Temp-R1:逆カリキュラム強化学習による複雑な時間的KGQAのための統合自律エージェント
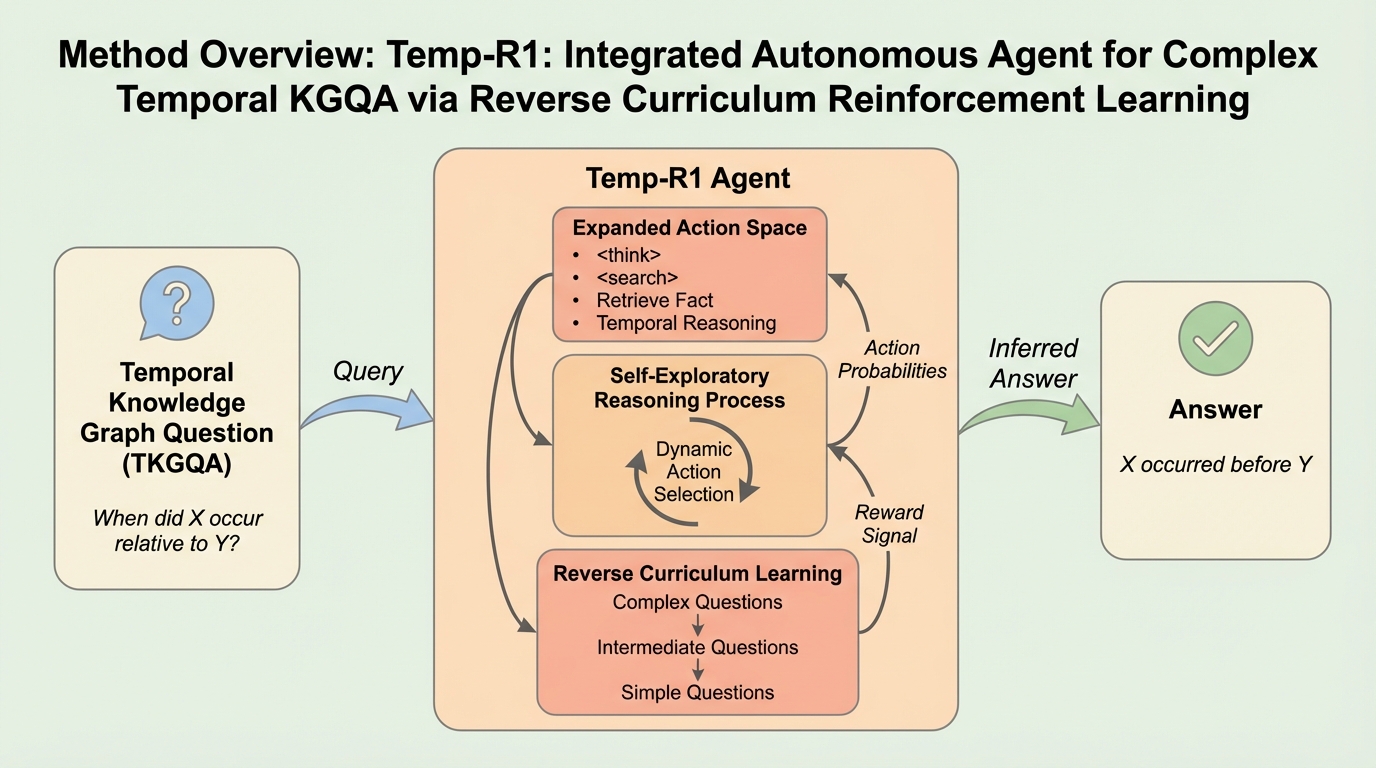
Temp-R1は、動的な事実と複雑な時間的制約を伴う知識グラフ質問応答(TKGQA)を解決するために開発された、強化学習ベースの統合自律エージェントである。 単一の思考タグによる認知負荷を分散させるため、内部アクションとして計画、フィルタリング、順位付けを導入し、さらに難易度の高い問題から学習を開始する逆カリキュラム学習を採用した。 80億パラメータのモデルでありながら、複雑な質問において既存手法を19.8%上回る精度を達成し、GPT-4oベースのシステムを凌駕する新たな状態最新(SOTA)を確立した。
TL;DR(結論)
Temp-R1は、動的な事実と複雑な時間的制約を伴う知識グラフ質問応答(TKGQA)を解決するために開発された、強化学習ベースの統合自律エージェントである。 単一の思考タグによる認知負荷を分散させるため、内部アクションとして計画、フィルタリング、順位付けを導入し、さらに難易度の高い問題から学習を開始する逆カリキュラム学習を採用した。 80億パラメータのモデルでありながら、複雑な質問において既存手法を19.8%上回る精度を達成し、GPT-4oベースのシステムを凌駕する新たな状態最新(SOTA)を確立した。
なぜこの問題か
現実世界における知識は静的なものではなく、時間の経過とともに常に進化し続けている。知識グラフにおいて情報が古くなるのを防ぐために、主語、述語、目的語にタイムスタンプを加えた四つ組(クアドラプル)の形式で事実を保持する時間的知識グラフ(TKG)が登場した。これに伴い、時間的知識グラフ質問応答(TKGQA)というタスクが重要視されているが、これはエンティティの特定だけでなく、動的な事実に基づいた時間的な推論が必要となるため、従来の知識グラフ質問応答よりもはるかに難易度が高い。複雑な時間的クエリを解くには、マルチホップ推論、複数の制約条件の処理、そして多様な時間の粒度を理解する能力が不可欠である。 既存のTKGQA手法の多くは、あらかじめ設計された固定のワークフローに依存している。これらは、質問の分解、計画、回答生成といった複数のコンポーネントを組み合わせたプロンプトエンジニアリングに基づいている。しかし、こうした手法はGPT-4oのようなクローズドソースのモデルAPIに大きく依存しており、推論にかかるAPIコストが非常に高額になるという実用上の課題がある。…
核心:何を提案したのか
本研究では、複雑な時間的推論能力を小規模な言語モデルに統合した自律型エージェント「Temp-R1」を提案した。Temp-R1は、強化学習を通じてトレーニングされた、TKGQAのための初のエンドツーエンド自律エージェントである。このモデルの最大の特徴は、推論プロセスを複数の明示的なアクションに分解し、モデルが自律的に多様な解決戦略を探索できるように設計されている点にある。 まず、認知負荷を軽減するためにアクション空間を拡張した。従来の単一の思考タグに頼るのではなく、内部アクションとして「計画(plan)」、「フィルタリング(filter)」、「順位付け(rank)」を定義し、外部アクションである「検索(search)」と組み合わせた。これにより、モデルは情報の検索、意味的な関連性の抽出、そして時系列の整理を個別のステップとして実行できるようになり、論理的な厳密さが向上した。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related