オープンボキャブラリーに基づく機能的な3D人物・シーンインタラクションの生成
FunHSIは、事前の追加学習を必要としないトレーニングフリーなフレームワークであり、オープンボキャブラリーな指示に基づいて、3Dシーン内の特定の機能的要素と人間が正しく相互作用する様子を生成します。
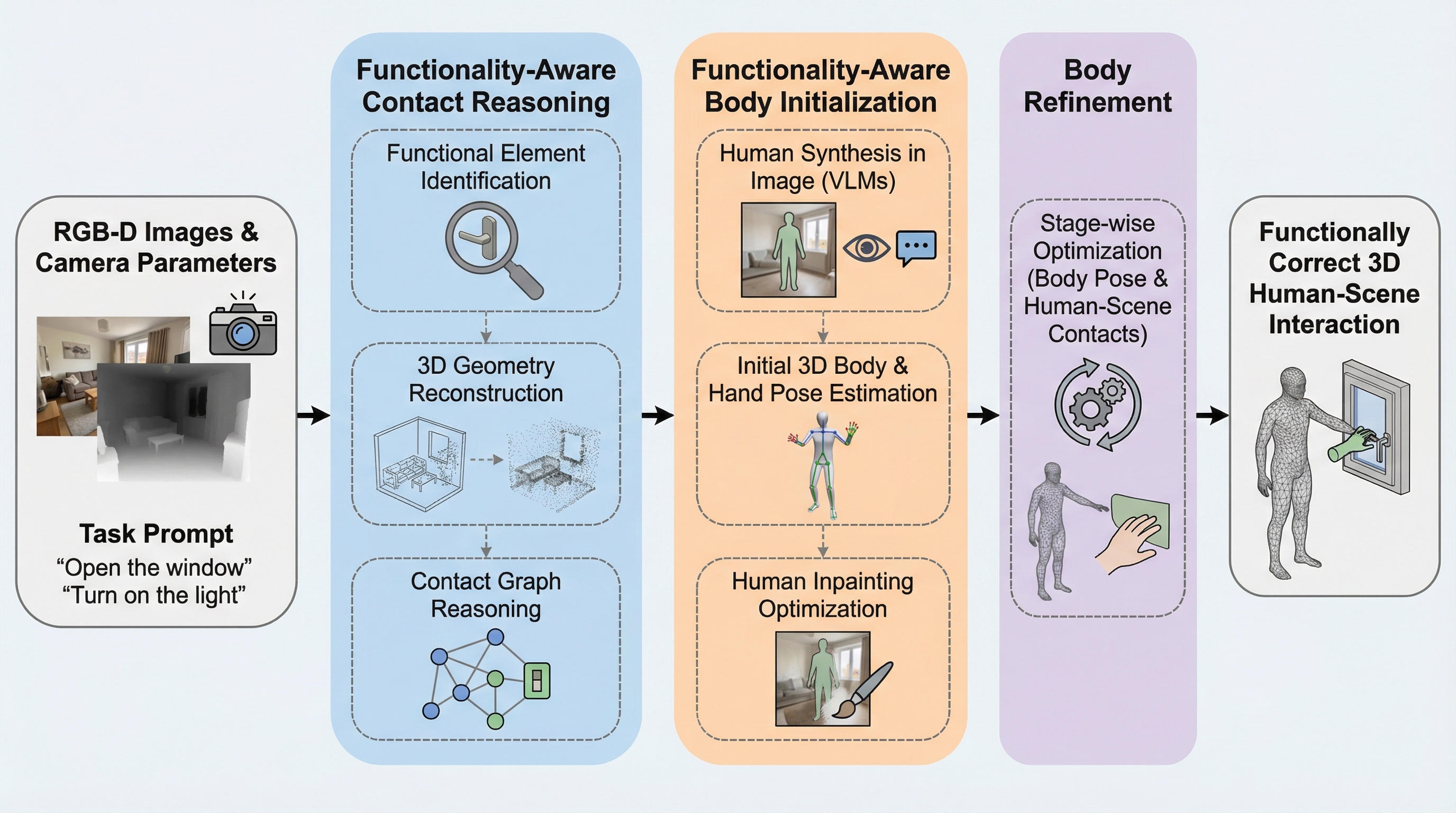
TL;DR(結論)
FunHSIは、事前の追加学習を必要としないトレーニングフリーなフレームワークであり、オープンボキャブラリーな指示に基づいて、3Dシーン内の特定の機能的要素と人間が正しく相互作用する様子を生成します。従来のデータ駆動型手法が大規模なペアデータを必要とし、未知の環境への汎用性に欠けていたのに対し、本手法は視覚言語モデルと大規模言語モデルの推論能力を統合することで、多様なタスクに対してゼロショットで対応可能です。 具体的には、機能認識型コンタクト推論、画像インペインティングを用いた身体初期化、そして物理的妥当性を確保する多段階の最適化プロセスを組み合わせることで、窓を開けるといった微細な操作を含む高品質な3Dポーズ生成を実現しました。これにより、従来の「座る」といった単純な動作だけでなく、特定のハンドルやスイッチを操作するといった機能的なインタラクションを、物理的な矛盾なく生成することが可能になりました。 本手法は、SceneFun3Dデータセットを用いた検証において、既存の最先端手法を上回る正確性と妥当性を示し、さらにスマートフォンで撮影された実世界の都市シーンにおいても高い汎用性を発揮することが確認されました。視覚言語モデルによる意味理解と、コンタクトグラフによる構造的な制約、そして画像合成を起点とした3D最適化を統合したこのアプローチは、エンボディドAIやコンテンツ制作の分野に大きな進歩をもたらします。
なぜこの問題か
3Dシーン内において、人間が周囲の環境と「機能的」に相互作用する様子をシミュレートすることは、エンボディドAIやロボティクス、インタラクティブなコンテンツ制作の分野で極めて重要な課題です。しかし、既存の3D人間・シーンインタラクション(HSI)生成手法には、主に二つの大きな限界が存在していました。第一に、多くのデータ駆動型アプローチは、高品質な3Dインタラクションのペアデータに強く依存しています。これらのモデルは、特定の制御された環境下では高い忠実度を実現できるものの、学習データに含まれない未知のシーンや多様なオブジェクトに対しては汎用性が低く、実世界への適用が困難でした。 第二に、既存のゼロショット手法やトレーニングフリーな手法の多くは、「ソファに座る」や「橋を歩く」といった、一般的な物理的関係や大まかな動作の記述には対応できていますが、より詳細な「機能的」なレベルでの相互作用を十分に扱えていません。現実世界における多くのタスク、例えば「窓を開ける」や「引き出しを引く」といった動作は、単にそのオブジェクトの近くに移動するだけでは不十分です。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related