LLMによって洗練されたタクソノミーを用いた階層的テキスト分類
階層的テキスト分類(HTC)において、人間が作成した従来のタクソノミー(分類体系)には曖昧さや不整合が含まれており、言語モデルの学習を妨げているという課題がある。 本研究が提案する「TAXMORPH」は、大規模言語モデル(LLM)をタクソノミストとして活用し、リネームや統合、再配置を通じて分類体系全体をモデルの内部表現に適した構造へと自動的に洗練させるフレームワークである。 実験の結果、LLMで洗練されたタクソノミーは人間による元の体系を最大で2.9ポイント上回るF1スコアを記録し、モデルの推論バイアスとより密接に一致することで分類精度を向上させることが確認された。
TL;DR(結論)
階層的テキスト分類(HTC)において、人間が作成した従来のタクソノミー(分類体系)には曖昧さや不整合が含まれており、言語モデルの学習を妨げているという課題がある。 本研究が提案する「TAXMORPH」は、大規模言語モデル(LLM)をタクソノミストとして活用し、リネームや統合、再配置を通じて分類体系全体をモデルの内部表現に適した構造へと自動的に洗練させるフレームワークである。 実験の結果、LLMで洗練されたタクソノミーは人間による元の体系を最大で2.9ポイント上回るF1スコアを記録し、モデルの推論バイアスとより密接に一致することで分類精度を向上させることが確認された。
なぜこの問題か
人間にとって、情報を入れ子状のカテゴリーに整理する階層構造やタクソノミーは、複雑な概念の効率的な保存、検索、および推論を可能にする認知の核心的な要素である。自然言語処理の分野においても、階層的テキスト分類(HTC)はドキュメントを構造化されたラベルに割り当てる重要なタスクであり、タクソノミーや知識ベースの質がその性能を左右する。しかし、既存の多くのタクソノミーは人間によって手動で構築されており、そこには冗長性や曖昧さが含まれていることが多い。例えば、「Design」というラベルが「Web」と「Fashion」の両方の親ノードの下に重複して現れたり、クラス間の境界が不明確であったりすることがある。 このような人間中心の構造は、必ずしも言語モデル(LM)が事前学習を通じて獲得した内部的な表現や概念の整理方法と一致しているわけではない。言語モデルは事前学習中に豊かな階層的知識を習得していることが近年の研究で示されているが、人間が定義したタクソノミーに不整合がある場合、モデルは明確な決定境界を形成できず、分類エラーを引き起こす原因となる。…
核心:何を提案したのか
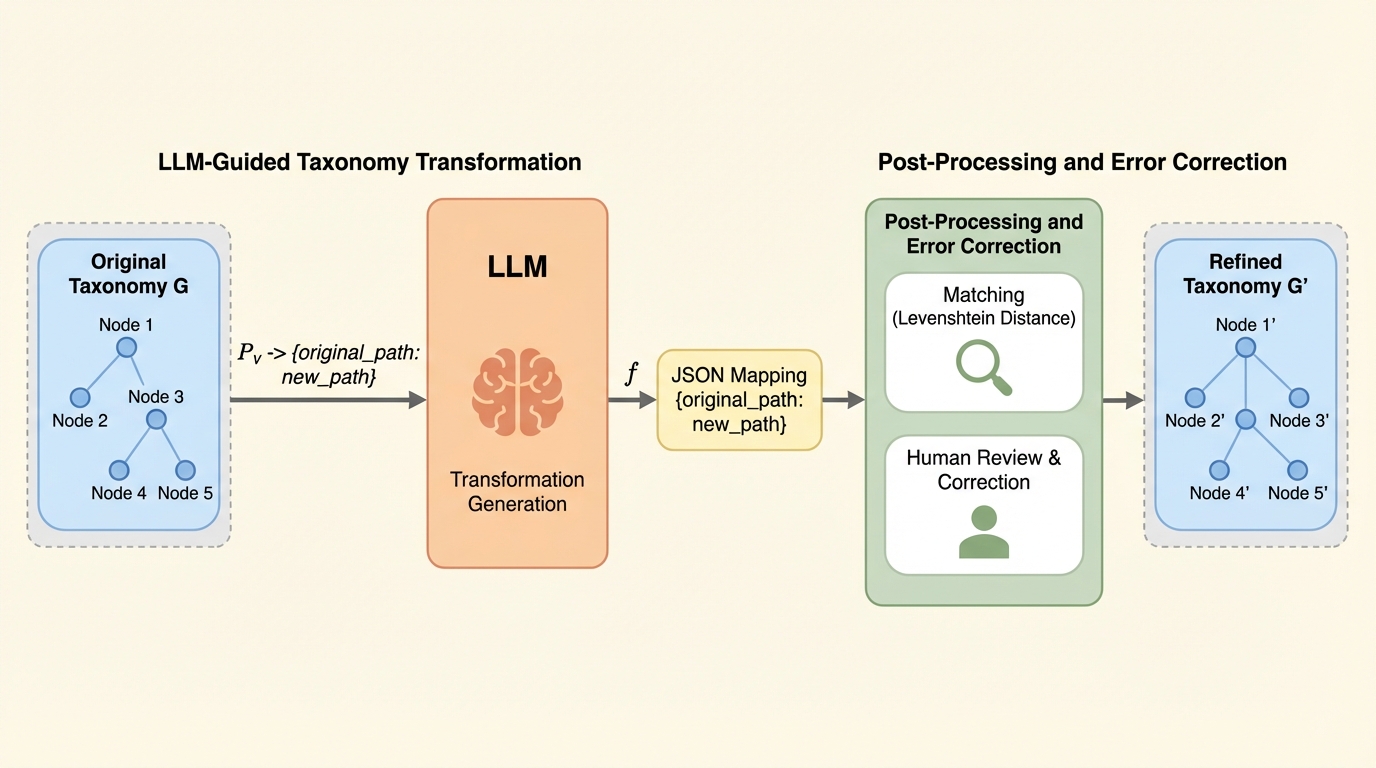
本論文は、LLMを使用して既存のタクソノミーを変換し、洗練させるための二段階のフレームワークである「TAXMORPH」を提案している。この手法の最大の特徴は、LLMを単なる分類器としてではなく、分類体系全体を再設計する「タクソノミスト(分類学者)」として扱う点にある。TAXMORPHは、個別のノードを一つずつ処理するのではなく、タクソノミー全体のコンテキストを考慮しながら、リネーム(名前変更)、マージ(統合)、スプリット(分割)、リオーダー(再配置)といった操作を組み合わせて階層構造を根本から見直す。 具体的には、第一段階として「生成フェーズ」があり、ここではLLMが入力されたタクソノミー全体を考慮して変換案を生成する。LLMは元のパスと新しいパスの対応関係をJSON形式で出力し、これによって体系全体での一貫性を保った修正が可能になる。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related