FAIRT2V:テキストからビデオへの拡散モデルのための学習不要な脱バイアス
テキストから動画を生成する拡散モデル(T2V)において、特定の職業が特定の性別に偏って生成される深刻なジェンダーバイアスが存在することを特定し、その主な原因がCLIPなどの事前学習済みテキストエンコーダーにあることを詳細な分析によって明らかにしました。
TL;DR(結論)
テキストから動画を生成する拡散モデル(T2V)において、特定の職業が特定の性別に偏って生成される深刻なジェンダーバイアスが存在することを特定し、その主な原因がCLIPなどの事前学習済みテキストエンコーダーにあることを詳細な分析によって明らかにしました。 追加の学習やモデルの微調整を一切必要としない革新的なデバイアス用フレームワークであるFAIRT2Vを提案し、アンカーを用いた球面測地線変換によってプロンプトの埋め込みを幾何学的に中立化することで、元の意味を厳密に保ちながらバイアスを効果的に抑制することに成功しました。 最新の動画生成モデルであるOpen-Soraを用いた広範な実験により、動画の視覚的品質や時間的な一貫性を維持したまま、多様な職業における人口統計学的な偏りを大幅に削減できることを実証し、さらにVideoLLMと人間による検証を組み合わせた新しい動画公平性評価プロトコルを確立しました。
なぜこの問題か
近年、拡散ベースのアーキテクチャの進歩により、テキストから動画を生成する技術は急速な発展を遂げています。これらのシステムは、広告、教育、エンターテインメントなどの多様な分野で導入が進んでいますが、生成AIモデルが性別、人種、年齢などの特定のグループを過剰に表現したり、過少に表現したりするという問題が指摘されています。このような人口統計学的なバイアスは、有害な社会的ステレオタイプを強化し、表現の不平等を永続させるリスクがあるため、重大な倫理的懸念を引き起こします。特に、動画生成におけるバイアスについては、これまで画像生成ほど詳細な調査が行われてきませんでした。 既存の研究の多くはテキストから画像を生成するモデルに焦点を当ててきましたが、動画生成においては、時間的なダイナミクス、同一性の持続、および繰り返されるテキスト条件付けといった要素が、バイアスの発生と伝播に新たな課題をもたらします。画像とは異なり、動画における性別関連のバイアスはフレーム間で強化される可能性があり、時間的に持続するステレオタイプにつながる恐れがあります。…
核心:何を提案したのか
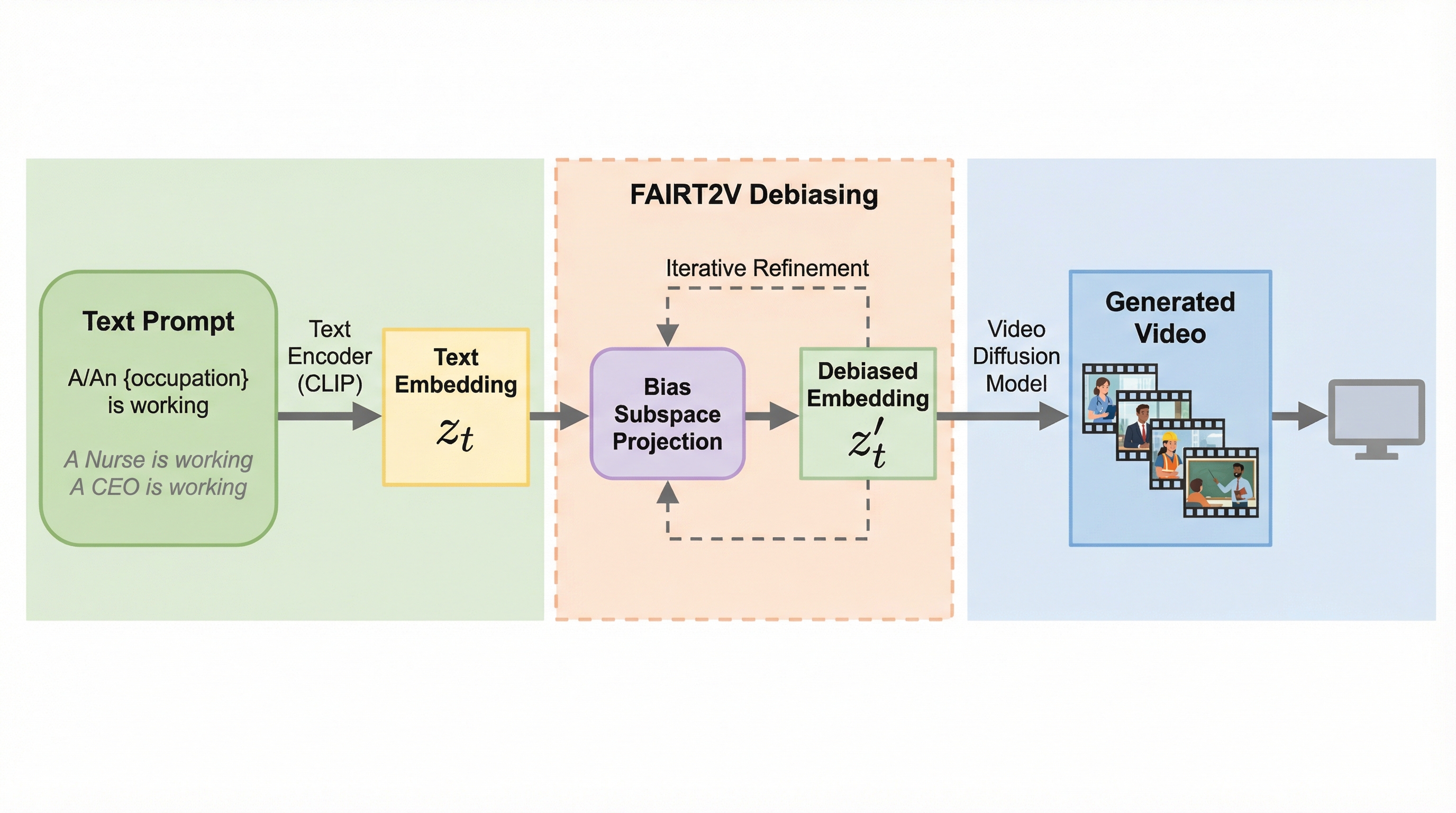
本論文では、テキストから動画を生成する拡散モデルにおける人口統計学的バイアスの最初の体系的な研究として、FAIRT2Vという学習不要のデバイアスフレームワークを提案しています。この研究の核心は、バイアスの主な原因が、生成モデルそのものではなく、条件付けに使用される事前学習済みのテキストエンコーダー(CLIPやT5など)にあることを突き止めた点にあります。これらのエンコーダーは、中立的なプロンプトに対しても、潜在的な性別の関連付けをエンコードしてしまっていることが判明しました。 この洞察に基づき、FAIRT2Vはテキストエンコーダーによって引き起こされるバイアスを、モデルの微調整を行うことなく、プロンプトの埋め込みレベルで中立化します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related