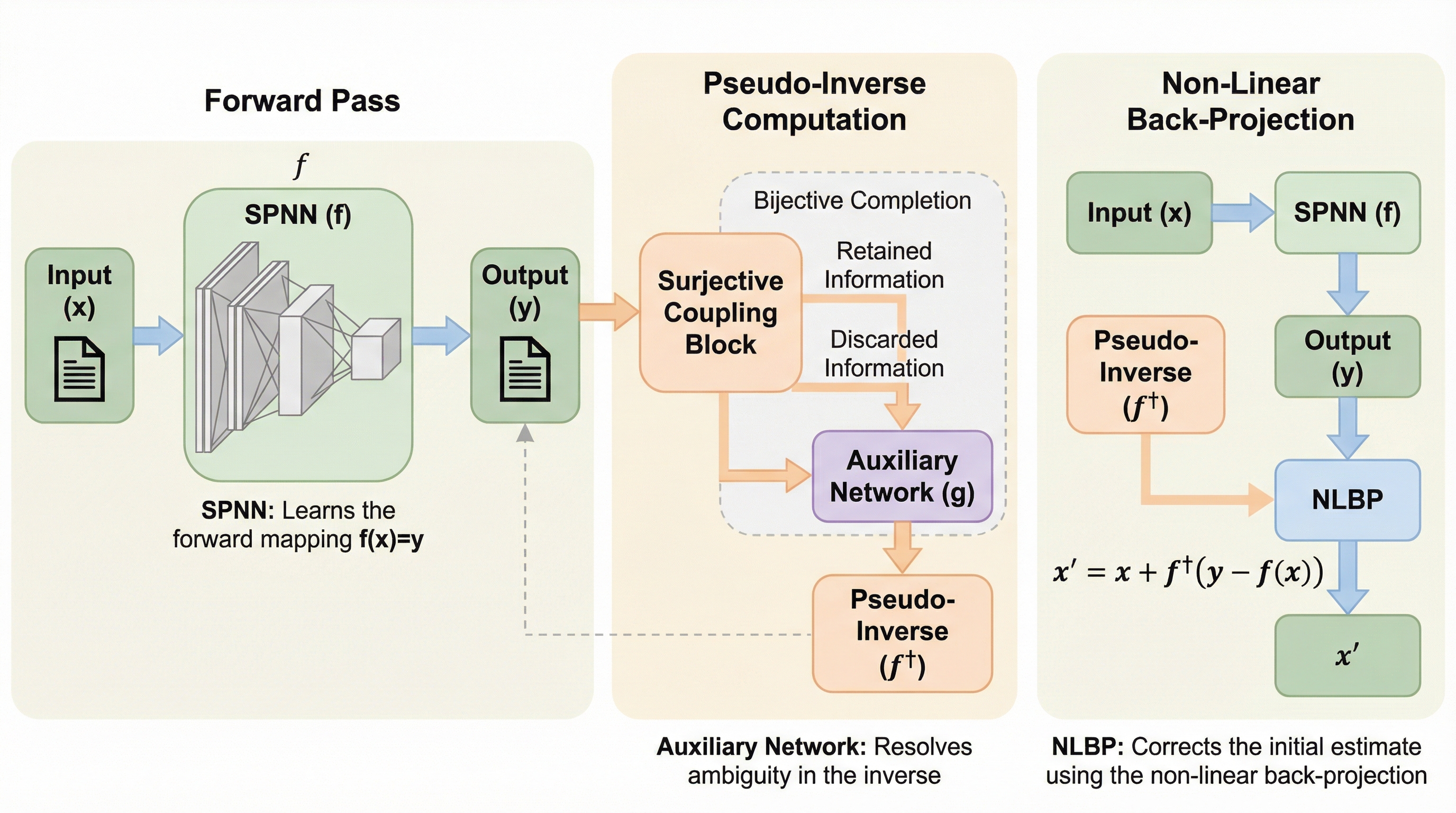
擬似可逆ニューラルネットワーク
線形システムにおけるMoore-Penroseの擬似逆行列(PInv)を非線形領域および深層学習へと拡張し、情報の損失を伴う全射的な写像においても厳密な代数的整合性を保持する新アーキテクチャ「SPNN」を提案した。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
線形システムにおけるMoore-Penroseの擬似逆行列(PInv)を非線形領域および深層学習へと拡張し、情報の損失を伴う全射的な写像においても厳密な代数的整合性を保持する新アーキテクチャ「SPNN」を提案した。
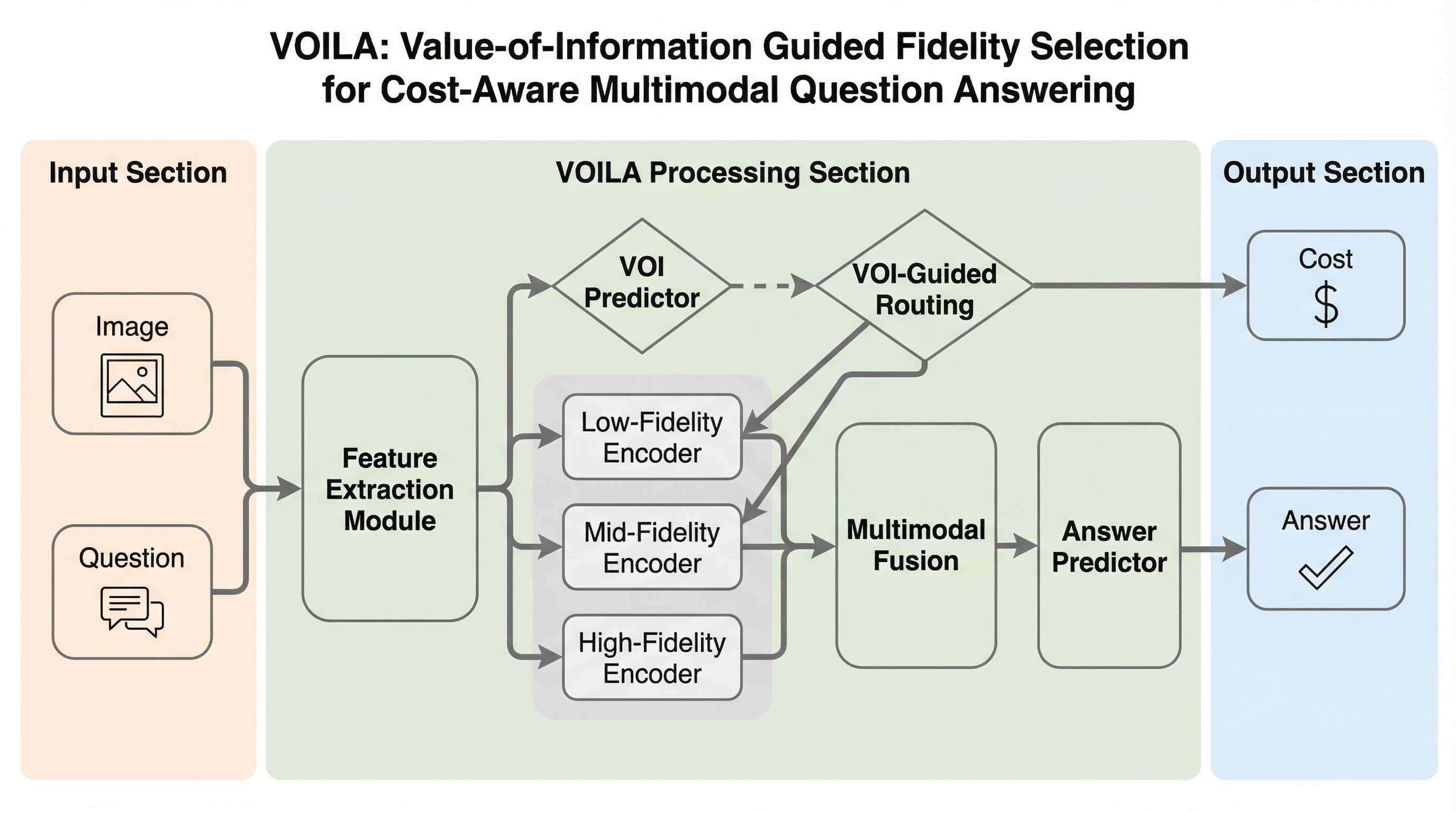
VOILAは、マルチモーダルな質問応答において、画像データを取得する前に最適な解像度(忠実度)を動的に選択する革新的なフレームワークである。質問文のテキスト特徴のみから各忠実度での正解確率を予測し、情報の取得コストと期待される精度のバランスを最大化する最小コストの忠実度を決定する。
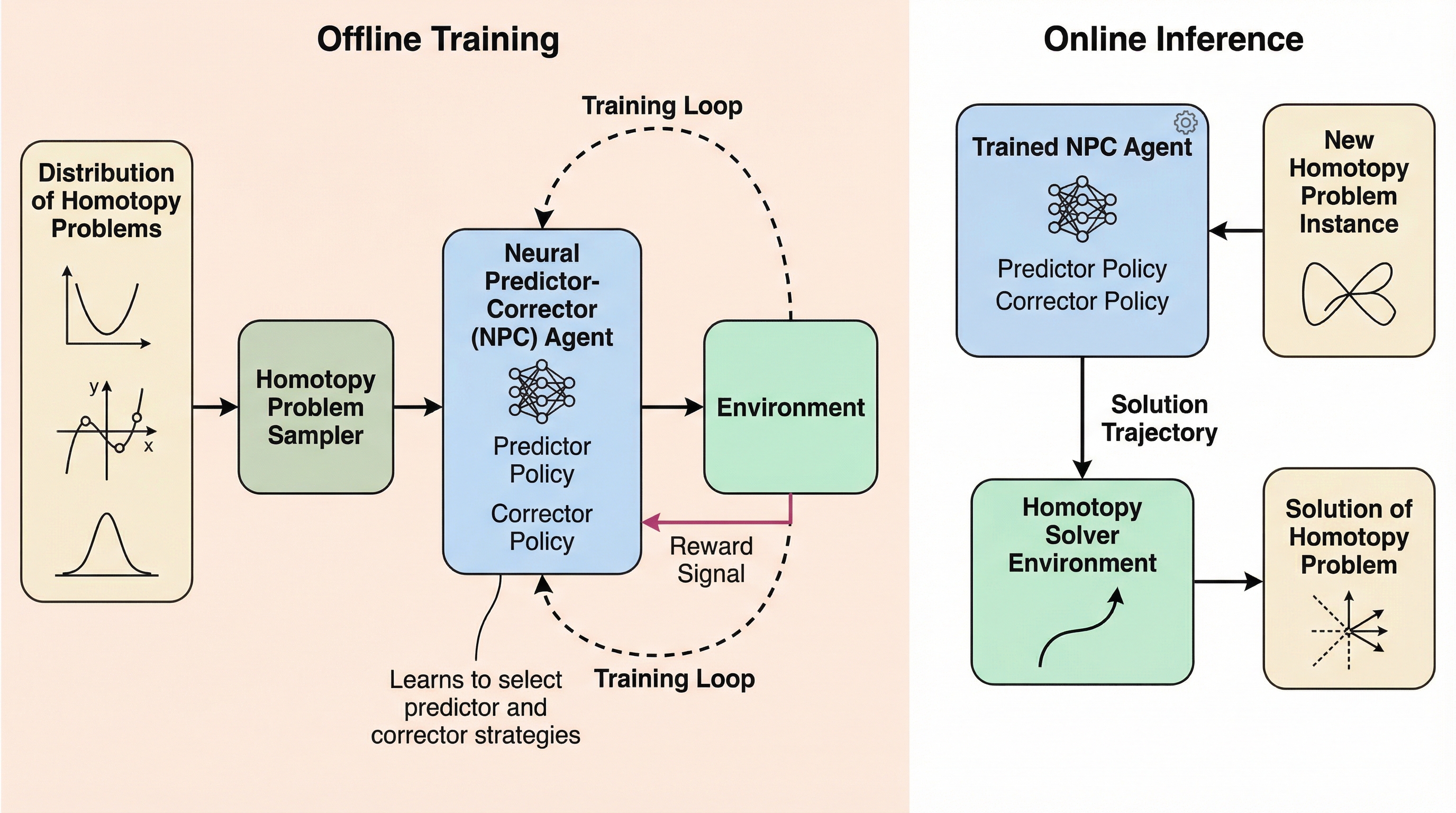
ホモトピー法は、単純な問題の解を複雑なターゲット問題へと連続的に変形させながら追跡する強力な枠組みであるが、従来のソルバーはステップサイズや反復終了条件を人間が設計した固定的なルールに依存しており、効率性と汎用性に限界があった。
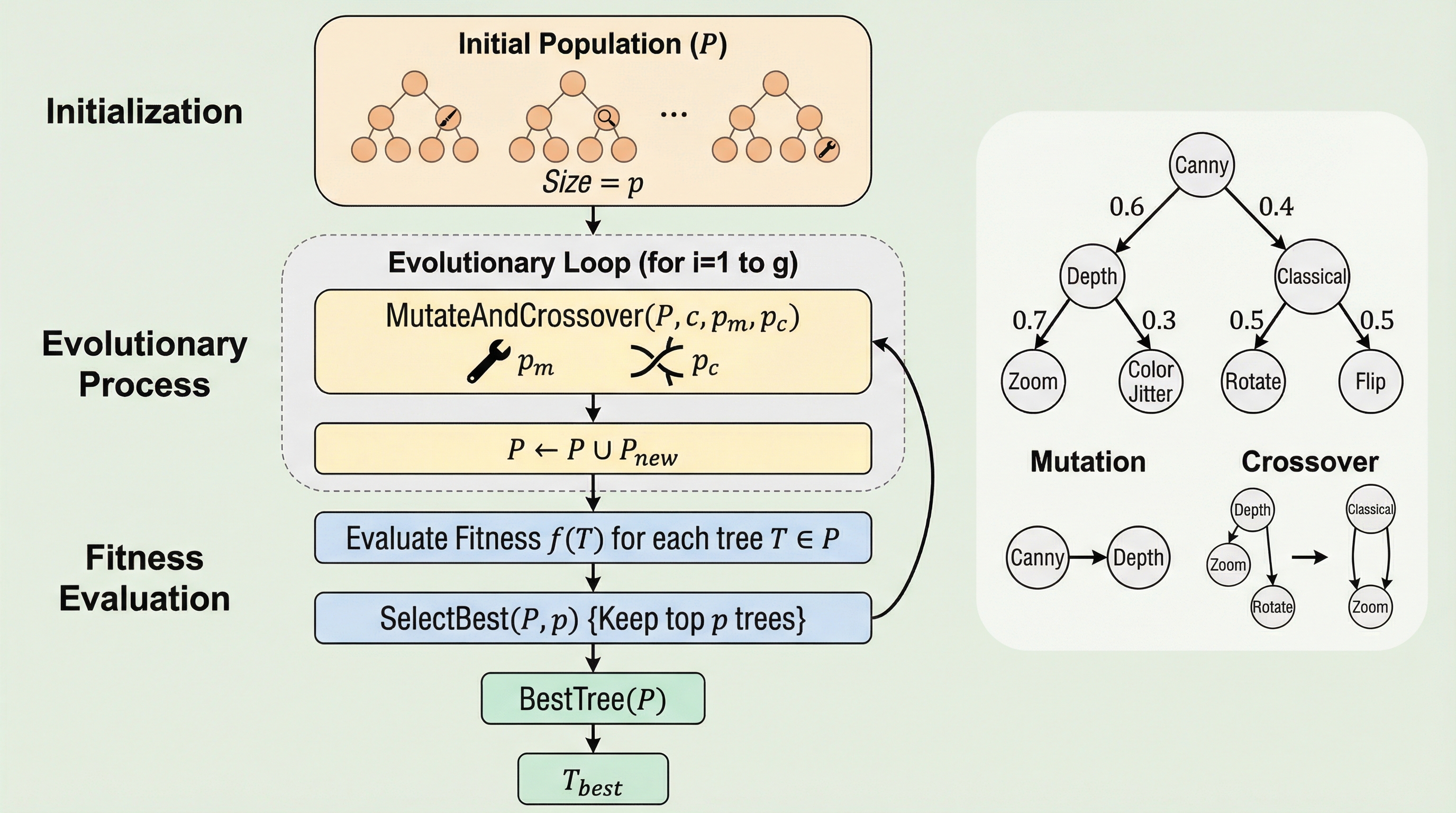
EvoAugは、拡散モデルやNeRFといった最新の生成AI技術と進化アルゴリズムを融合させることで、特定のタスクに最適化されたデータ拡張戦略を自動で構築する革新的な学習パイプラインである。従来の回転や反転といった単純な操作に留まらず、画像から抽出した構造情報を条件として新たな多様性を生み出すことで、データが極端に不足している数ショット学習環境においてもモデルの汎化性能を大幅に向上させる。この手法は、拡張操作を階層的なバイナリツリー構造で表現し、進化の過程で最適な組み合わせを探索することで、ドメイン知識に依存することなく、各データセットの特性に合致した強力な拡張手法を自律的に発見することを可能にしている。
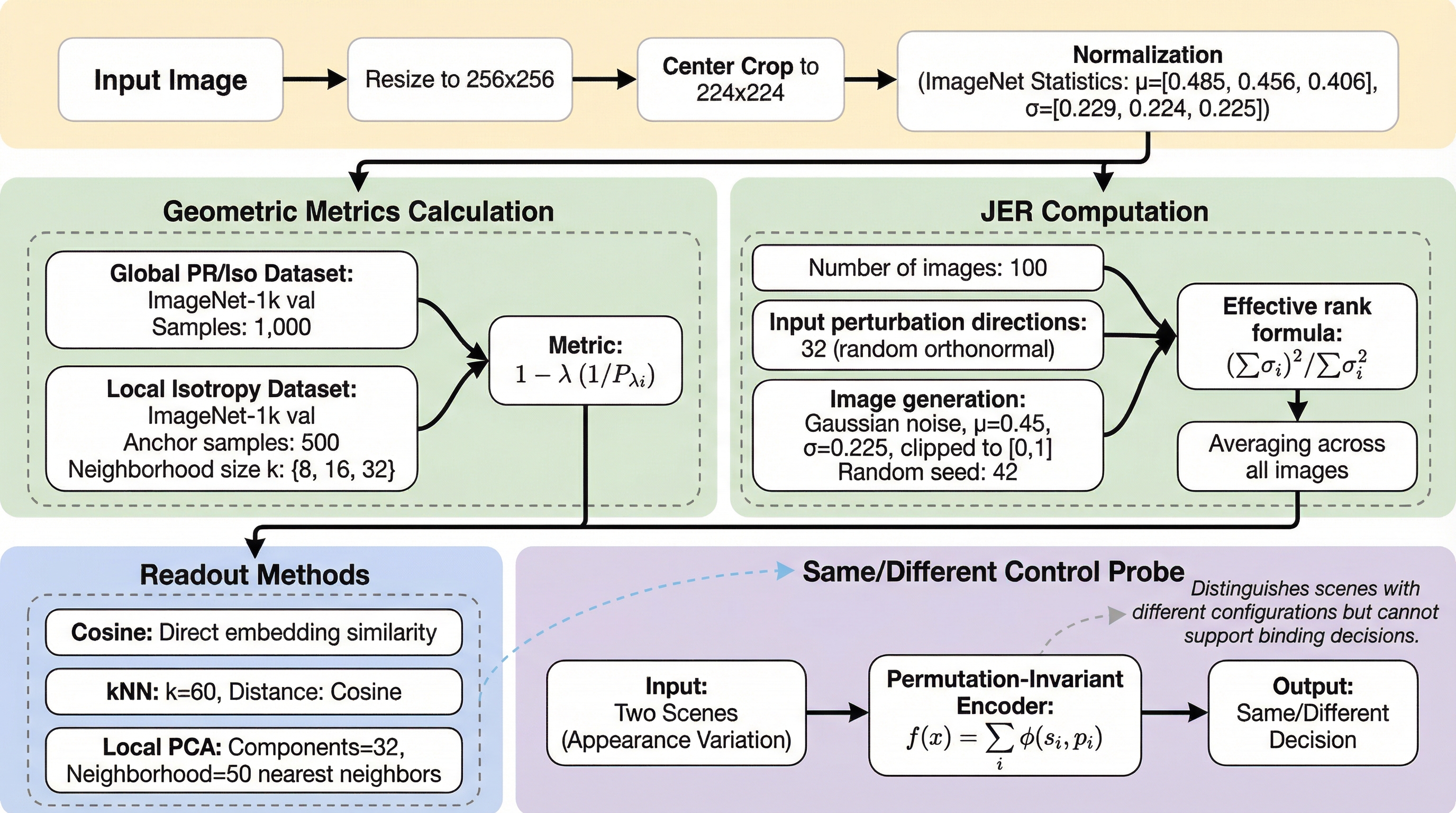
視覚表現学習において、埋め込み分布の均一性や等方性といったグローバルな幾何学的規則性は、要素間の関係性を捉える「構成的結合(Compositional Binding)」能力を予測する指標としては機能せず、統計的にほぼ無相関であることを明らかにした。
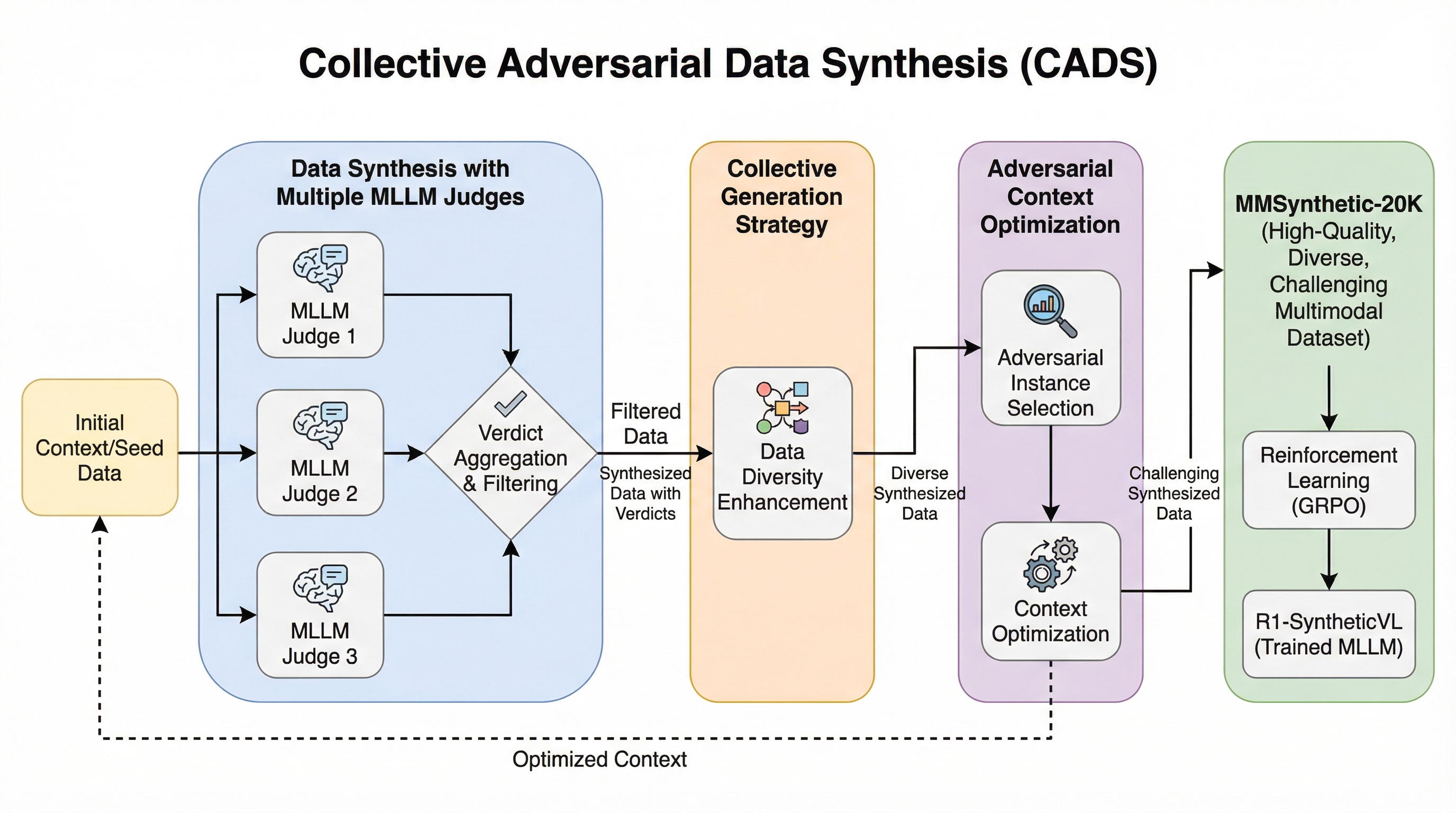
マルチモーダル大規模言語モデル(MLLM)の進化において、高品質な学習データの不足とアノテーションコストの増大が深刻な課題となっており、特に複雑な推論を必要とする実世界のタスクに対応するための思考の連鎖(CoT)を含むデータの入手は極めて困難です。
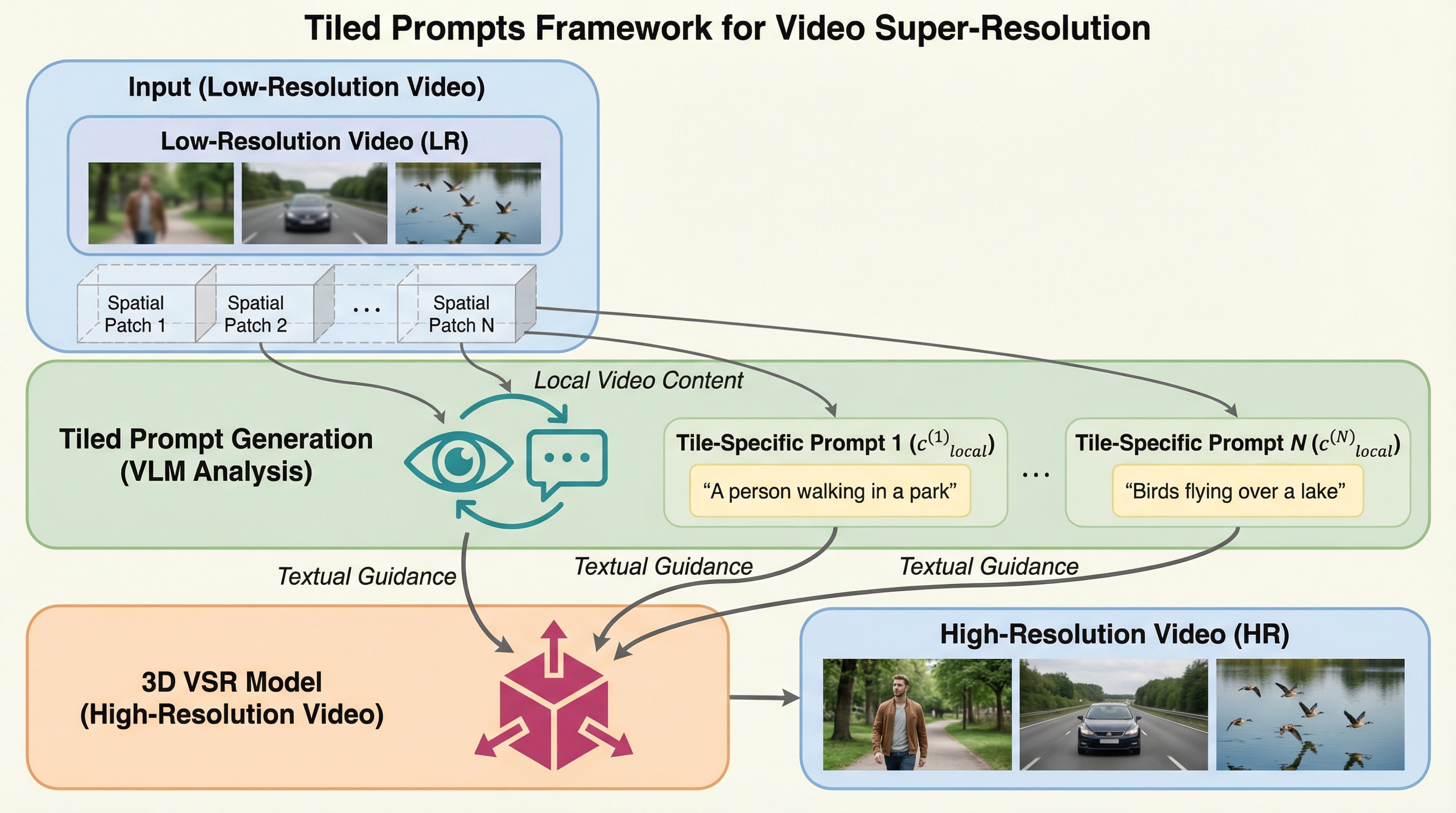
高解像度の画像やビデオの超解像処理において、画像全体を説明する単一のグローバルプロンプトでは、分割された各タイル領域の細部を正確に復元するための情報が不足し、誤った誘導が生じる「プロンプトの不十分さ」という問題が明らかになりました。
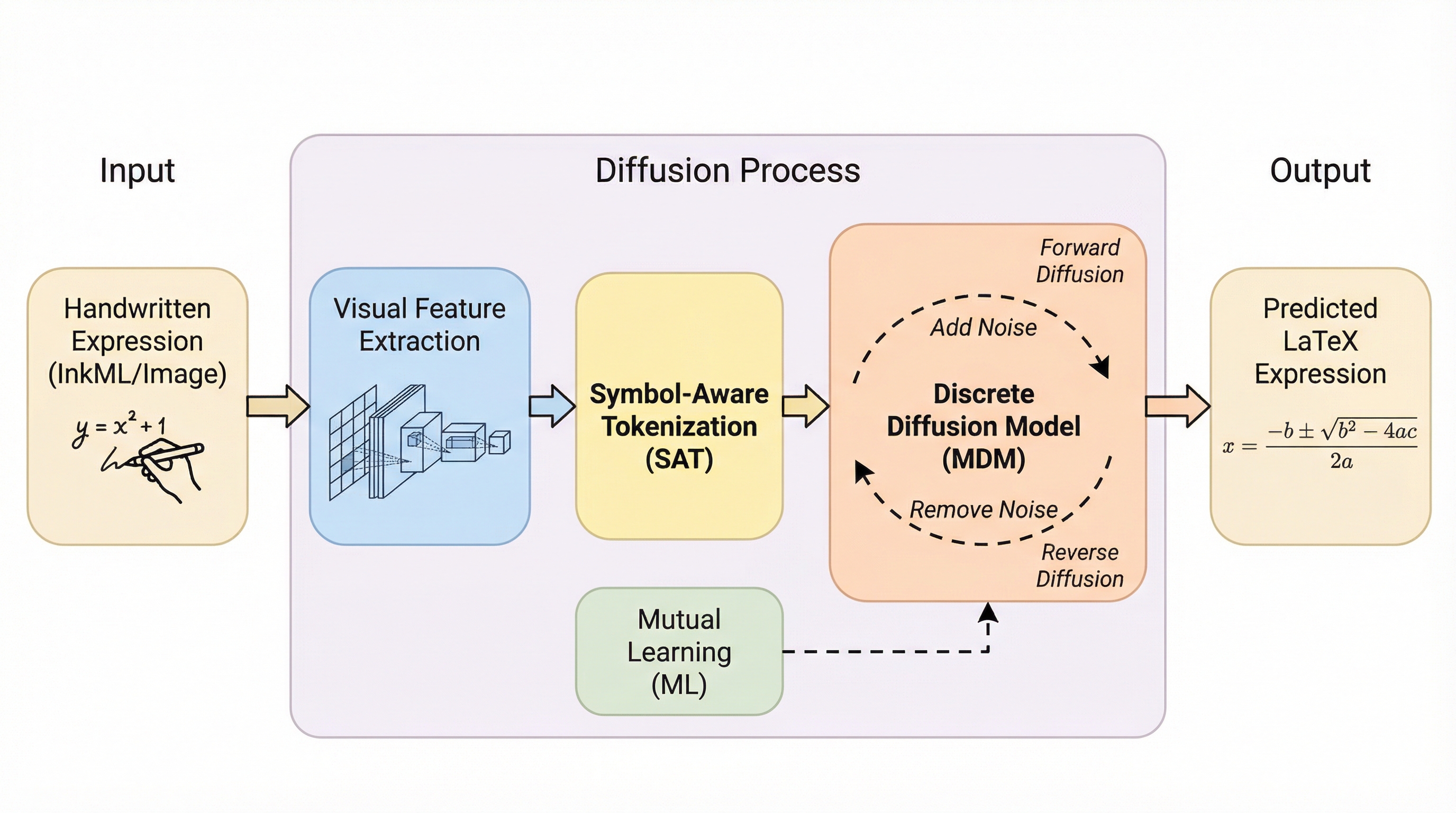
手書き数式認識(HMER)において、従来の逐次的な生成手法ではなく、離散拡散モデルを用いた反復的なシンボル洗練プロセスを提案した。この手法は、先行する予測の誤りが後続に影響する露呈バイアスを排除し、複雑な二次元構造を持つ数式の認識精度を大幅に向上させる。
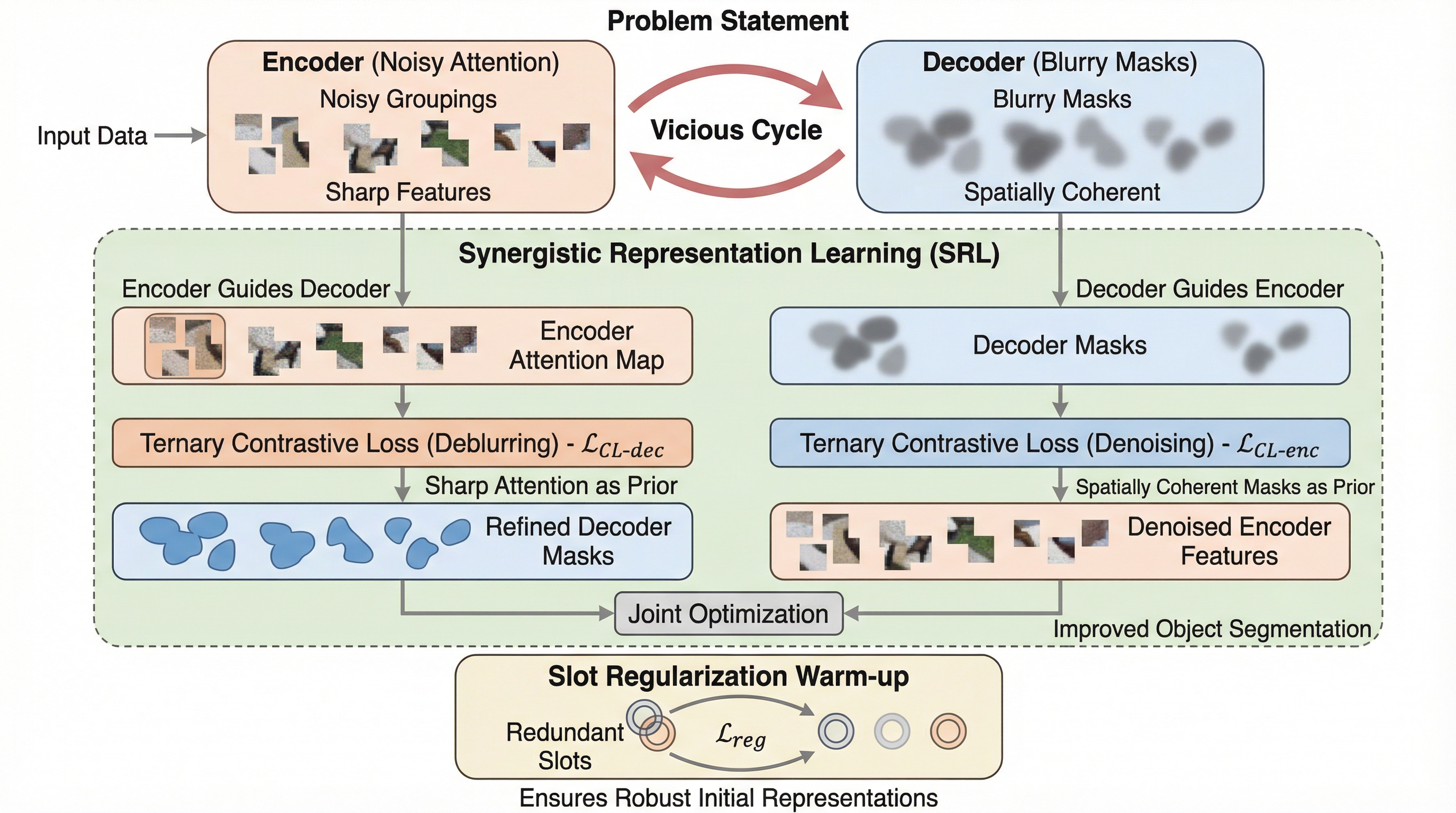
ビデオ物体中心学習において、エンコーダが生成する鋭いがノイズの多いアテンションマップと、デコーダが生成する空間的に一貫しているが境界がぼやけた再構成マップが、互いの学習を阻害し合う「悪循環」を特定しました。
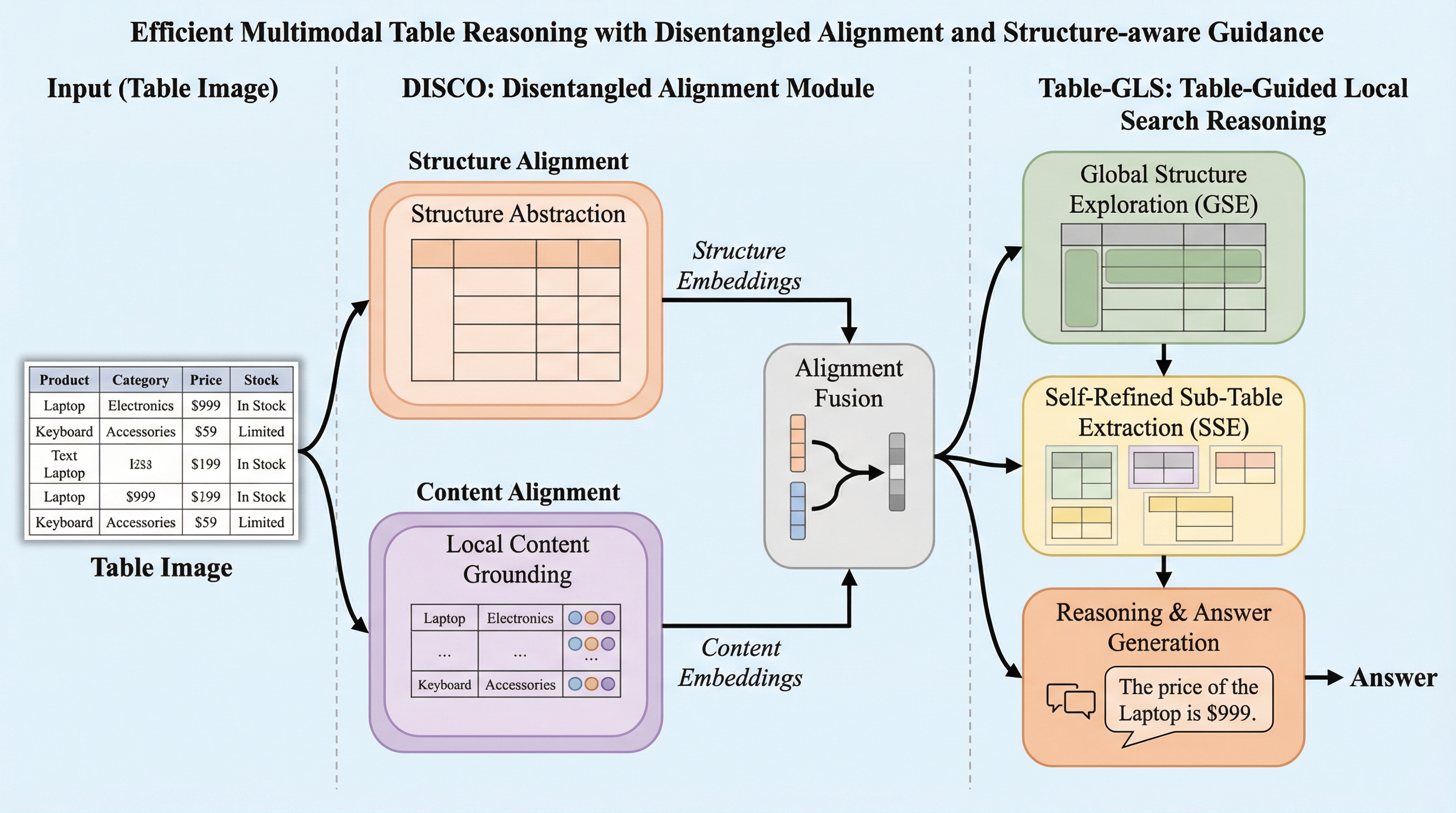
大型視覚言語モデル(LVLM)において、表の複雑なレイアウトと内容が密接に結合している問題を解決するため、構造(骨格)と内容(肉)を分離して学習させる「DISCO」アライメント手法を提案した。 外部ツールや膨大な推論用データに頼らず、表全体から必要な部分を段階的に特定して推論を行う「Table-GLS」フレームワークを導入し、未知の表構造に対しても高い汎用性と信頼性を実現した。 21種類のタスクを用いた検証の結果、わずか1万枚の画像による学習で、従来の大規模データを用いた手法を上回る性能を達成し、効率的かつ解釈可能なマルチモーダル表推論が可能であることを示した。