パラメーター微調整を超えて:ノード分類のためのテスト時表現洗練
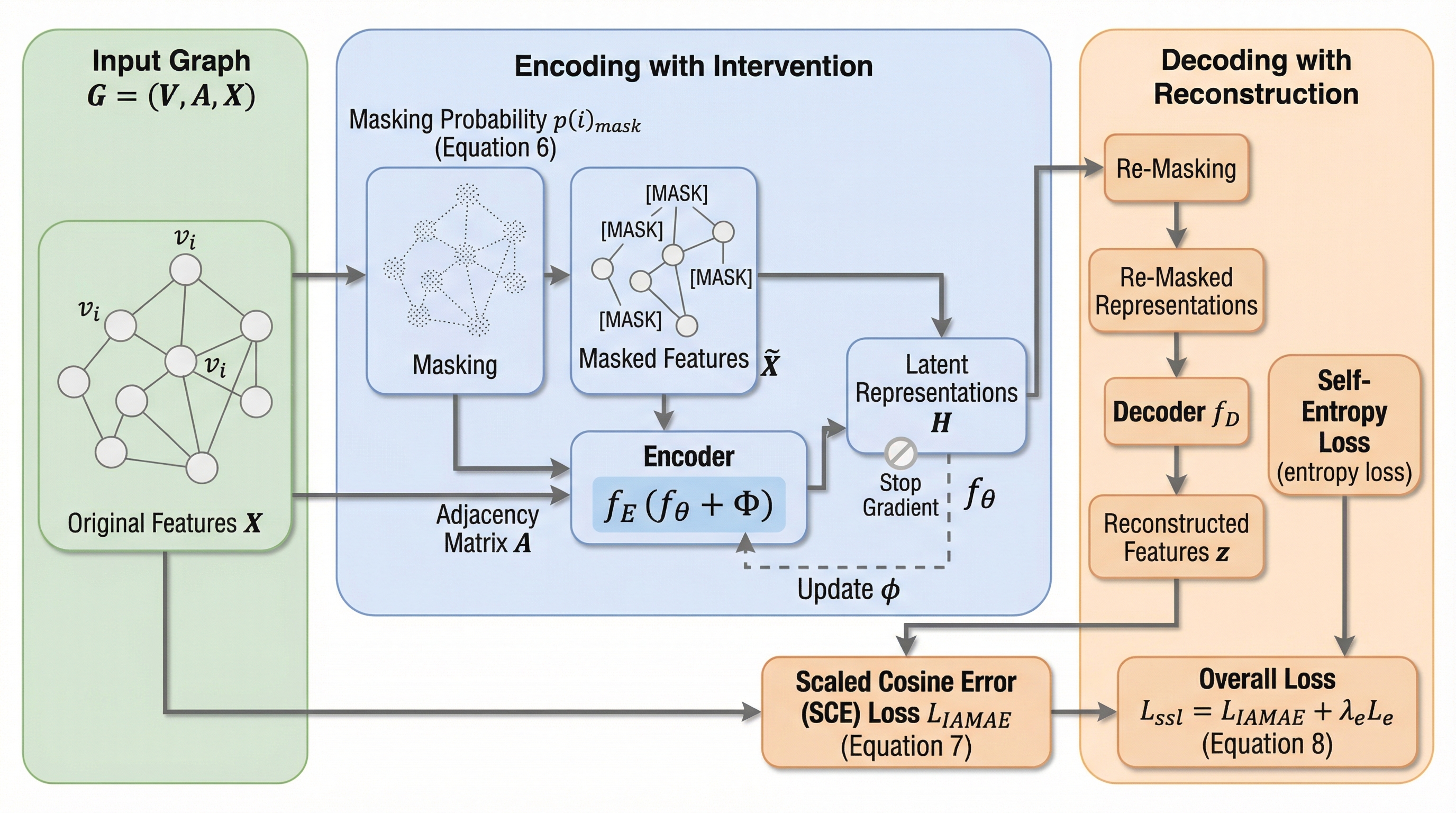
グラフニューラルネットワーク(GNN)が未知のデータ分布(OOD)に直面した際の性能低下を解決するため、従来のモデルパラメーターを更新する手法(PaFT)に代わり、潜在的な表現のみを修正する新しいパラメーター効率的な学習フレームワーク「TTReFT」が提案されました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
グラフニューラルネットワーク(GNN)が未知のデータ分布(OOD)に直面した際の性能低下を解決するため、従来のモデルパラメーターを更新する手法(PaFT)に代わり、潜在的な表現のみを修正する新しいパラメーター効率的な学習フレームワーク「TTReFT」が提案されました。
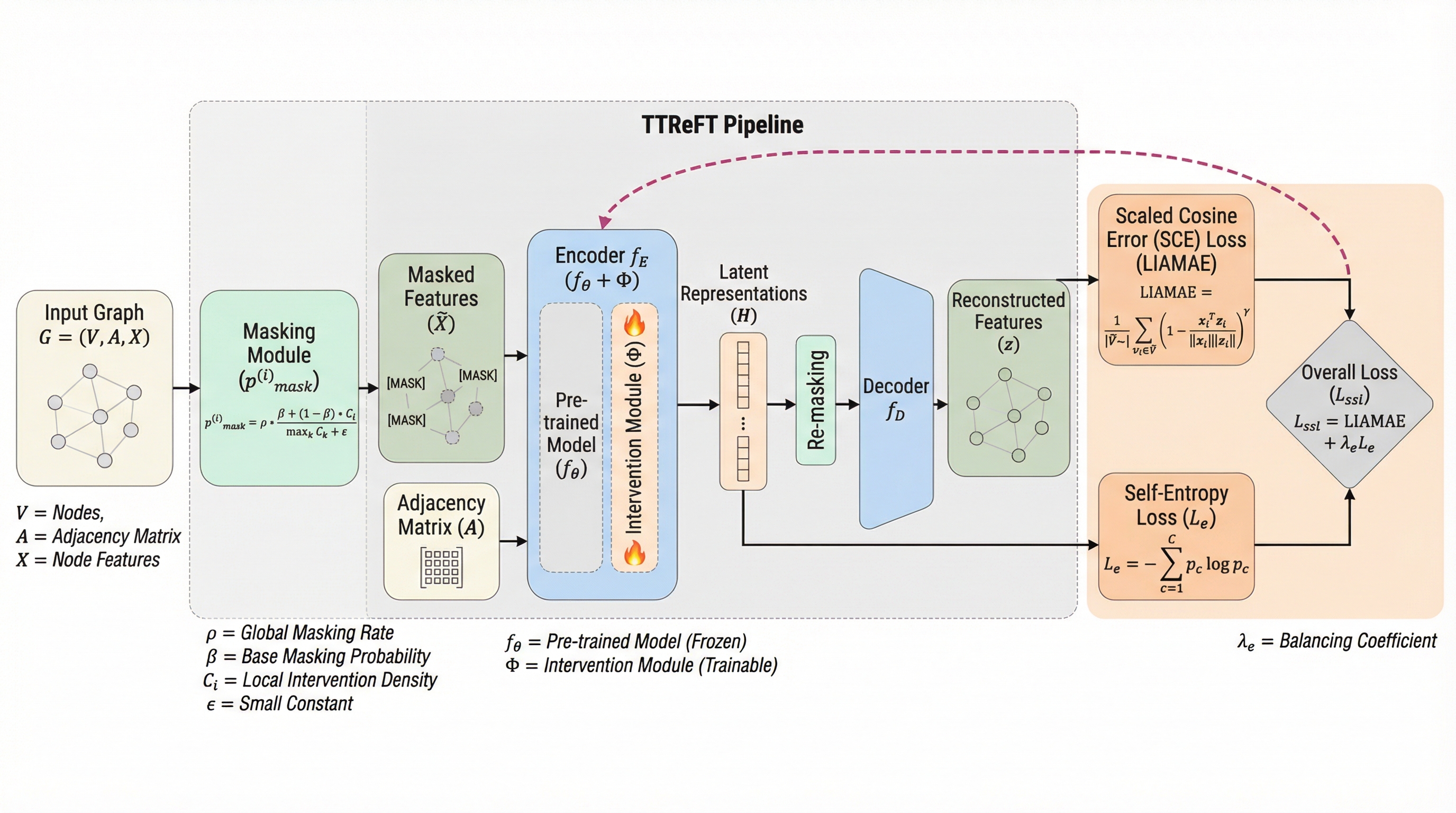
グラフニューラルネットワーク(GNN)が未知のデータ分布に直面した際の性能低下を解決するため、モデルのパラメータを更新せずに潜在的な表現層のみを調整する新しい学習枠組み「TTReFT」が提案されました。
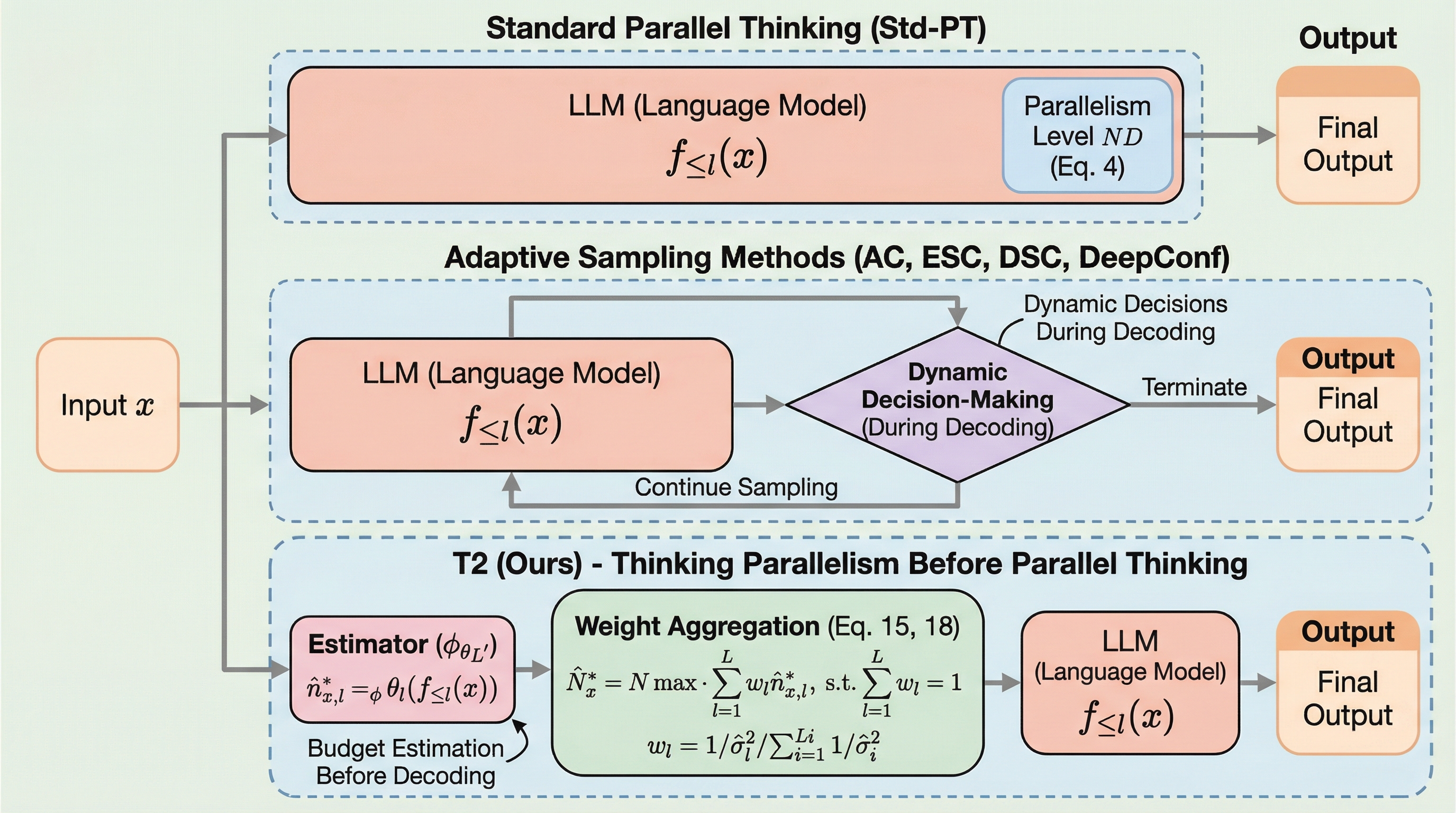
大規模言語モデル(LLM)の推論において、複数の推論パスを並列生成して多数決で統合する「並列思考」は有効ですが、全データに一律の大規模な並列数(予算)を割り当てると、多くのサンプルで計算資源が無駄になる「オーバースケーリングの呪い」が発生します。
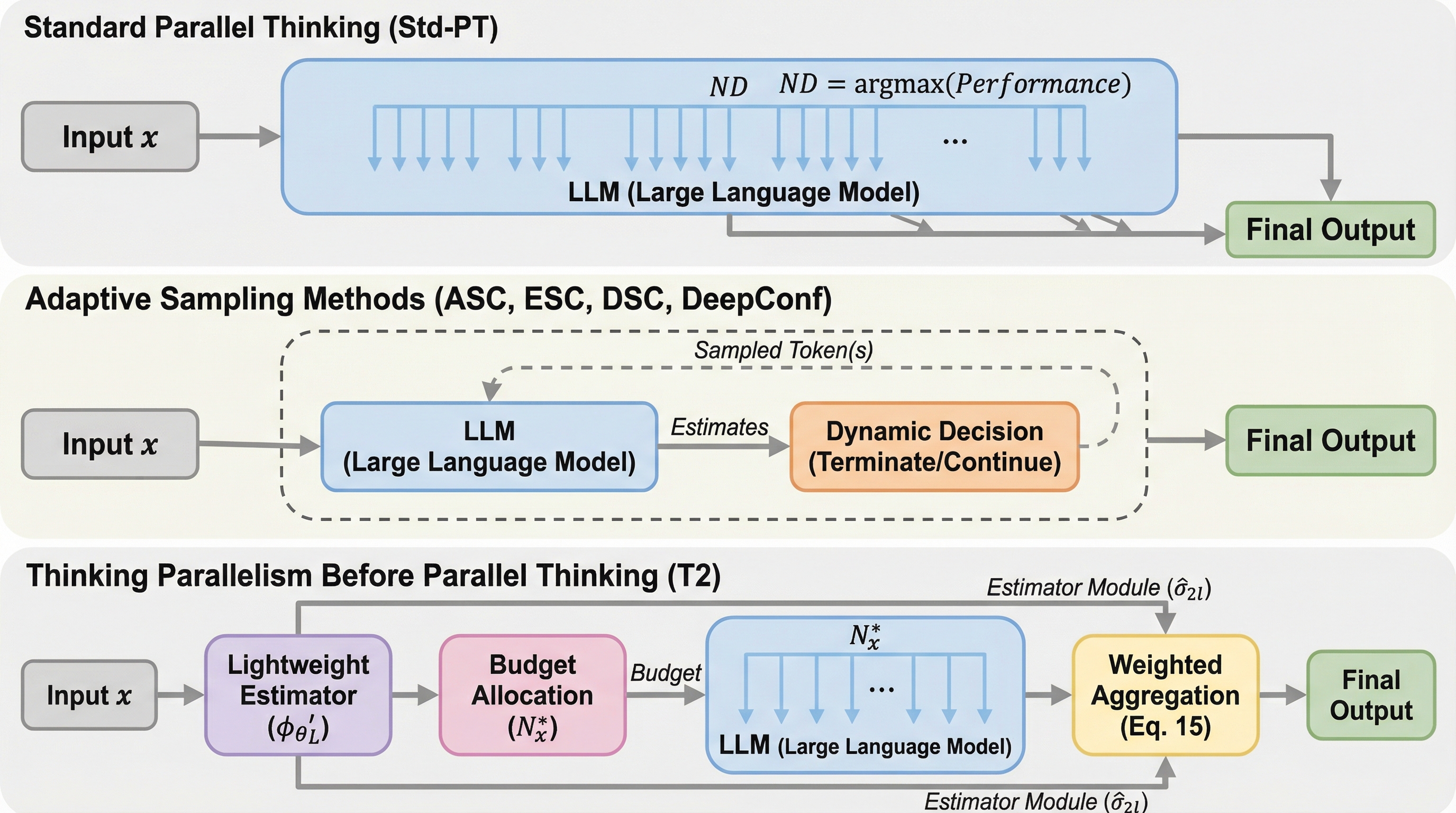
大規模言語モデルの推論において、複数の回答を生成して統合する「並列的思考」は精度を向上させますが、全問題に一律の大きな並列度を割り当てると、簡単な問題などで計算資源が無駄になる「オーバースケーリングの呪い」が発生することを明らかにしました。
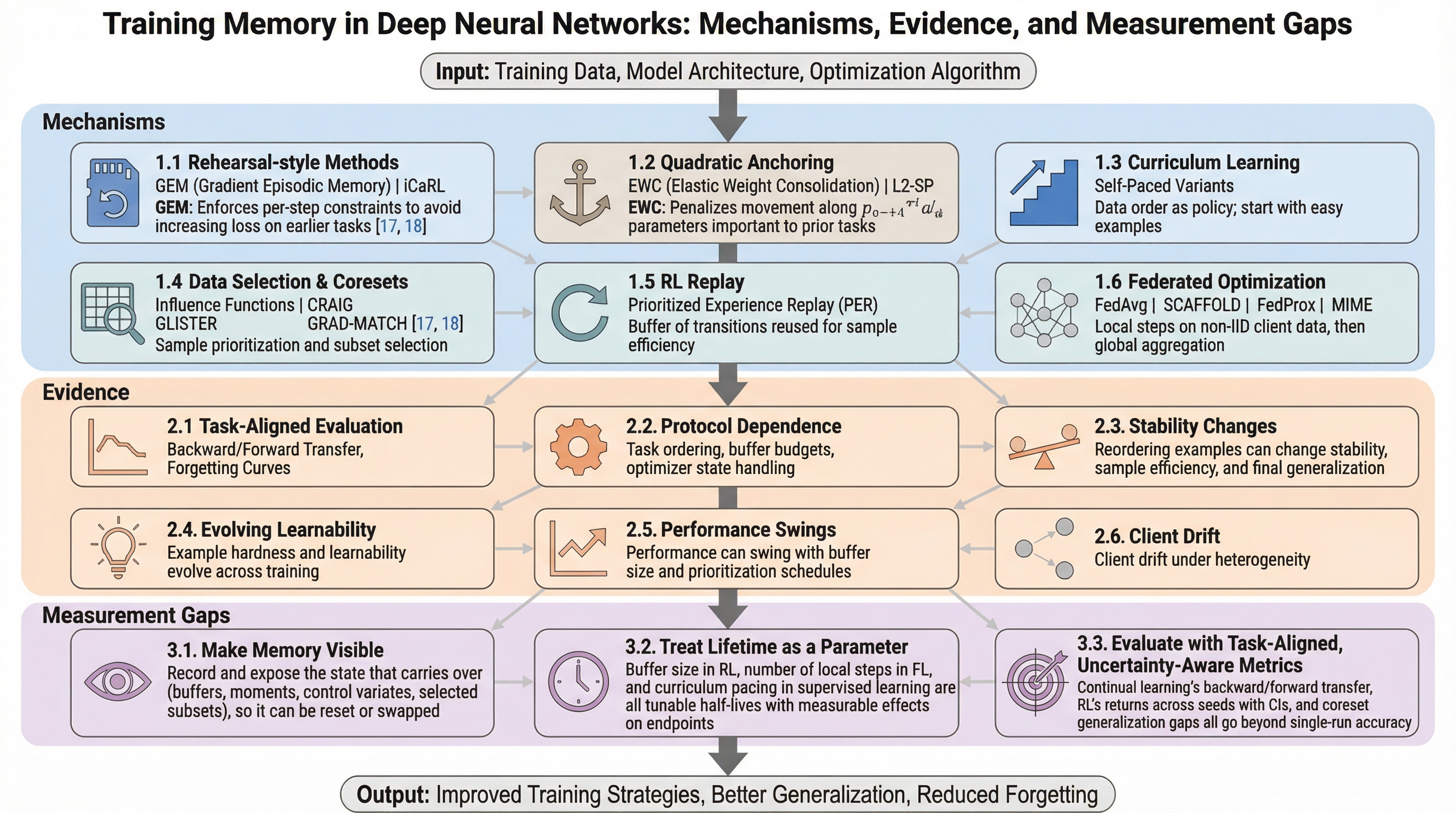
現代の深層学習のトレーニングプロセスは、過去の状態を保持しない「メモリレス」なものではなく、オプティマイザのモーメント、データの提示順序、非凸な損失関数上の経路、およびバッチ正規化の統計量といった多様な補助的状態に依存して更新が行われる「学習メモリ」を持つプロセスである。
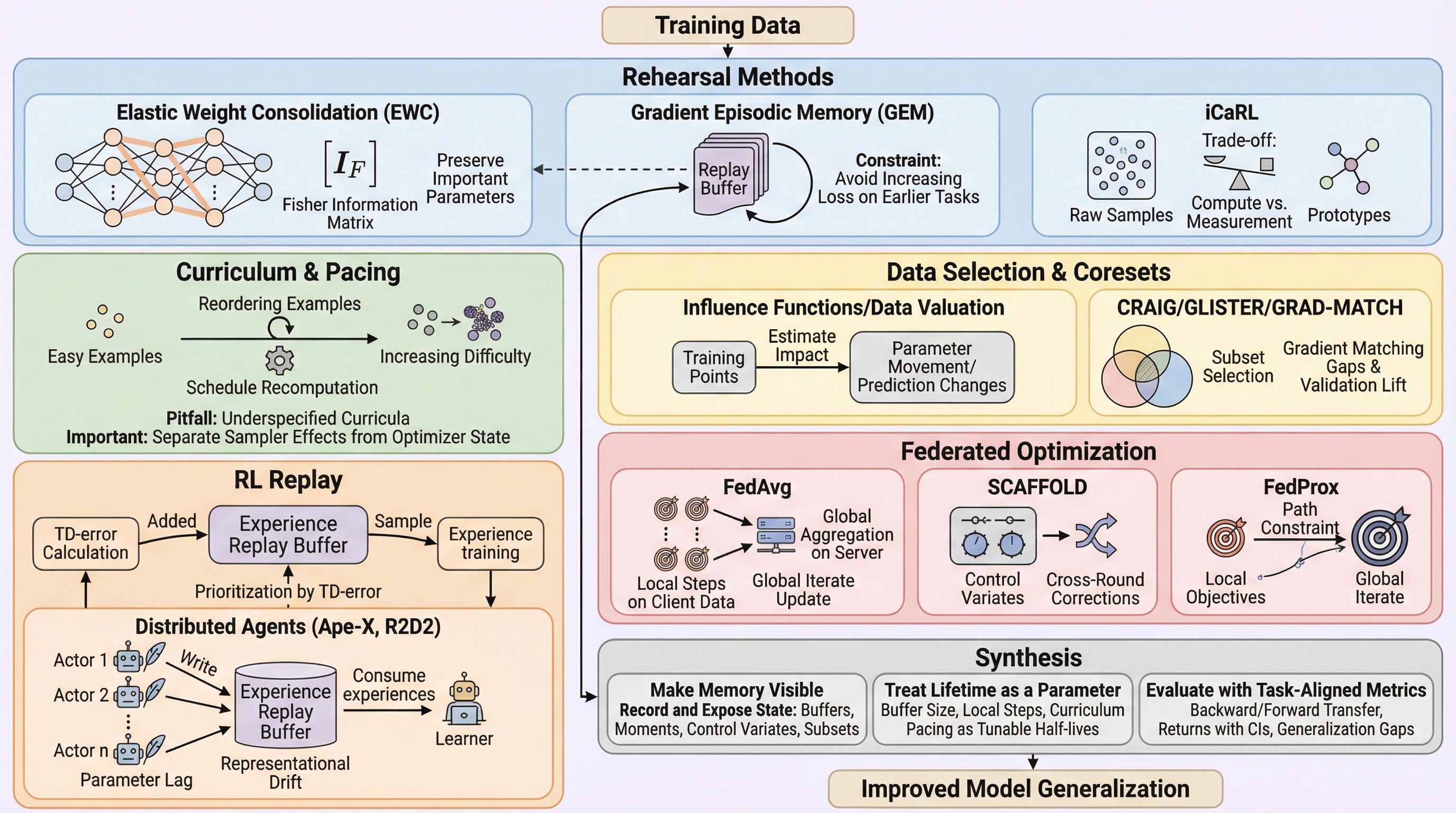
深層学習のトレーニングプロセスは、現在のパラメータとミニバッチのみに依存するメモリレスな過程ではなく、過去の勾配履歴、データの提示順序、非凸な損失関数上の経路、外部バッファ、および教師モデルの統計量といった多層的な「トレーニングメモリ」に強く依存して進行する。
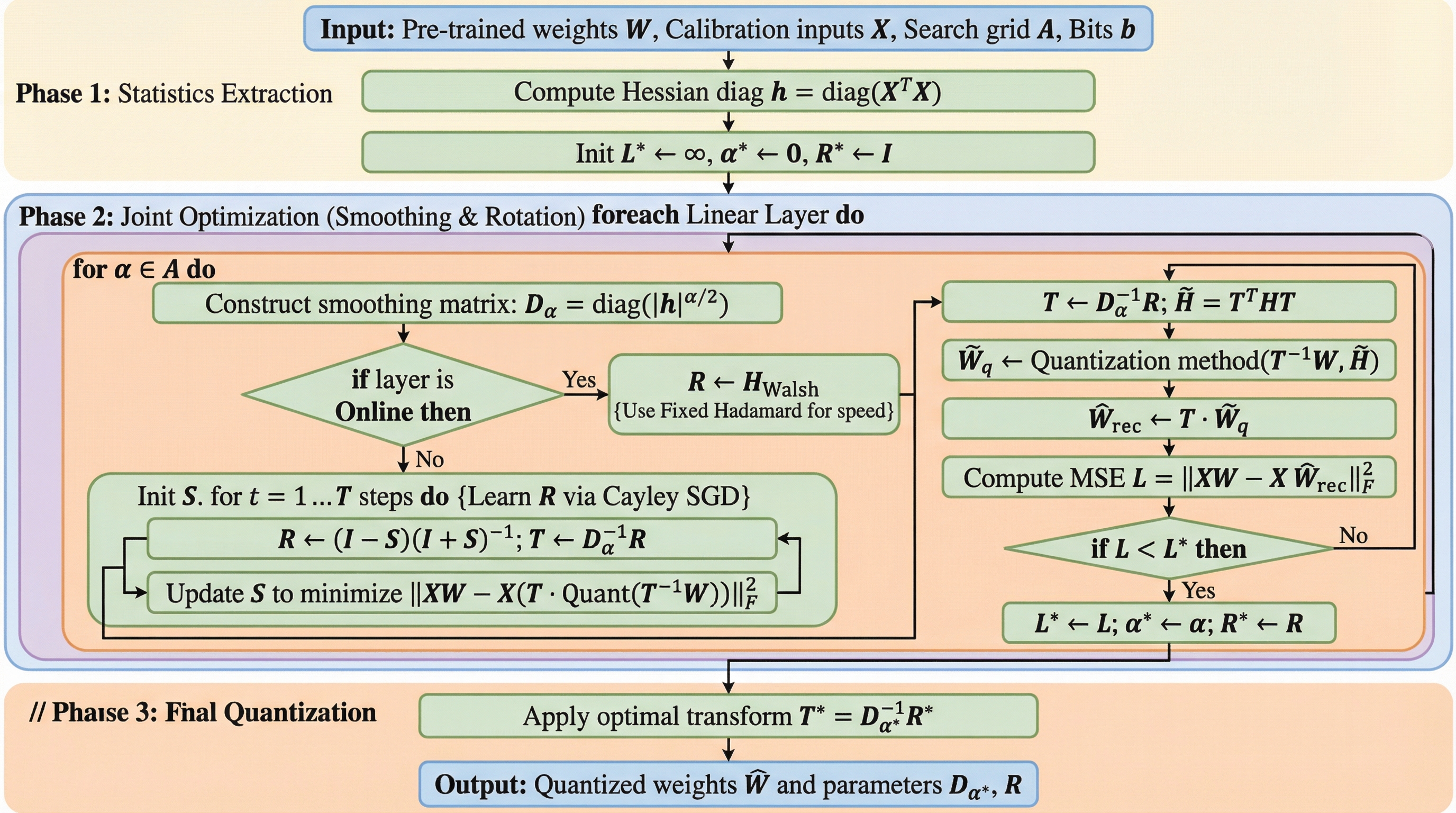
大規模言語モデル(LLM)の量子化において、重みの誤差が小さいにもかかわらず性能が急落する「低誤差・高損失」の矛盾を解決するため、損失曲面の幾何学的構造を改善する新フレームワーク「HeRo-Q」が提案されました。
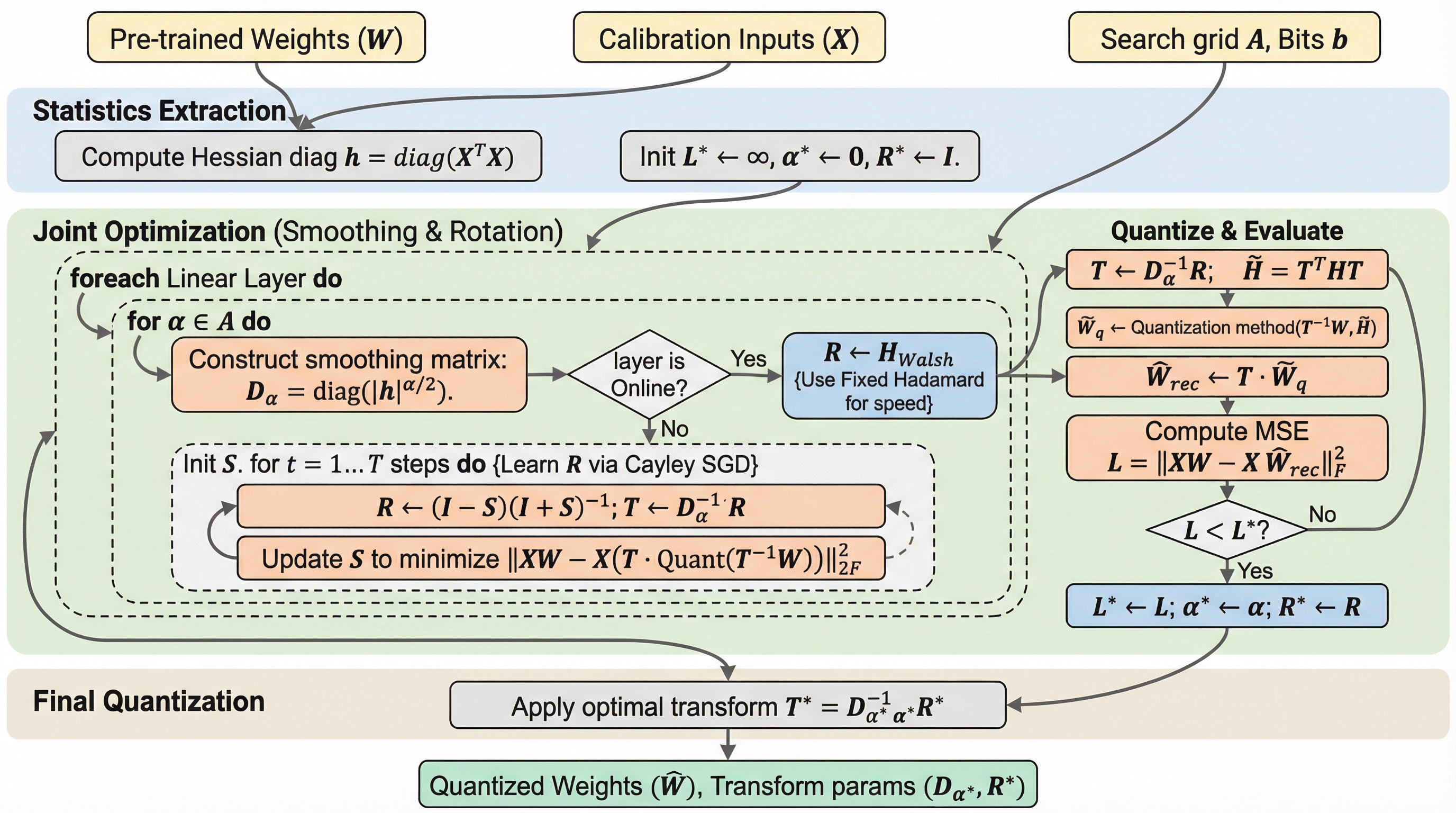
大規模言語モデルの量子化において、誤差は小さいのに性能が大幅に低下する「低誤差・高損失」の矛盾を解決するため、損失曲面の幾何学的構造であるヘッセ行列の曲率を調整する新しいフレームワーク「HeRo-Q」が提案されました。
従来の時系列予測向け混合エキスパート(MoE)モデルは、各時間ステップを独立して処理するトークン単位のルーティングを採用していたが、データの連続性や局所的な構造を十分に活用できていないという課題があった。
時系列予測におけるTransformerモデルのスケーリングと長期的な動態把握の課題に対し、従来のトークン単位ではなく、連続するタイムステップを一つのセグメントとしてルーティングする新しい疎な混合専門家(MoE)アーキテクチャ「Seg-MoE」を提案している。