Transformer事前学習における最終層の隠れ状態の跳躍の抑制
Transformer言語モデルの内部挙動において、最終層付近で隠れ状態の角度距離が急激に変化する「跳躍(ジャンプ)」現象が多くのモデルで共通して観察されており、これが中間層の能力を十分に活用できていない原因であるという課題を特定しました。
TL;DR(結論)
Transformer言語モデルの内部挙動において、最終層付近で隠れ状態の角度距離が急激に変化する「跳躍(ジャンプ)」現象が多くのモデルで共通して観察されており、これが中間層の能力を十分に活用できていない原因であるという課題を特定しました。 この跳躍を定量化する指標を導入した上で、事前学習時に最終層の変位をペナルティとして課す正則化手法「JREG(Jump-Suppressing Regularizer)」を提案し、モデルの計算負荷を中間層へより均等に分散させることで、モデル全体の容量を効率的に引き出すことに成功しました。 Llamaベースの異なる規模のモデルを用いた実験により、モデルアーキテクチャを一切変更することなく、下流タスクにおける予測精度が向上し、内部状態の遷移がより滑らかになることで、パラメータの冗長性が解消されることが実証されました。これにより、将来的な大規模言語モデルの学習効率を大幅に改善する可能性が示唆されています。
なぜこの問題か
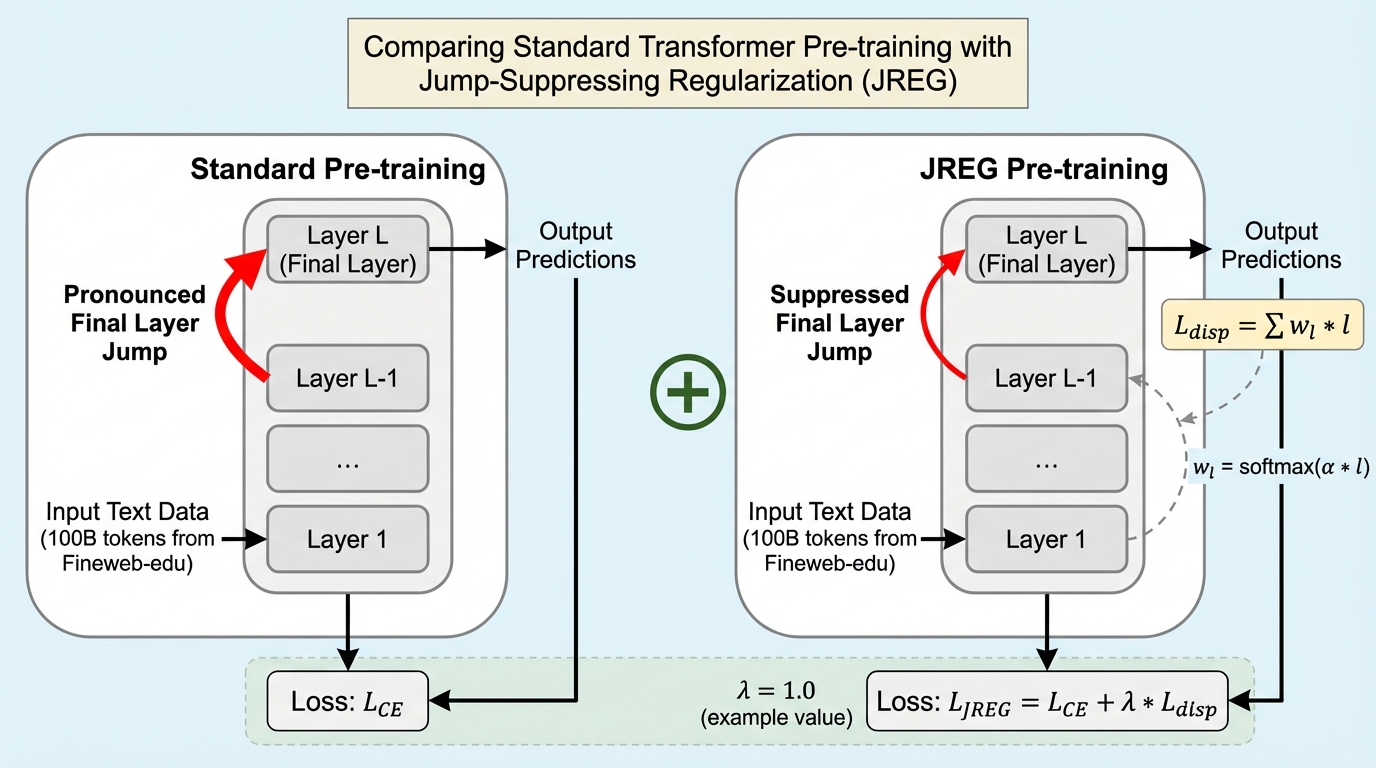
Transformerベースの言語モデルは、多くの人工知能タスクで優れた性能を示していますが、その内部メカニズム、特に各層がどのように情報を処理しているかについては、まだ解明すべき点が多く残されています。近年の研究では、事前学習済みのモデルにおいて、中間層の多くが入力と出力の隠れ状態ベクトルの間で角度距離の変化をほとんど生じさせていない、つまり「冗長で効果の薄い層」として機能していることが報告されています。一方で、モデルの最終層付近では、角度距離が不釣り合いなほど大きく変化する「跳躍(ジャンプ)」現象が発生していることが観察されています。これは、中間層が本来担うべき表現学習の負荷を適切に処理できておらず、そのしわ寄せが最終層に集中していることを示唆しています。 このような層ごとの貢献度の不均衡は、モデル全体のポテンシャルを制限し、パラメータの無駄を増やしている可能性があります。先行研究では、中間層の角度距離が小さい層を削除しても性能が大きく低下しないことが示されていますが、これは中間層が十分に活用されていないことの裏返しでもあります。…
核心:何を提案したのか
本研究の核心は、最終層における隠れ状態の急激な変化を抑制するための新しい正則化手法「JREG(Jump-Suppressing Regularizer)」の提案にあります。この手法は、標準的な交差エントロピー損失に加えて、各層の隠れ状態の変位(ディスプレイスメント)に基づくペナルティ項を導入するものです。具体的には、最終層に近い層ほど重く、中間層も含めた全層の変位を監視し、特に最終層で発生する突出した変化を抑え込むように設計されています。これにより、モデルは最終層だけに頼って出力を調整するのではなく、中間層の各ステップで段階的に表現を洗練させていくよう促されます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related