OCR強化型マルチモーダルASRは聞きながら読むことができる
本研究では、音声認識モデルのWhisperとOCRモデルのDonutを統合した、エンドツーエンドのマルチモーダル音声認識モデル「Donut-Whisper」を提案し、映画の字幕などの視覚的なテキスト情報を活用することで、音声のみのモデルが苦手とするノイズ環境や未知語の認識精度を大幅に向上させた。
TL;DR(結論)
本研究では、音声認識モデルのWhisperとOCRモデルのDonutを統合した、エンドツーエンドのマルチモーダル音声認識モデル「Donut-Whisper」を提案し、映画の字幕などの視覚的なテキスト情報を活用することで、音声のみのモデルが苦手とするノイズ環境や未知語の認識精度を大幅に向上させた。 独自の多言語データセットを用いた検証では、従来のWhisper large V3と比較して、英語で5.75%の単語誤り率(WER)削減、中国語で16.5%の文字誤り率(CER)削減という顕著な成果を達成しており、視覚的な文字情報が音声認識を補完する強力な手がかりになることを実証した。 さらに、このマルチモーダルモデルを教師として音声のみのモデルを学習させる軽量な知識蒸留スキームを提案し、字幕のない環境でも動作する単一モダリティモデルの性能を底上げすることに成功したほか、スライディングウィンドウ型Q-Formerを用いた新しい融合アーキテクチャの有効性を明らかにした。
なぜこの問題か
人間が音声を理解するプロセスは本質的にマルチモーダルであり、特に映画の字幕やプレゼンテーションのスライドに含まれる文字情報は、音声内容を正確に認識するための極めて重要な手がかりとなります。 しかし、近年のエンドツーエンド音声認識(ASR)システムの進歩は主に音声入力のみに焦点を当てており、背景ノイズが激しい環境や、学習データに含まれない専門用語(アウトオブドメイン語)が登場する場面では、認識精度が著しく低下するという課題を抱えていました。 これまでのマルチモーダル音声認識の研究では、話者の唇の動き(リップリーディング)を利用するものや、画像からテキストを抽出して外部のバイアスリストとして利用する手法が主流でしたが、これらはシステム全体を微分可能な形で統合したエンドツーエンドの学習が困難であるという制約がありました。 一方で、コンピュータビジョンの分野ではDonutのような強力な視覚エンコーダが登場しており、実世界の複雑なシナリオ下でも堅牢に文字を認識できるようになっています。…
核心:何を提案したのか
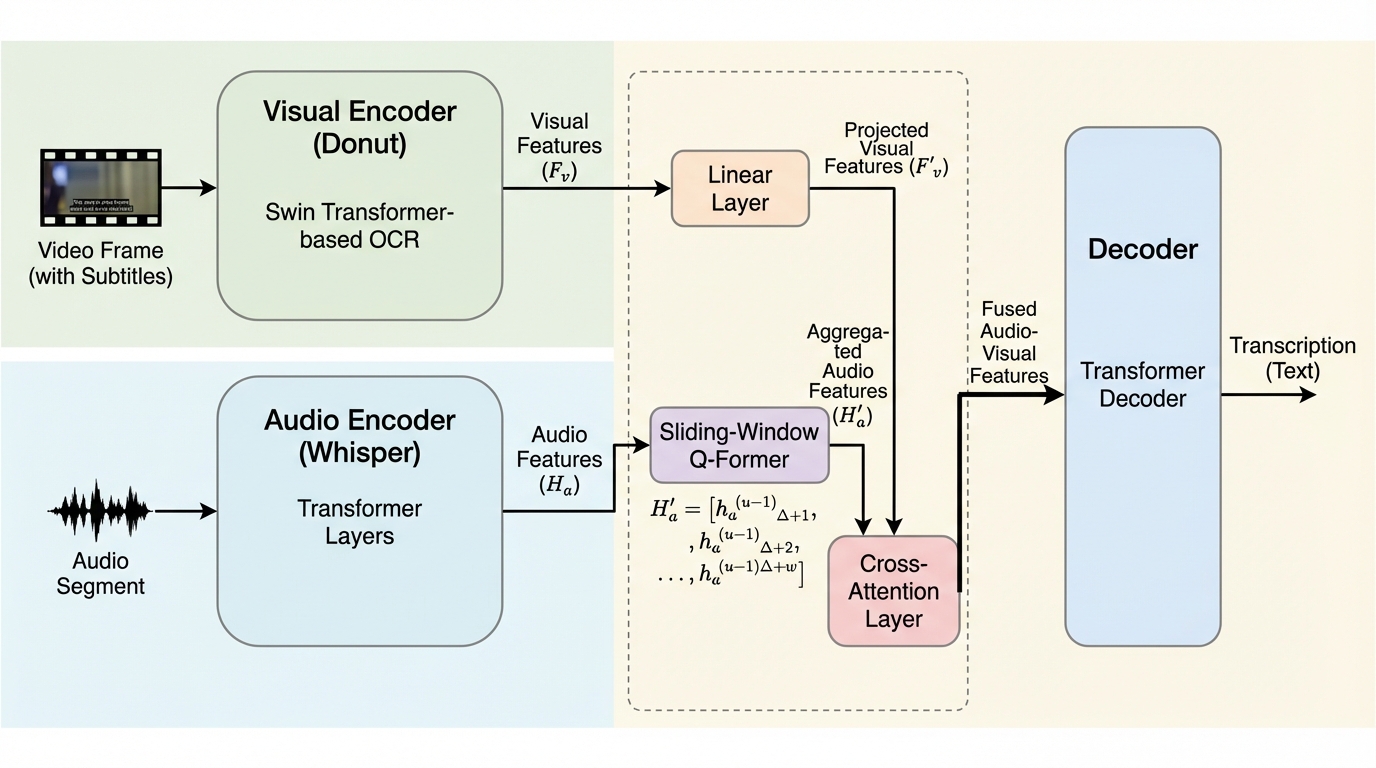
本論文の核心的な提案は、事前学習済みのOCRモデルであるDonutと、強力な音声認識モデルであるWhisperを統合した「Donut-Whisper」と呼ばれるデュアルエンコーダ型のアーキテクチャです。 このモデルは、映像から抽出されたキーフレームを処理する視覚エンコーダと、対応する音声セグメントを処理する音声エンコーダを並列に配置し、それらの出力を革新的な特徴融合モジュールによって統合します。 特徴融合モジュールには、線形投影層、スライディングウィンドウ型Q-Former、およびクロスアテンション構造が採用されており、音声と視覚の異なるモダリティ間のアライメントを効果的に行います。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related