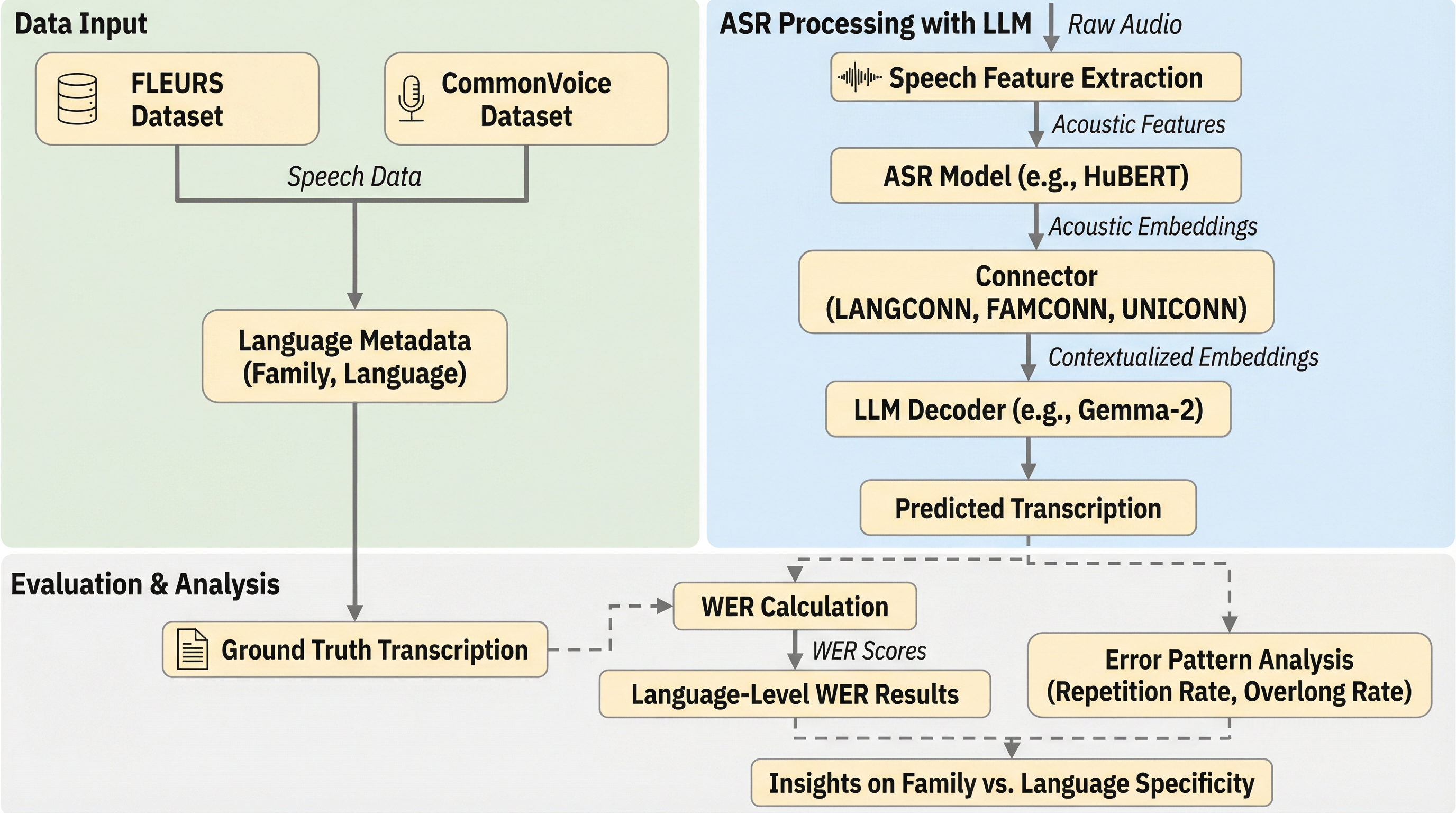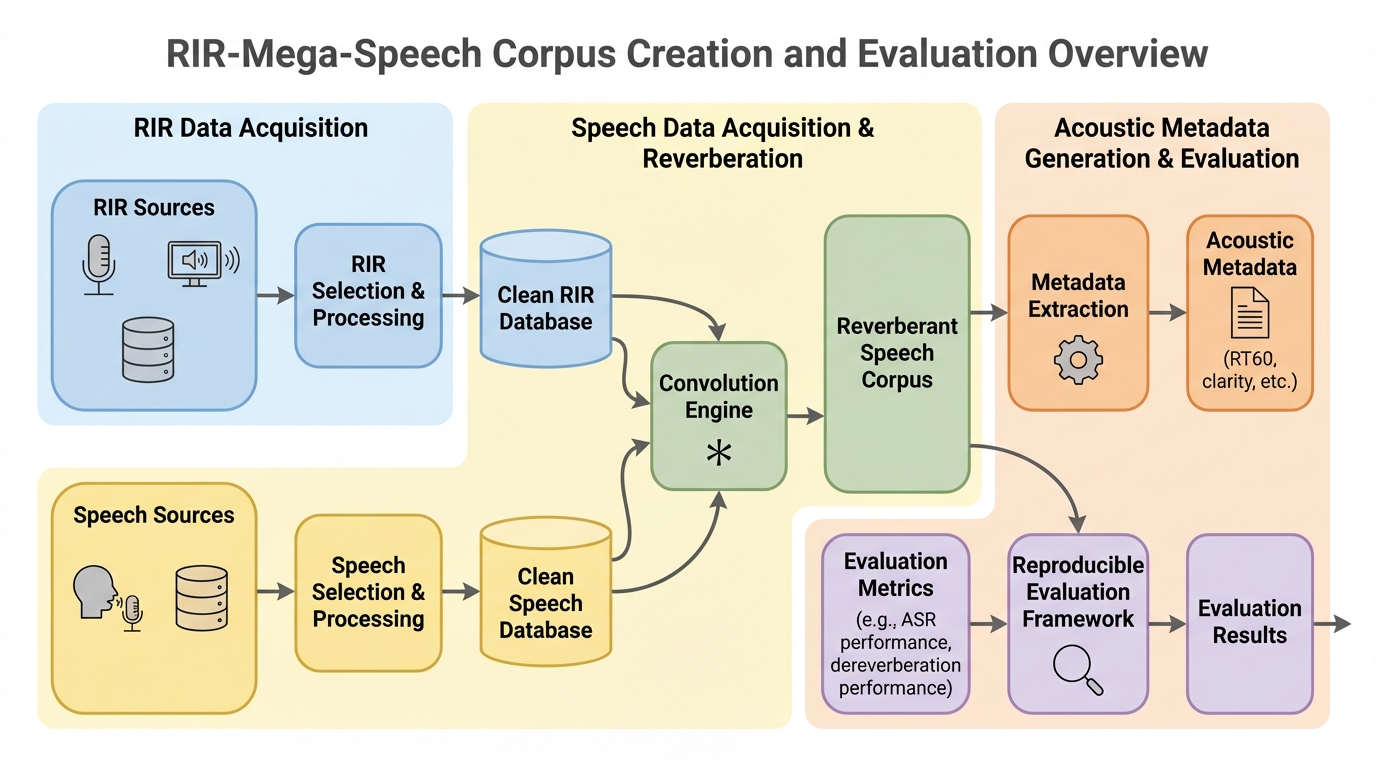
RIR-Mega-Speech:網羅的な音響メタデータと再現可能な評価を備えた残響音声コーパス
RIR-Mega-Speechは、LibriSpeechの音声と約5,000のシミュレーションされた部屋インパルス応答(RIR)を組み合わせた、約117.5時間の新しい残響音声コーパスである。最大の特徴は、全ファイルに対してRT60、直接音対残響音比(DRR)、明瞭度指数(C50)といった詳細な音響メタデータが付与されている点にあり、WindowsおよびLinux環境でデータセットの再構築や評価結果の再現が可能なスクリプトが提供されている。Whisper smallモデルを用いた検証では、残響によって単語誤り率(WER)が5.20%から7.70%へと相対的に48%悪化することが示され、RT60の増加やDRRの低下に伴って認識精度が単調に低下する物理的特性と一致する傾向が確認された。