不均衡補正を伴う音源定位のための解析的増分学習
本研究は、音源定位(SSL)の増分学習において、特定の方向のデータが極端に多い「タスク内不均衡」と、タスク間でクラス分布が重なり歪む「タスク間不均衡」の二重の課題を解決する新フレームワーク「SSL-GCIL」を提案しました。
TL;DR(結論)
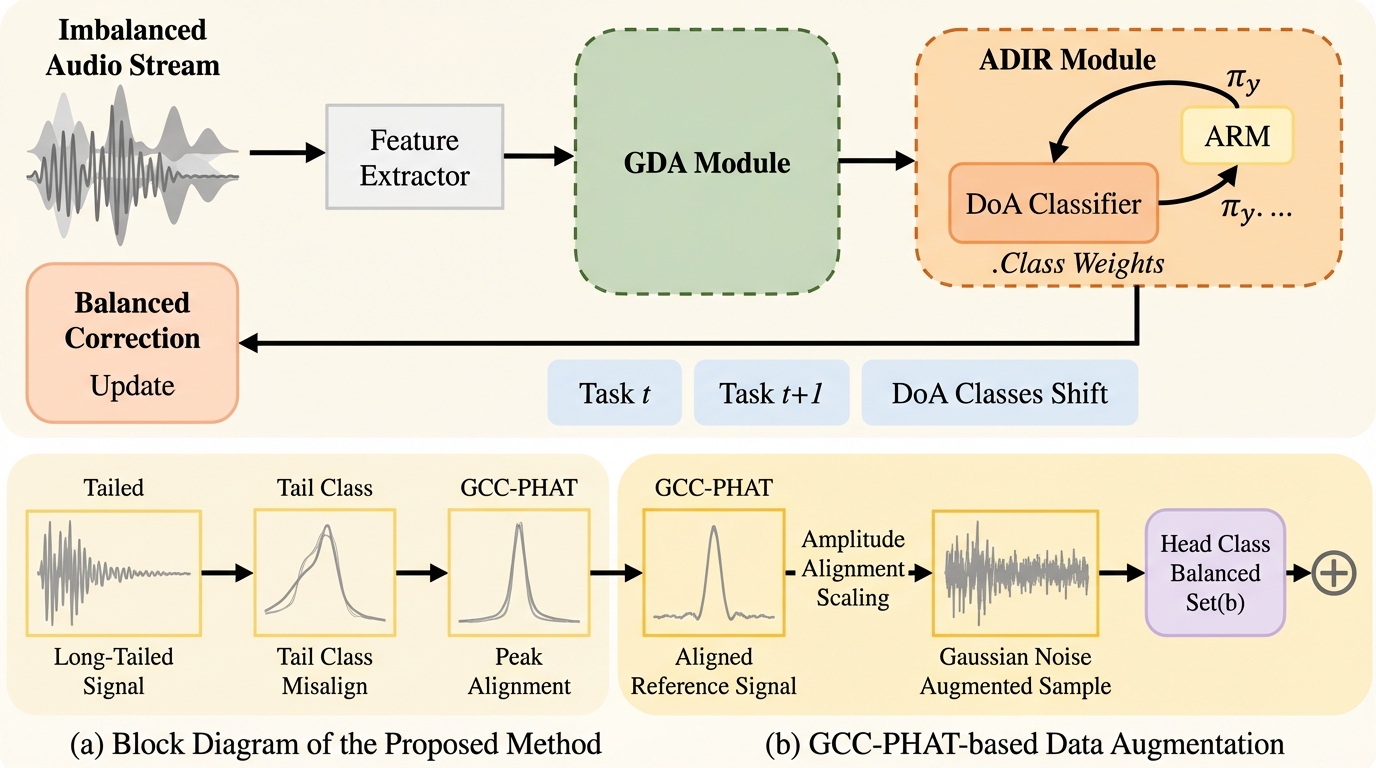
本研究は、音源定位(SSL)の増分学習において、特定の方向のデータが極端に多い「タスク内不均衡」と、タスク間でクラス分布が重なり歪む「タスク間不均衡」の二重の課題を解決する新フレームワーク「SSL-GCIL」を提案しました。 具体的には、GCC-PHATのピーク統計量を利用して少数派クラスのデータを擬似生成する拡張手法(GDA)と、ジニ係数に基づき正則化を動的に調整して過去の知識を保護する解析的分類器(ADIR)を導入し、生データを保存せずに学習を継続します。 検証の結果、SSLRベンチマークで精度89.0%、平均絶対誤差5.3度という最高水準の性能を達成し、既存手法が陥る破滅的忘却を克服して、新しい学習が過去の知識を強化する「正のバックワード・トランスファー」を世界で初めて実現しました。
なぜこの問題か
音源定位(SSL)は、複数のマイクから得られるオーディオ信号を利用して音源の到来方向(DoA)を推定する技術であり、ロボットの聴覚システムや自動音声認識、音声強調、話者抽出といった人間とロボットの相互作用において極めて重要な役割を担っています。従来の信号処理手法であるGCC-PHATやMUSIC、SRP-PHATなどは、理想的な音響条件を前提とした閉形式の解に依存しているため、騒音や強い残響が存在する現実の複雑な環境下では、その性能が著しく低下するという根本的な課題を抱えていました。近年、深層学習を用いた手法が大きな進歩を遂げていますが、音源定位のためのラベル付きデータは依然として不足しており、実際の運用シーンでは、ロボットが新しい音源方向に逐次適応していく「増分学習」の能力が不可欠となります。 しかし、新しいタスクを学習する際に過去の知識を完全に失ってしまう「破滅的忘却」が大きな障壁となっており、特に現実世界では特定の方向のデータが過剰に存在する一方で、他の方向が極端に少ない「ロングテール分布」がこの問題をさらに悪化させています。…
核心:何を提案したのか
本研究の核心は、タスク内とタスク間の両方の不均衡に対処しつつ、破滅的忘却を克服する統一フレームワーク「SSL-GCIL」を提案したことにあります。まず、タスク内の不均衡に対しては、GCC-PHATベースのデータ拡張(GDA)という、音響ドメインの特性を活かした独自の手法を導入しました。これは、音源定位において最も重要な時間遅延情報を保持するGCC-PHATのピーク特性を操作することで、データが不足している「テールクラス(少数派クラス)」のサンプルを、既存の豊富なクラスのデータから擬似的に生成する技術です。外部データに頼ることなく、既存の統計情報を利用して少数派クラスを補強するため、統計的な一貫性とプライバシーを維持したまま、学習の安定性を大幅に向上させることが可能になります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related