GeoRC: 地理的位置推定における推論過程を評価するベンチマーク
視覚言語モデル(VLM)は写真の撮影場所を特定する精度で人間に匹敵する能力を見せ始めていますが、その予測に至った根拠を説明する際に、画像内に存在しない情報を捏造するハルシネーションが頻発するという深刻な課題を抱えています。
TL;DR(結論)
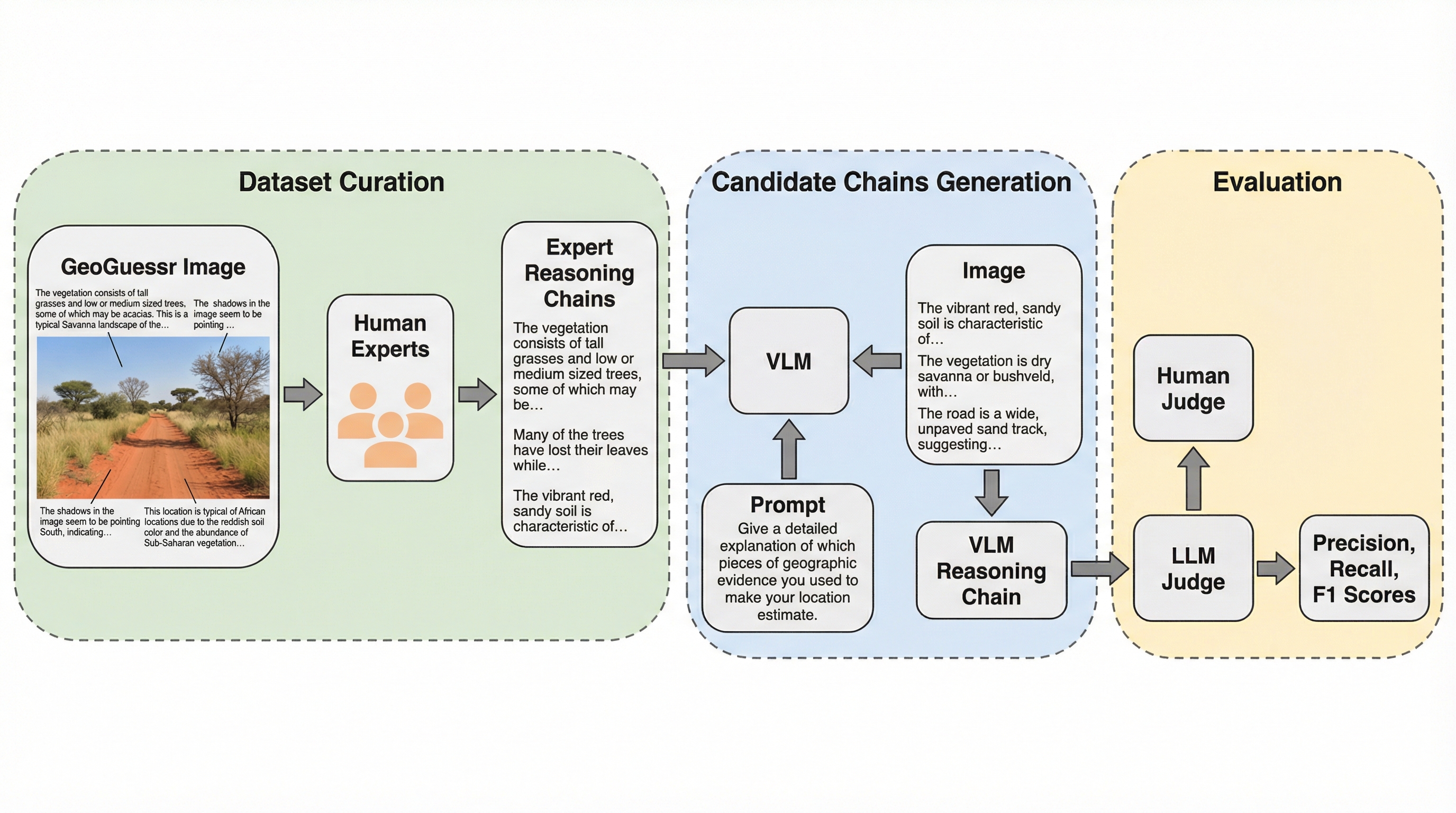
視覚言語モデル(VLM)は写真の撮影場所を特定する精度で人間に匹敵する能力を見せ始めていますが、その予測に至った根拠を説明する際に、画像内に存在しない情報を捏造するハルシネーションが頻発するという深刻な課題を抱えています。 本研究では、GeoGuessrの世界チャンピオンを含む専門家と協力し、500箇所のシーンに対して800件の高品質な推論過程を構築した世界初の地理的推論ベンチマーク「GeoRC」を提案し、モデルの根拠説明能力を厳密に評価する枠組みを確立しました。 評価の結果、GeminiやGPT 5などの最新モデルは予測精度では優秀なものの推論の質では人間に及ばず、LlamaやQwenなどのオープンウェイトモデルにいたっては画像を見ずに推測したのと大差ないレベルで推論に失敗していることが明らかになりました。
なぜこの問題か
地理的位置の特定、いわゆるジオロケーションは、100年以上前から写真の真偽を検証するための重要な技術として注目されてきました。1906年のデナリ登頂疑惑の検証から、現代の調査ジャーナリズムやオープンソース・インテリジェンス(OSINT)における証拠確認に至るまで、その重要性は増すばかりです。近年、CLIPや最新の視覚言語モデル(VLM)の登場により、特定の場所を当てる精度は驚異的な向上を見せ、GeoGuessrのようなゲームにおいてもAIが人間の専門家に匹敵する成果を上げ始めています。しかし、モデルが「なぜその場所だと判断したのか」という推論のプロセスは不透明なままであり、信頼性の面で大きな懸念が残されています。特にVLMは、場所の予測が正解であっても、その根拠として画像内には存在しない標識や特定の植物、インフラなどを勝手に作り出してしまうハルシネーションを起こす傾向が顕著です。人間であれば、道路の白線の種類や電柱の形状、植生、建築様式といった具体的な視覚的特徴を組み合わせて論理的に場所を絞り込むことができますが、AIが同様の監査可能な推論を行えているかを評価する手段がこれまで存在しませんでした。…
核心:何を提案したのか
本研究が提案する「GeoRC」は、AIの地理的推論能力を測定するための世界初のベンチマークデータセットです。このデータセットの最大の特徴は、単に場所の正解座標を与えるだけでなく、その結論に至るまでの「推論の鎖(Reasoning Chains)」を詳細に記録している点にあります。データの質を極限まで高めるため、研究チームはGeoGuessrのトッププレイヤーたちと密接に協力しました。参加した専門家には、世界ランキングの上位0.01パーセントに位置する熟練者や、2025年のワールドカップで優勝した現役の世界チャンピオンが含まれています。彼らは500のシーンに対し、合計800件の高品質な推論過程を執筆しました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related