語族の重要性:言語の境界を越えたLLMベースのASRの評価
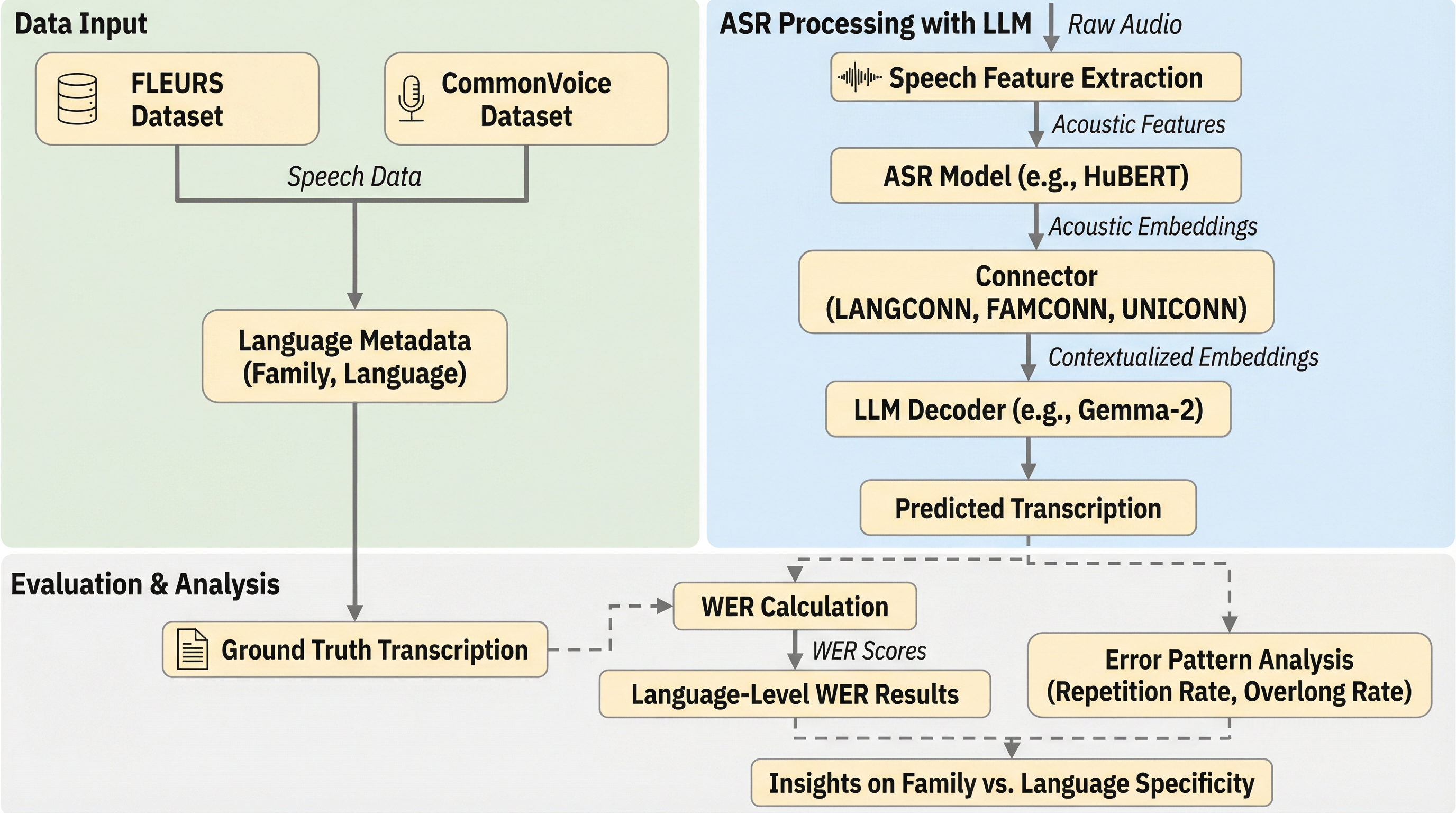
大規模言語モデル(LLM)を活用した自動音声認識(ASR)において、個別の言語ごとに接続モジュール(コネクタ)を学習させる従来の手法に対し、言語的な類似性に基づいた「語族」単位でコネクタを共有する新しい戦略を提案した。
TL;DR(結論)
大規模言語モデル(LLM)を活用した自動音声認識(ASR)において、個別の言語ごとに接続モジュール(コネクタ)を学習させる従来の手法に対し、言語的な類似性に基づいた「語族」単位でコネクタを共有する新しい戦略を提案した。 10の語族と約40の言語を含む2つの大規模な音声データセットを用いた検証の結果、語族単位のコネクタはパラメータ数を削減しつつ、ドメインを越えた汎用性を高め、多くの言語で単語誤り率(WER)を大幅に改善することが確認された。 語族内での音韻的・形態的な共通性を活用することで、特定の言語に特化しすぎることで生じる出力の繰り返しや異常な長文化といった不安定さを抑制し、多言語ASRの展開における実用的かつスケーラブルな手法としての有効性を示した。
なぜこの問題か
自動音声認識(ASR)の技術は、モデルのアーキテクチャや学習手法の進歩に伴って急速に発展してきた。初期の単一言語システムから、現在では複数の言語を統一された枠組みで扱うことができる多言語モデルへと進化を遂げている。特に、wav2vec 2.0、HuBERT、XLS-R、そしてWhisperといったユニバーサルな音声エンコーダの登場により、広範な言語をカバーする可能性が示されてきた。しかし、効率性と精度の両立を維持しながら、さらに多くの言語をサポートし続けることは依然として大きな課題である。この課題に対する一つの解決策として、音声エンコーダと大規模言語モデル(LLM)を組み合わせた「SpeechLLM」の構築が進められている。SpeechLLMは、音声エンコーダが持つ音響表現能力と、LLMが持つ高度な推論および生成能力を統合するものである。 一部のアプローチでは、音声エンコーダとLLMを大規模なエンドツーエンドモデルとして学習させるが、これらはパラメータが重く計算コストが非常に高いため、言語やドメインを越えた微調整には多大なコストがかかる。…
核心:何を提案したのか
本研究では、言語的な語族のメンバーシップに基づいた、効率的で斬新な「コネクタ共有戦略」を提案している。従来のSpeechLLMベースのASRシステムでは、言語ごとに個別のコネクタ(LANGCONN)を学習させることが一般的であったが、この手法では言語間の関連性が無視されてしまうという問題があった。これに対し、提案手法では同じ語族に属する言語間で一つのコネクタ(FAMCONN)を共有する。これにより、パラメータ数を抑えつつ、言語間の音韻的および形態的な類似性を効果的に活用することを目指している。この提案の有効性を検証するために、10の語族にわたる約40の言語を対象とした大規模な調査が実施された。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related