HER: LLMロールプレイングのための人間らしい推論と強化学習
HER(Human Emulation Reasoning)は、LLMのロールプレイングにおいてキャラクターの内面的な思考を高度にシミュレートするための統合フレームワークであり、隠された三人称視点の「システム思考」と、公開される一人称視点の「ロール思考」を分離した二層構造の思考プロセスを導入しています。
TL;DR(結論)
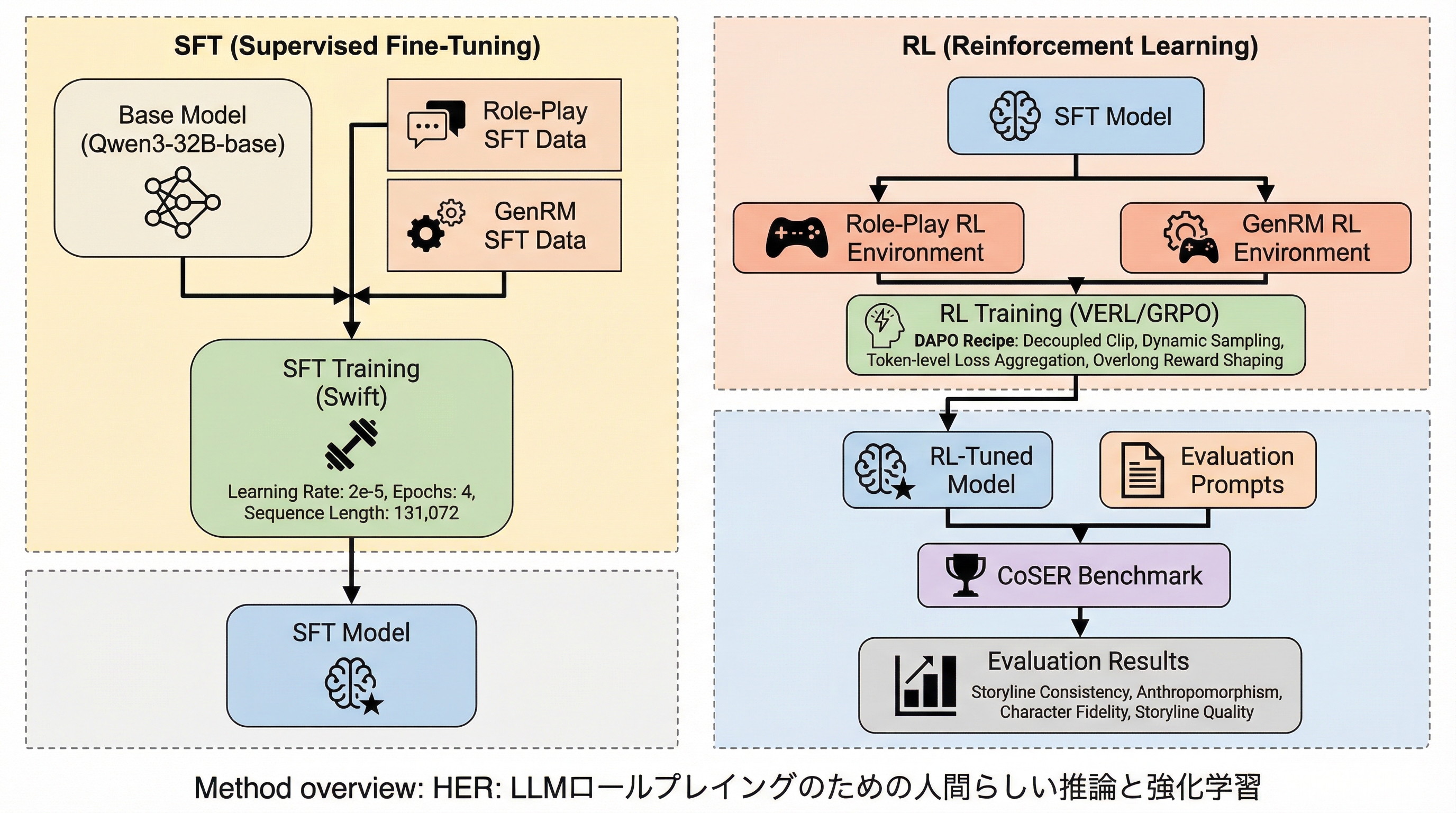
HER(Human Emulation Reasoning)は、LLMのロールプレイングにおいてキャラクターの内面的な思考を高度にシミュレートするための統合フレームワークであり、隠された三人称視点の「システム思考」と、公開される一人称視点の「ロール思考」を分離した二層構造の思考プロセスを導入しています。 高品質な推論データの不足と人間との好みの不一致を解消するため、既存の対話データから推論プロセスを逆生成するパイプラインを構築し、専門家が抽出した51の原則に基づく生成報酬モデル(GenRM)を用いた強化学習によってモデルを最適化しています。 Qwen3-32Bをベースとした実験では、CoSERベンチマークで30.26%、Minimax Role-Play Benchで14.97%の性能向上を達成し、キャラクターの性格維持や物語の一貫性、長期的な対話の質において従来のモデルを大きく上回る成果を示しています。
なぜこの問題か
現在のLLMを用いたロールプレイング、すなわち特定のペルソナをシミュレートする技術は、キャラクターの口調や特定の知識を模倣することには長けていますが、その行動の背後にある内面的な思考や動機をシミュレートすることには依然として大きな課題があります。既存のモデルは表面的な属性の再現に留まっており、複雑なシーンや長期的な対話において、キャラクターとしての意思決定や物語の展開を論理的に結びつける深い推論能力が不足しています。先行研究ではキャラクターの内面的な思考を含むデータセットも提案されていますが、それらは短文で浅い内容が多く、高度な認知シミュレーションを行うための教師データとしては不十分です。また、ロールプレイングの出力は自由度が高く、正解が一つに定まらない非検証的な性質を持つため、従来の強化学習で用いられる報酬モデルでは、発話の長さや特定の感情表現といった表面的な特徴に惑わされやすいという問題があります。 このような背景から、キャラクターの性格設定とシーンの制約を統合して次の行動を計画するスケーラブルな推論データの構築と、人間の主観的な好みに合致した文脈依存型の報酬信号の確立が急務となっています。…
核心:何を提案したのか
本研究では、LLMに構造化された思考能力を付与し、人間の好みに整合した強化学習を行うための統合フレームワーク「HER(Human Emulation Reasoning)」を提案しています。このフレームワークの最大の特徴は、人間の認知プロセスを模倣した「二層思考(Dual-layer Thinking)」の導入にあります。これは、キャラクターの制約やシーンを分析して行動を計画する三人称視点の「システム思考」と、キャラクター自身の感情や意図を表現する一人称視点の「ロール思考」を明確に分離するものです。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related