MemOCR: レイアウトを考慮した視覚的メモリによる効率的な長期推論
従来のテキストベースのメモリシステムは、情報の重要度に関わらず全てのトークンが均一なコストを消費する「均一な情報密度」という制約を抱えており、限られた予算内で重要な証拠と補助的な詳細が競合する課題がありました。
TL;DR(結論)
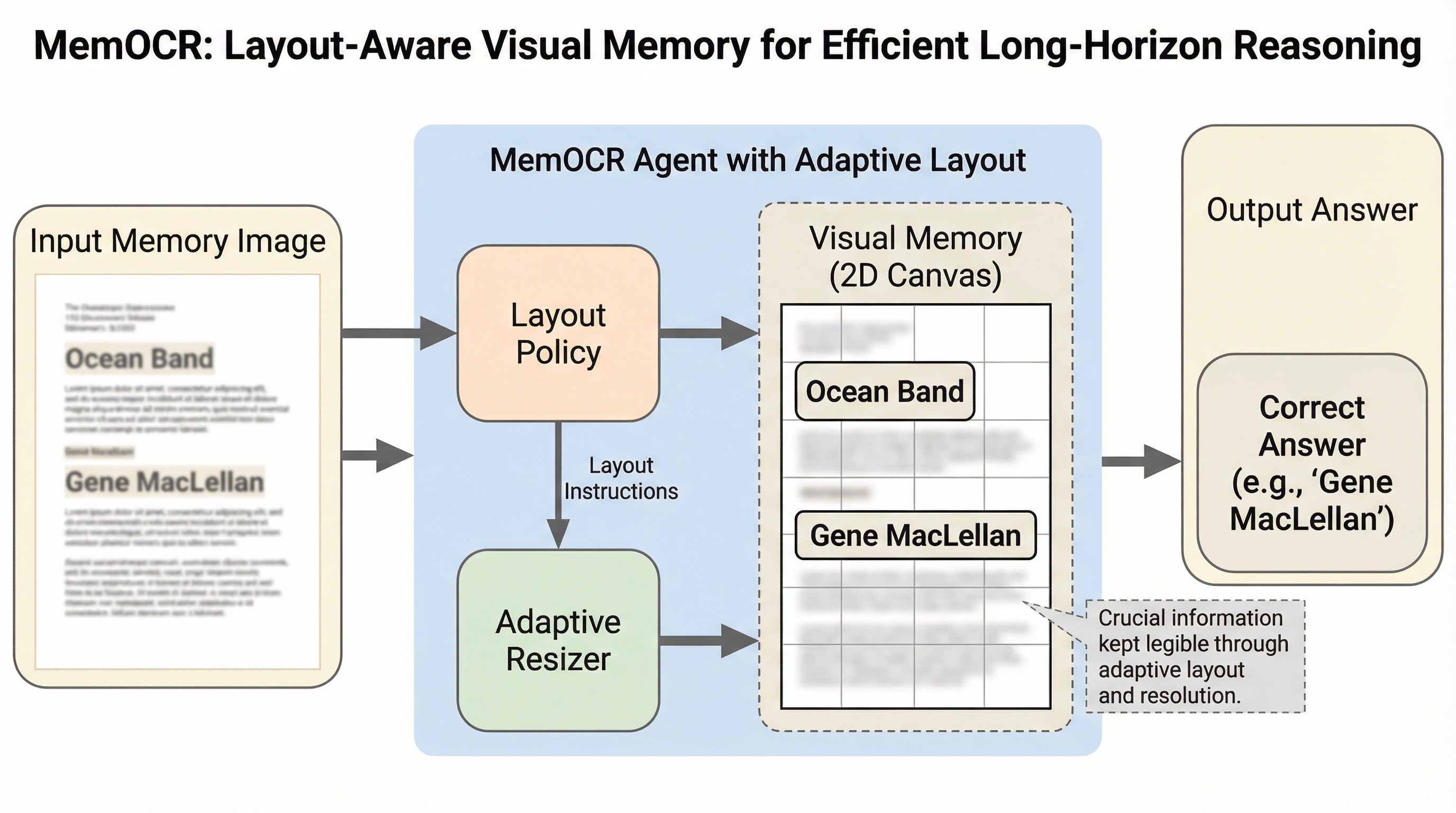
従来のテキストベースのメモリシステムは、情報の重要度に関わらず全てのトークンが均一なコストを消費する「均一な情報密度」という制約を抱えており、限られた予算内で重要な証拠と補助的な詳細が競合する課題がありました。 本研究が提案するMemOCRは、履歴を2次元の画像として保持する視覚的メモリを採用し、見出しや太字などのレイアウトを通じて情報の重要度に応じた「適応的な情報密度」を実現することで、重要な情報を優先的に保護しつつ詳細を大幅に圧縮することを可能にしました。 検証の結果、MemOCRは極端に少ない予算下でも高い推論能力を維持し、従来のテキストベースの手法と比較してコンテキストの利用効率を約8倍向上させ、100Kトークンに及ぶ超長文のコンテキストにおいても優れた性能を発揮することが確認されました。
なぜこの問題か
自律的なエージェントが複雑で長期的なタスクを遂行するためには、蓄積される膨大な対話履歴を限られたコンテキスト窓の中に効果的に圧縮して保持する能力が不可欠です。しかし、既存のメモリシステムの多くは履歴をテキストとして直列化して管理しており、そこにはトークンレベルのコストが情報の価値に関わらず一定であるという根本的な制約が存在します。この「均一な情報密度」という特性により、重要な証拠を保持しようとすると、それに付随する膨大な補助的詳細も同様のコストで保持せざるを得ず、貴重なコンテキスト予算が浪費されてしまいます。テキスト形式では、より多くの詳細を保持しようとすればトークン数が線形に増加するため、情報の重要度に応じてサンプリング密度を柔軟に変更することが困難であるという課題がありました。 既存のアプローチには、生の履歴をそのまま保持する手法と、要約を作成する手法の2つが主に存在します。前者は元の詳細を保持できますが、冗長な情報やノイズが含まれやすく、すぐにコンテキスト予算を使い果たしてしまいます。…
核心:何を提案したのか
本研究では、メモリの表現形式を従来の1次元的なテキストストリームから、2次元の視覚的メモリへと転換する「MemOCR」というマルチモーダルメモリモデルを提案しています。MemOCRの核心的なアイデアは、視覚的なレイアウトを利用して情報の密度を適応的に制御することにあり、これにより限られたコンテキスト予算内での長期推論能力を大幅に向上させています。具体的には、重要な証拠を大きなフォントや目立つ見出し、太字などのタイポグラフィを用いてレンダリングし、補助的な詳細は小さく配置することで、視覚的な優先順位を明示的に割り当てます。このアプローチにより、テキストの単語数に縛られることなく、重要な情報は高い解像度で維持し、重要度の低い情報は積極的に圧縮するという非一様な予算配分が可能になります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related