LTS-VoiceAgent:意味的トリガーと増分推論による効率的なストリーミング音声対話のための「聞く・考える・話す」フレームワーク
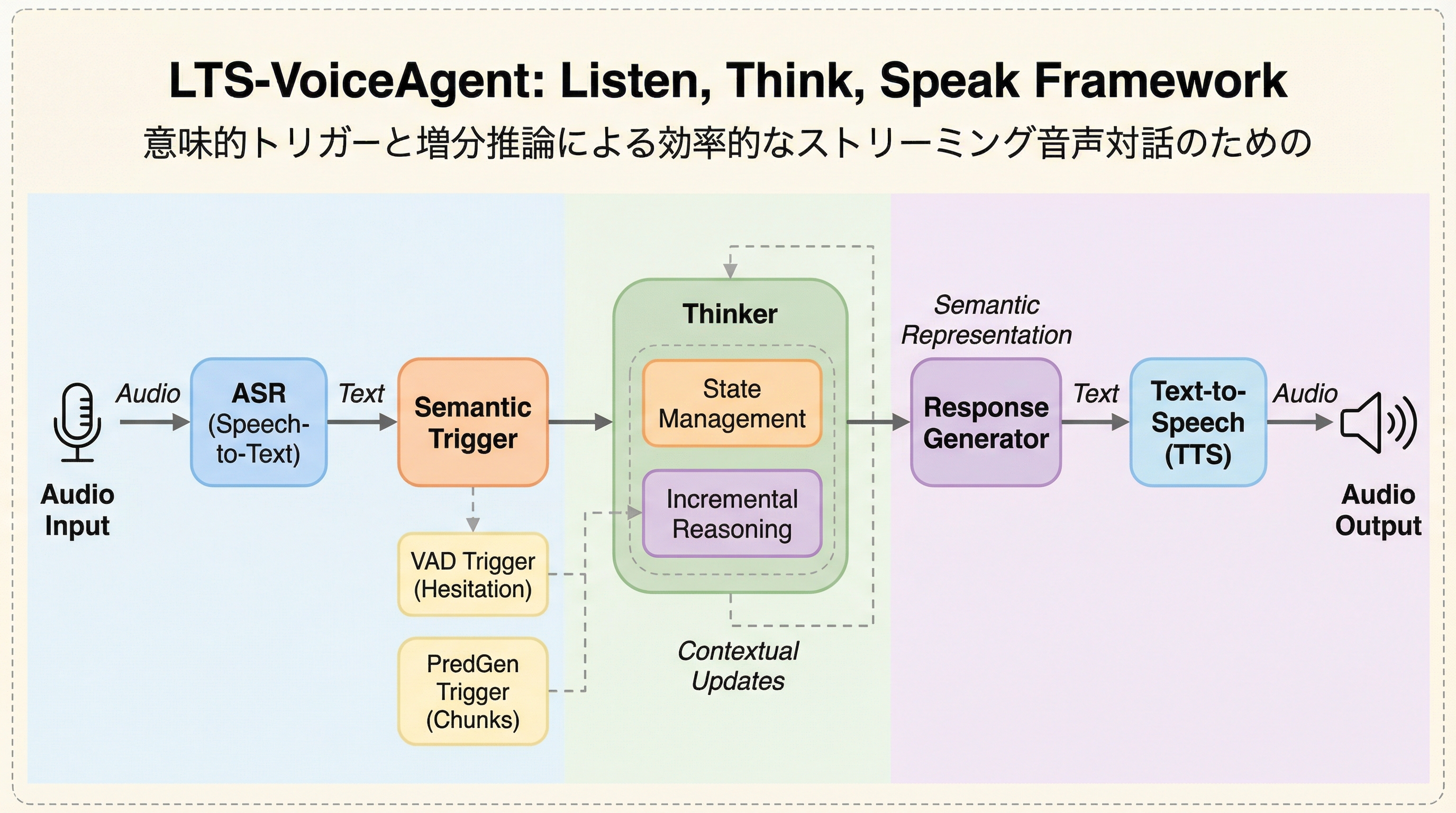
従来の音声エージェントが抱えていた「推論能力の不足」と「高い応答遅延」の二律背反を解消するため、意味の区切りを検知して思考を開始する「動的意味トリガー」と、思考と発話を並列化する「二重役割ストリームオーケストレーター」を導入したLTS-VoiceAgentフレームワークを提案しました。
TL;DR(結論)
従来の音声エージェントが抱えていた「推論能力の不足」と「高い応答遅延」の二律背反を解消するため、意味の区切りを検知して思考を開始する「動的意味トリガー」と、思考と発話を並列化する「二重役割ストリームオーケストレーター」を導入したLTS-VoiceAgentフレームワークを提案しました。 このシステムは、ユーザーが話している最中に背景で「思考者(Thinker)」が状態を維持・更新し、前面で「話者(Speaker)」が推測的に回答を生成することで、人間のような「聞きながら考える」動作をカスケード型構成において実現し、ミリ秒単位の低遅延と高度な論理推論を両立させています。 自然な言い淀みや自己訂正を含む過酷な条件下での評価のために「Pause-and-Repair」ベンチマークを構築し、検証の結果、従来の逐次処理方式や既存のストリーミング戦略と比較して、精度・遅延・計算効率のすべての面で優れたトレードオフを達成していることが確認されました。
なぜこの問題か
現在のリアルタイム音声エージェントは、大きく分けて二つの困難な課題に直面しています。一つは、音声から直接応答を生成するエンドツーエンド(E2E)モデルが、応答速度には優れるものの、複雑な論理推論や指示に従う能力において、テキストベースの大規模言語モデル(LLM)に依然として及ばないという点です。もう一つは、音声認識(ASR)、LLMによる推論、音声合成(TTS)を順番に実行する従来のカスケード型パイプラインが、高い推論能力を持つ一方で、各工程を直列に処理するために膨大な待機時間が発生するという点です。人間同士の会話では、聞き手は話し手が話し終えるのを待たずに思考を開始しますが、従来のシステムはユーザーが沈黙するまで処理を開始できないため、自然なターン交代が阻害されていました。 この遅延を解消するために、音声を一定の間隔で区切る手法や、無音区間を検知するVAD(音声活動検知)に基づいたストリーミング戦略が試みられてきました。しかし、機械的な区切りは意味の単位を破壊しやすく、VADは「えーと」といった意味のない言い淀みでも推論を起動させてしまうため、計算資源の無駄遣いや論理的な矛盾を引き起こす原因となっていました。…
核心:何を提案したのか
本研究では、効率的なストリーミング対話を実現するための新しいフレームワークとして「LTS-VoiceAgent(Listen-Think-Speak)」を提案しました。このフレームワークの最大の特徴は、従来の「待機してから反応する」あるいは「闇雲に推測する」というアプローチとは異なり、意味的な充足度に基づいて思考のタイミングを制御し、思考と発話を明示的に分離して並列処理する点にあります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related