英語を超えたキャリブレーション:より良い量子化多言語LLMのための言語多様性
大規模言語モデルの量子化において、従来の英語のみを用いたキャリブレーション手法が多言語モデルの性能を制限していることを明らかにし、非英語および多言語混合データセットを用いることで、モデル全体のパープレキシティを最大3.52ポイント改善できることを示した。 Llama3.1 8BやQwen2.
TL;DR(結論)
大規模言語モデルの量子化において、従来の英語のみを用いたキャリブレーション手法が多言語モデルの性能を制限していることを明らかにし、非英語および多言語混合データセットを用いることで、モデル全体のパープレキシティを最大3.52ポイント改善できることを示した。 Llama3.1 8BやQwen2.5 7Bを用いた実験の結果、評価対象の言語とキャリブレーション言語を一致させる「言語的アライメント」が個別言語の性能を最大化することを実証し、特に低リソース言語において英語ベースラインを大きく上回る精度を達成した。 量子化手法であるGPTQとAWQの特性を分析し、多言語データが語彙の多様性やアクティベーションの異常値をより適切に捉えることで、推論時の未知のデータに対する堅牢性を高め、特定の言語における極端な性能劣化を抑制できることを解明した。
なぜこの問題か
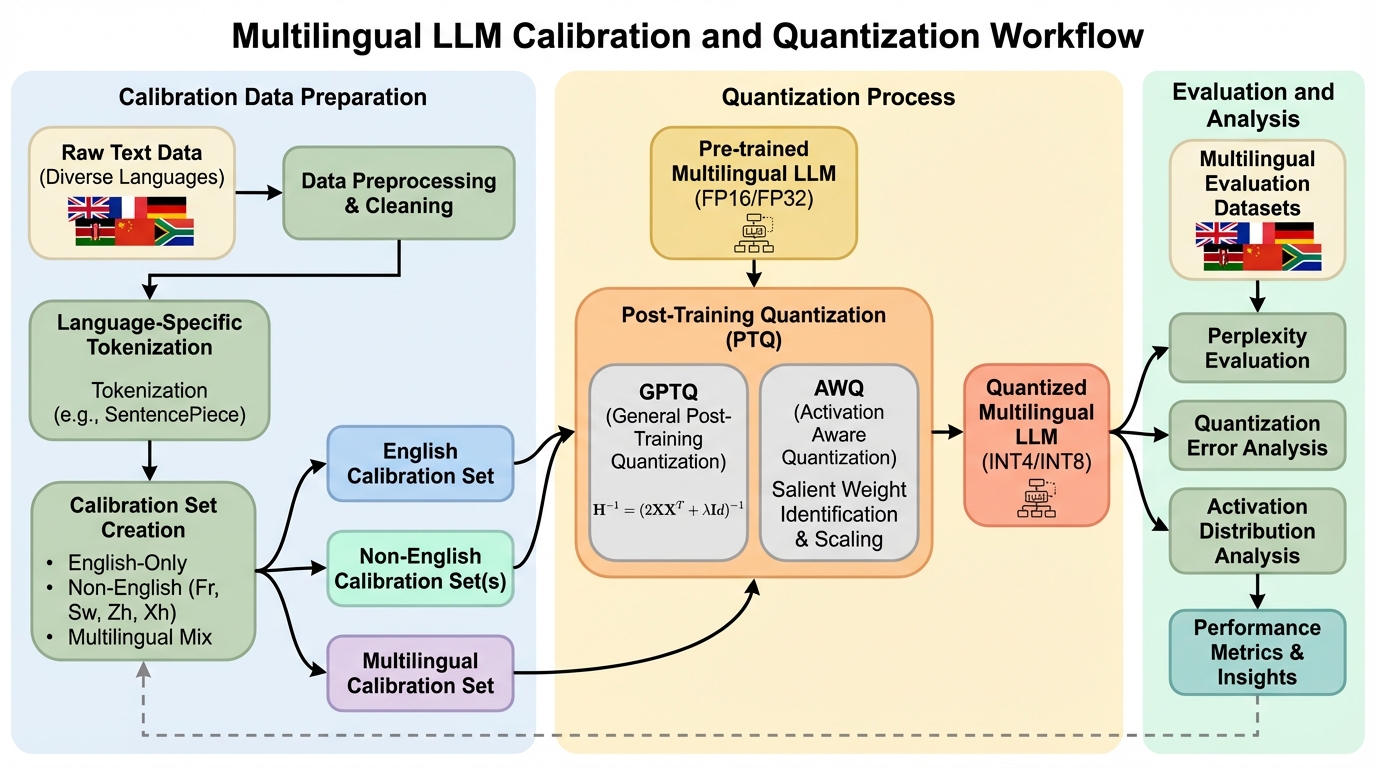
大規模言語モデル(LLM)の運用において、モデルのパラメータ精度を32ビット浮動小数点から4ビットなどの低精度に落とす「量子化」は、ストレージ容量の削減や計算コストの低減に極めて有効な手法である。この技術は、計算リソースが限られた環境でモデルをデプロイするための事実上の標準となっているが、一方でモデルの性能劣化を招くという課題を抱えている。特に、量子化後の重みを調整するために使用される「キャリブレーションセット」の選択は、量子化の品質を左右する重要な要素である。しかし、現在のポストトレーニング量子化(PTQ)の実践では、多言語対応モデルであっても、C4やPileといった英語のみのデータセットをキャリブレーションに使用することが圧倒的に多い。この現状は、英語以外の言語におけるモデルの性能を制限しているのではないかという懸念を生じさせている。 特に、低リソース言語や非ラテン文字を使用する言語において、量子化による性能劣化が不釣り合いに大きいことが先行研究で示唆されている。…
核心:何を提案したのか
本研究は、多言語LLMの量子化におけるキャリブレーションデータの言語構成の影響を解明するため、包括的な評価フレームワークを提案した。具体的には、Llama3.1 8BおよびQwen2.5 7Bという、それぞれ8言語および29言語でトレーニングされた主要な多言語モデルを対象に、8種類のキャリブレーション設定を比較検証した。これらの設定には、英語のみのベースラインに加え、フランス語、スワヒリ語、中国語、イシコサ語といった単一の非英語データ、および複数の言語を混合した3種類の多言語ミックスが含まれている。量子化手法としては、業界で広く採用されているGPTQとAWQの2種類を採用した。GPTQはヘッセ行列に基づき重みを動的に調整する手法であり、AWQはアクティベーションの大きさに注目して重要なチャネルをスケーリングする手法である。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related