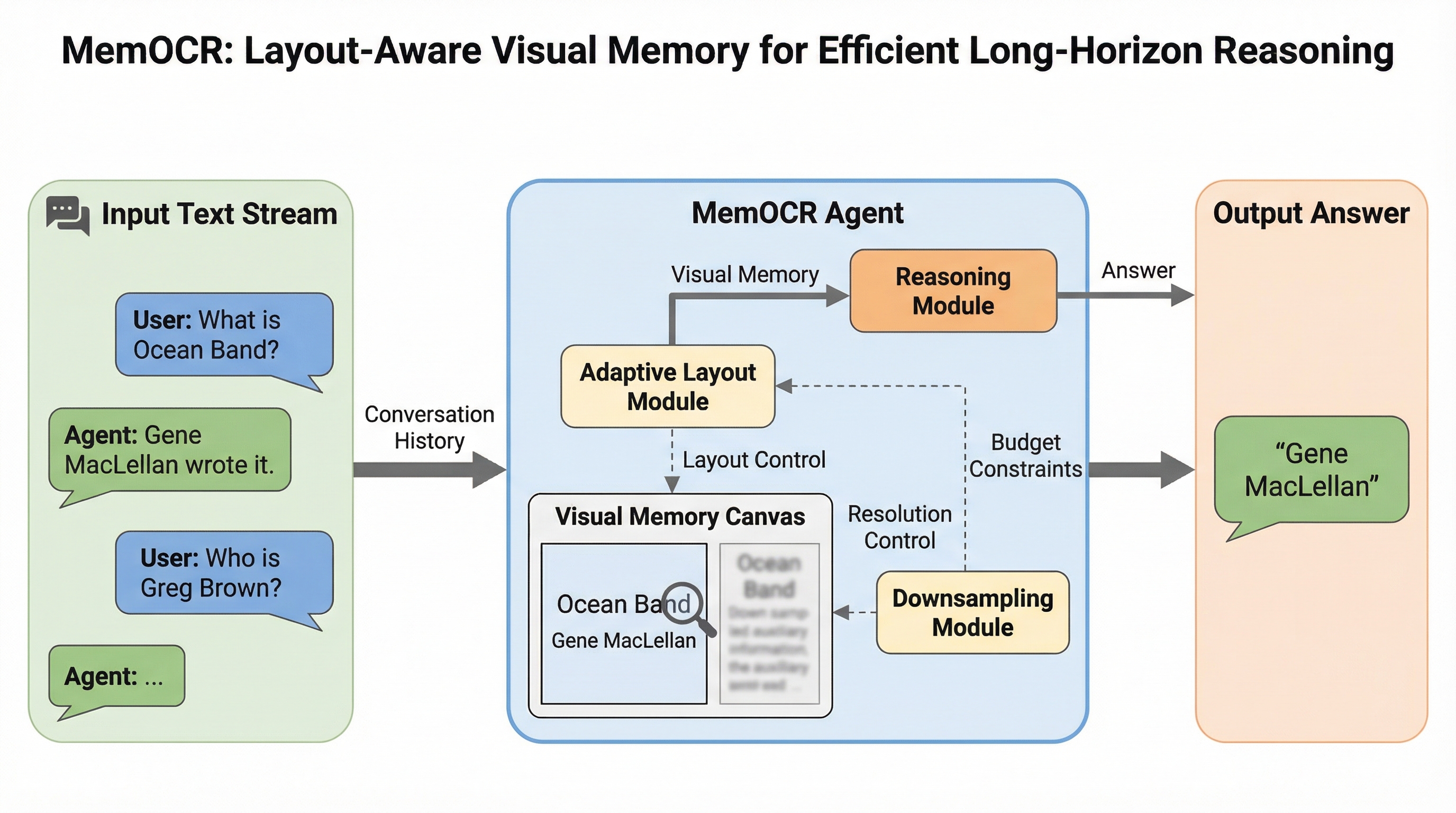
大規模言語モデル(LLM)エージェントの長期推論において、従来のテキスト形式のメモリは情報の重要度に関わらず一律のトークンを消費するため、限られたコンテキスト窓を低価値な詳細情報で浪費するという課題がありました。本研究が提案する「MemOCR」は、履歴をリッチテキスト形式で管理し、それを画像としてレンダリングすることで、視覚的なレイアウトを通じて情報の密度を適応的に制御するマルチモーダルメモリモデルです。検証の結果、MemOCRは極めて厳しい予算制約下でも重要な証拠を保持し続け、従来のテキスト手法と比較して約8倍のコンテキスト利用効率を達成し、長期的な推論タスクにおいて高い堅牢性と精度を示しました。
なぜこの問題か
大規模言語モデル(LLM)の急速な進化により、自律的なエージェントが複雑で長期的なタスクを処理することが可能になりましたが、蓄積される膨大な対話履歴がコンテキスト窓の物理的な制限を超えてしまうという根本的なボトルネックが存在しています。長期的な推論において、エージェントは過去の情報の何を残し、何を現在の意思決定のために取り出すかを常に判断しなければなりませんが、これは限られたトークン数という「予算」をいかに効率的に配分するかという問題に帰結します。既存のアプローチの多くはテキスト形式でメモリを保持しますが、これには「情報の密度が均一である」という固有の限界があります。 テキストベースのメモリでは、意味的な重要度に関わらず、すべてのトークンが同じ単位の予算を消費するため、重要な証拠を保持しようとすると、それを説明するための補助的な詳細情報にも比例したトークンを費やすことになります。このように、情報の重要度に応じてサンプリング率を柔軟に変更できないテキストの線形なスケーリング特性が、限られた予算内での効率的な推論を妨げる要因となっていました。…
核心:何を提案したのか
本研究では、メモリの表現形式を従来の1次元のテキストストリームから、2次元の視覚的メモリへと転換することを提案しています。このアプローチの核心は、視覚的なレイアウトを通じて「適応的な情報密度」を実現することにあります。この手法の最大の利点は、エージェントが情報の視覚的な目立ちやすさ(サリエンス)を制御することで、限られた予算を非一様に配分できるようになる点です。重要な証拠は大きなフォントや太字、目立つ見出しなどのタイポグラフィを用いてレンダリングされ、一方で補助的な詳細は視覚的に小さく圧縮されます。 これにより、極めて少ない視覚的トークン数の中に、重要な情報を読み取り可能な状態で詰め込みつつ、大量のコンテンツを保持することが可能になります。この革新的な手法を実現するために開発されたのが「MemOCR」というマルチモーダルメモリモデルです。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related