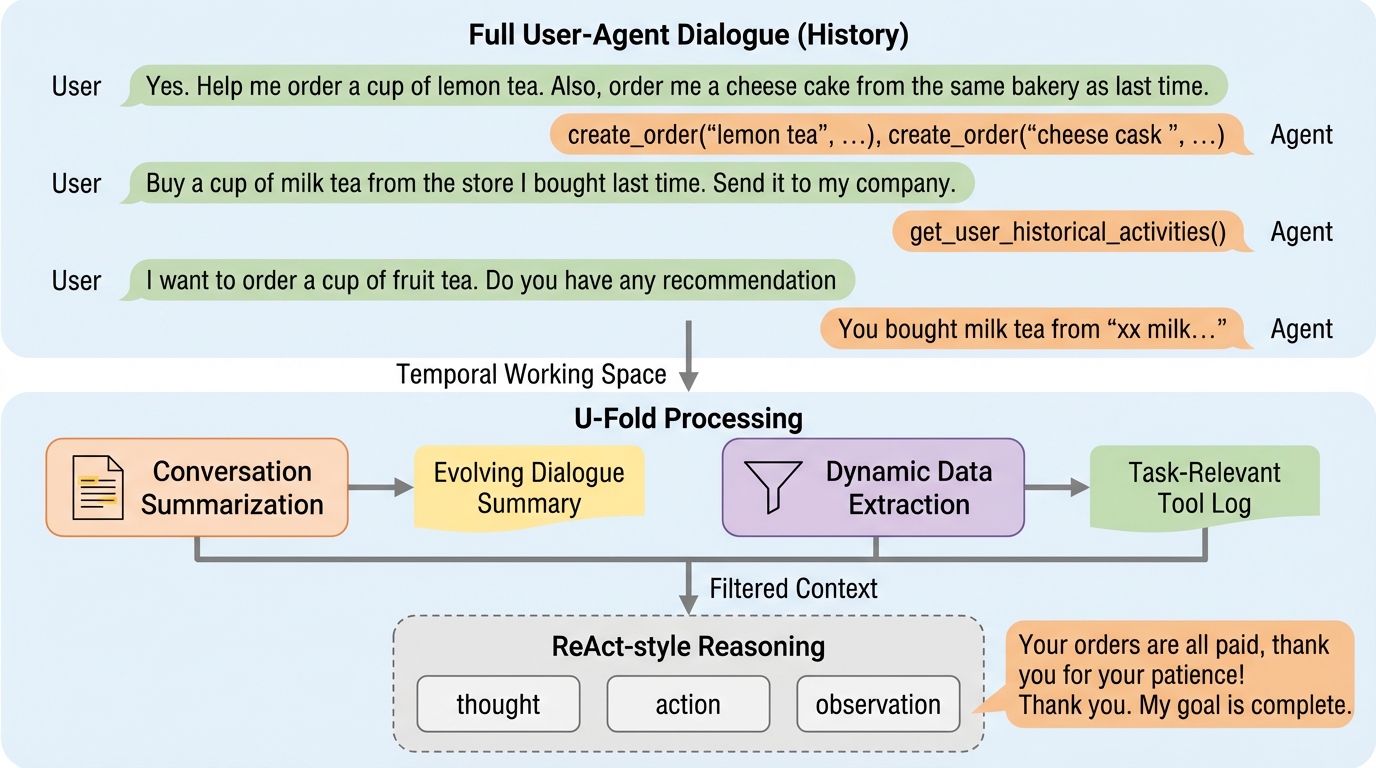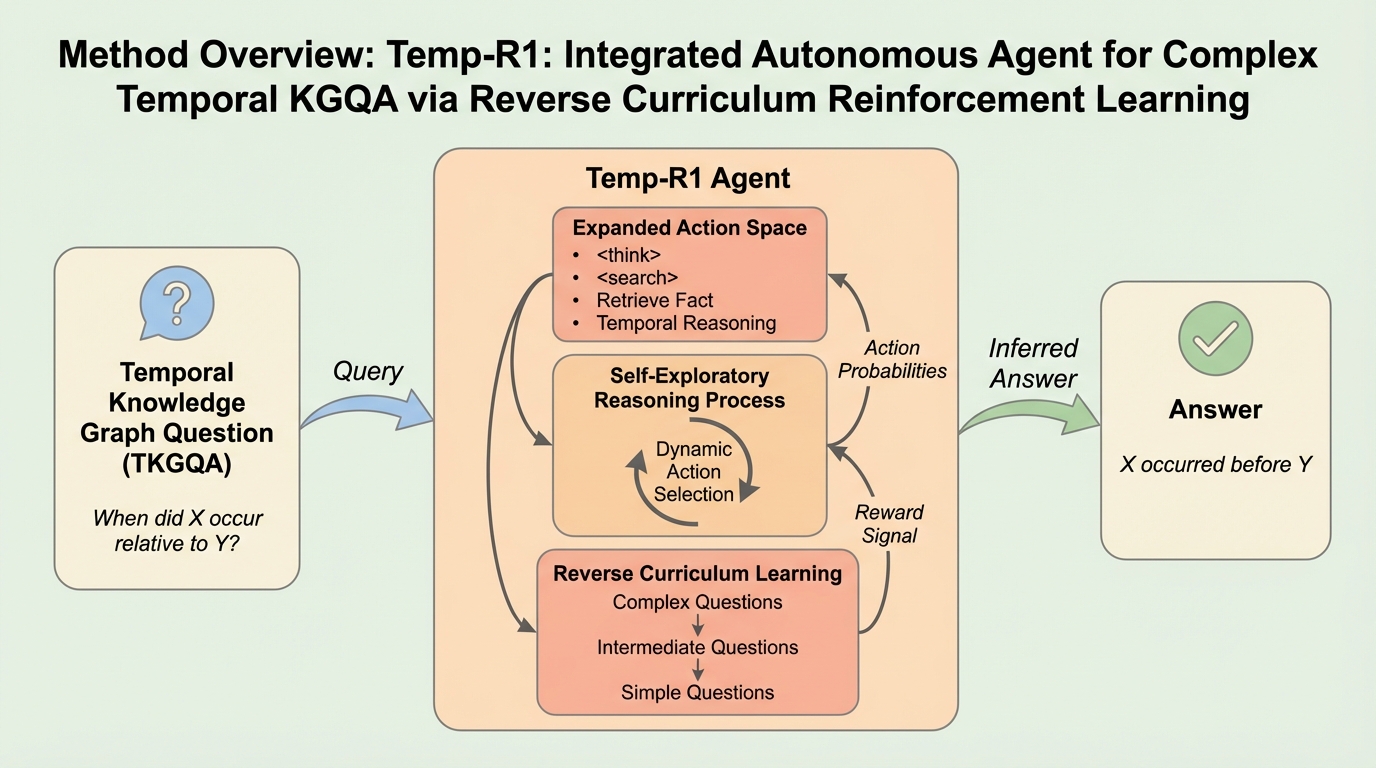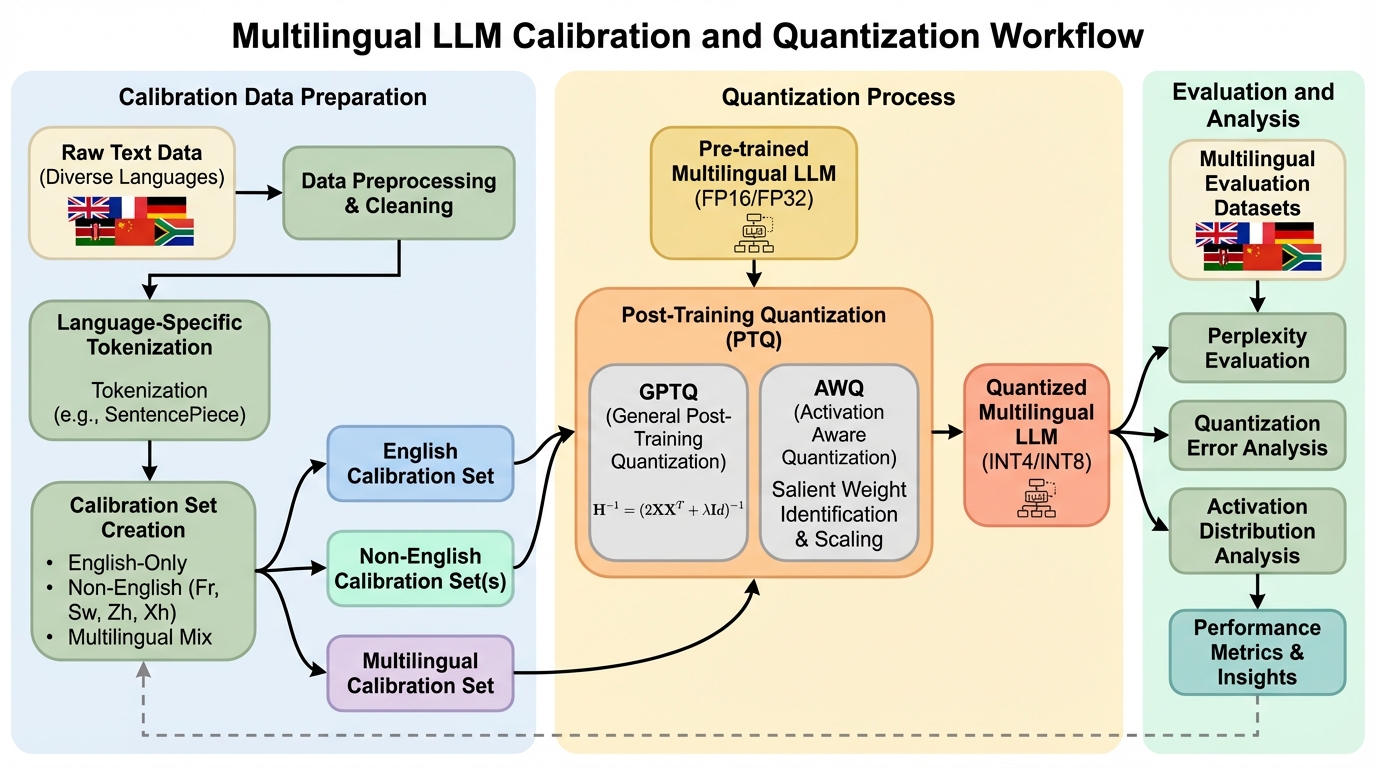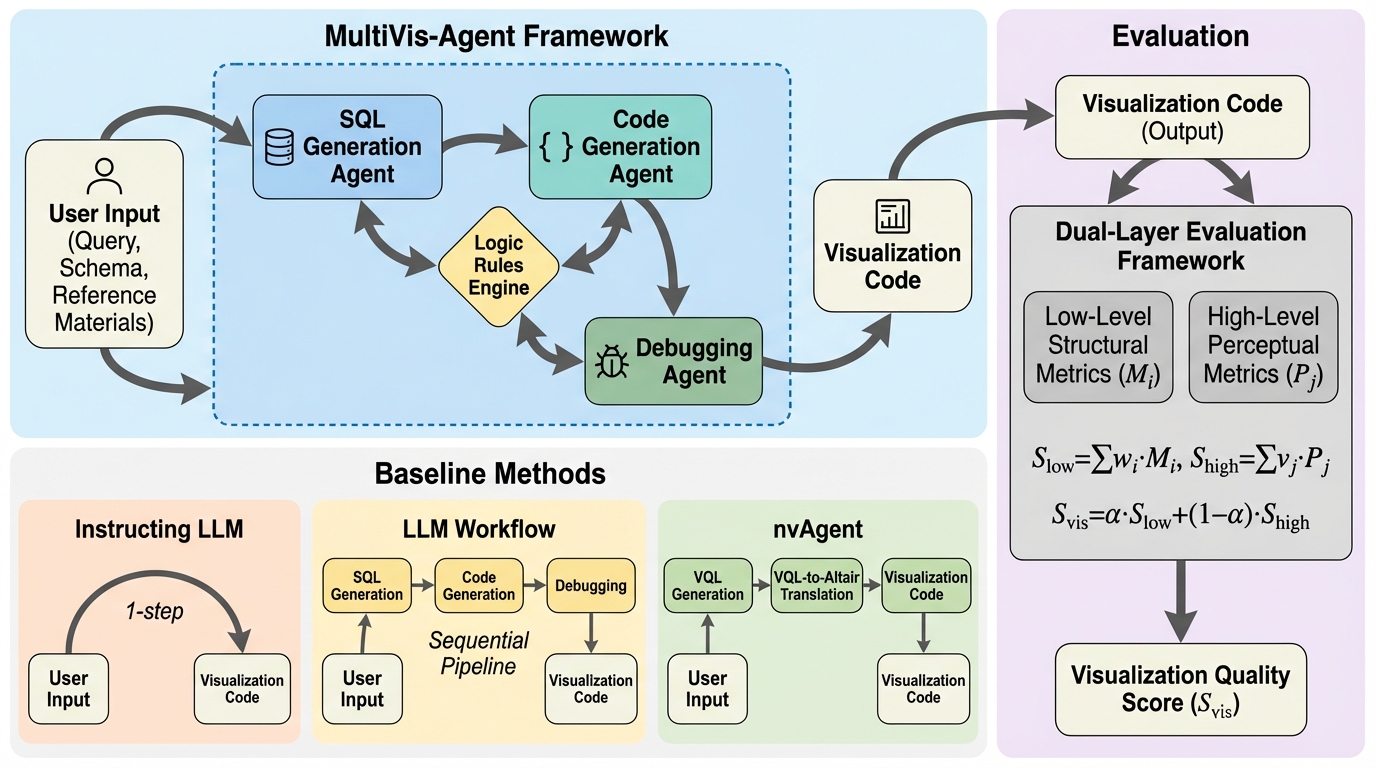
思考強化型関数呼び出し:埋め込み推論によるLLMパラメータ精度の向上
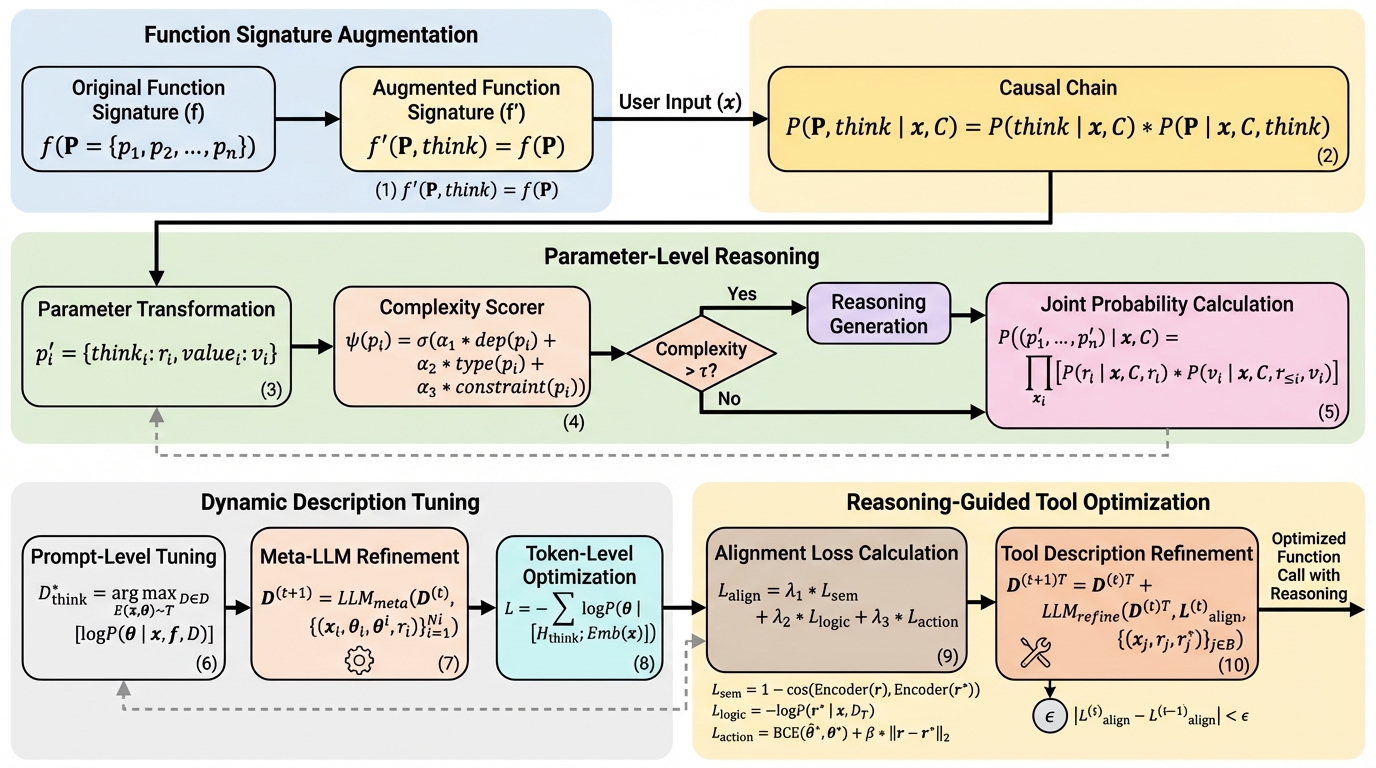
本研究は、大規模言語モデル(LLM)の関数呼び出しにおいて、関数の引数(パラメータ)ごとに明示的な推論プロセスを組み込む新フレームワーク「TAFC」を提案した。 従来の関数呼び出しが抱えていた「パラメータ生成時の推論の不透明性」を解消するため、関数シグネチャに「think」パラメータを追加し、モデルが意思決定の根拠を記述してから値を生成する仕組みを導入している。 ToolBenchを用いた検証では、GPT-4oやLlama-3.1などの主要モデルにおいて、特に複雑な複数パラメータを持つ関数の生成精度と推論の整合性が大幅に向上し、小規模モデルでも顕著な改善が確認された。