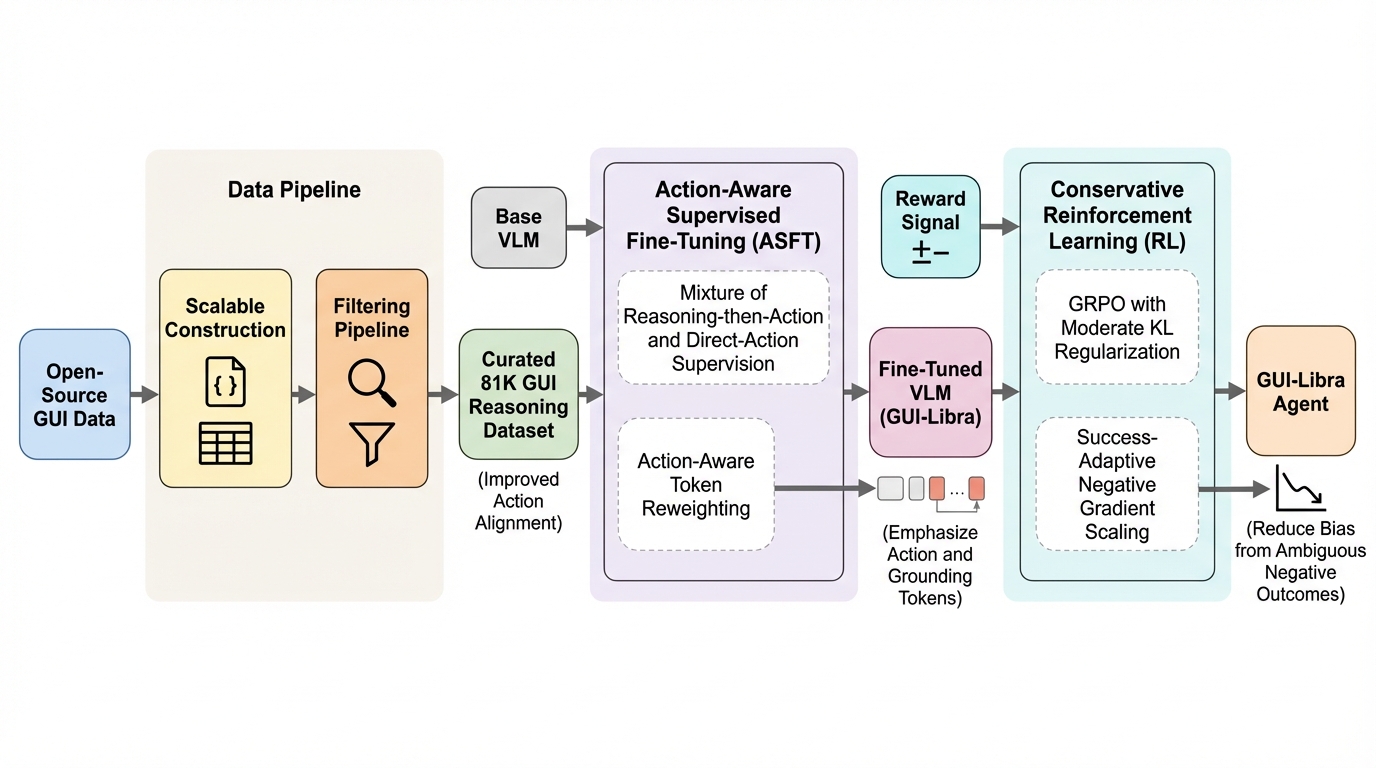
GUI-Libra:ネイティブGUIエージェントを「推論」と「実行可能な行動」の両方に強くする学習レシピ
オープンソースのネイティブGUIエージェントが長い手順のナビゲーションで伸びにくい背景として、行動に整合した高品質な推論データの不足と、GUI特有の難しさを十分に織り込まない事後学習手順の流用があり、GUI-Libraはこの両方を同時にほどく設計になっています。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
オープンソースのネイティブGUIエージェントが長い手順のナビゲーションで伸びにくい背景として、行動に整合した高品質な推論データの不足と、GUI特有の難しさを十分に織り込まない事後学習手順の流用があり、GUI-Libraはこの両方を同時にほどく設計になっています。
数学やコードのように段階的な推論トレースを自動で出せる推論言語モデルでも、モデル内部のパラメータに保存された世界知識を思い出す場面では、最良の知識アクセス用の推論を標準状態で十分に引き出せないことが、閉じた質問応答で確認されています。
SumTabletsは、シュメール語粘土板の楔形文字をUnicode字形列として表したものと、Oraccで公開されている対応翻字を大規模に対にしたデータセットで、翻字を現代的な自然言語処理の課題として扱うための「入力(字形)―出力(翻字)」の基盤を用意しています。
多言語の大規模言語モデルを公平に評価するには、翻訳済みベンチマークの品質ばらつきによる意味のずれや文脈欠落を減らし、指標が誤解を招かない状態に整える必要があります。 / データセット向けとベンチマーク向けを切り分けた完全自動の翻訳フレームワークを用い、テスト時の計算量スケーリング戦略としてUSIと多ラウンド順位付けのT-RANK、さらにSCやBest-of-Nも選べる形で翻訳工程を構成します。 / 東欧・南欧の8言語に人気ベンチマーク/データセットを翻訳して参照ベース指標とLLM-as-a-judgeで検証したところ、既存資源を上回る翻訳が得られ、下流のモデル評価をより正確にし得ることと、枠組みと改善版ベンチマークを公開する点が示されています。
Gemini 3 Deep Thinkで動く数学研究エージェントAletheiaは、研究レベルの数学課題集FirstProofの初回チャレンジにおいて、許容された時間内に10問中6問(2、5、7、8、9、10)を自律的に解けたと、専門家の多数評価に基づいて報告されています。
テキスト・画像・視覚文書・動画などで広く使われるlate interaction型の検索は、文書が長いほど索引の保存量と検索時計算が直線的に増え、マルチモーダルな大規模コーパスでは実運用上の制約になりやすいです。

注意層・MLP層・全線形層で非効率の原因が異なる前提に立ち、各層で相性の良い圧縮を割り当てて組み合わせることで、同じ圧縮率でも単独手法よりパープレキシティを良くできると報告されています。 / 注意の射影は分散保持に基づくSVDで低ランク化し、MLPは活性化統計でニューロン単位の構造化プルーニングを行い、最後に全線形層へ学習後8ビットの対称線形量子化を適用する流れです。 / LLaMA-2-7Bでは最大75%の重みメモリ削減(6.86 GB)とWikiText-2のパープレキシティ改善(5.47→4.91)が示され、GPTQより少ないメモリ(7.16 GB)で最大1.9倍のスループット向上も示されています。
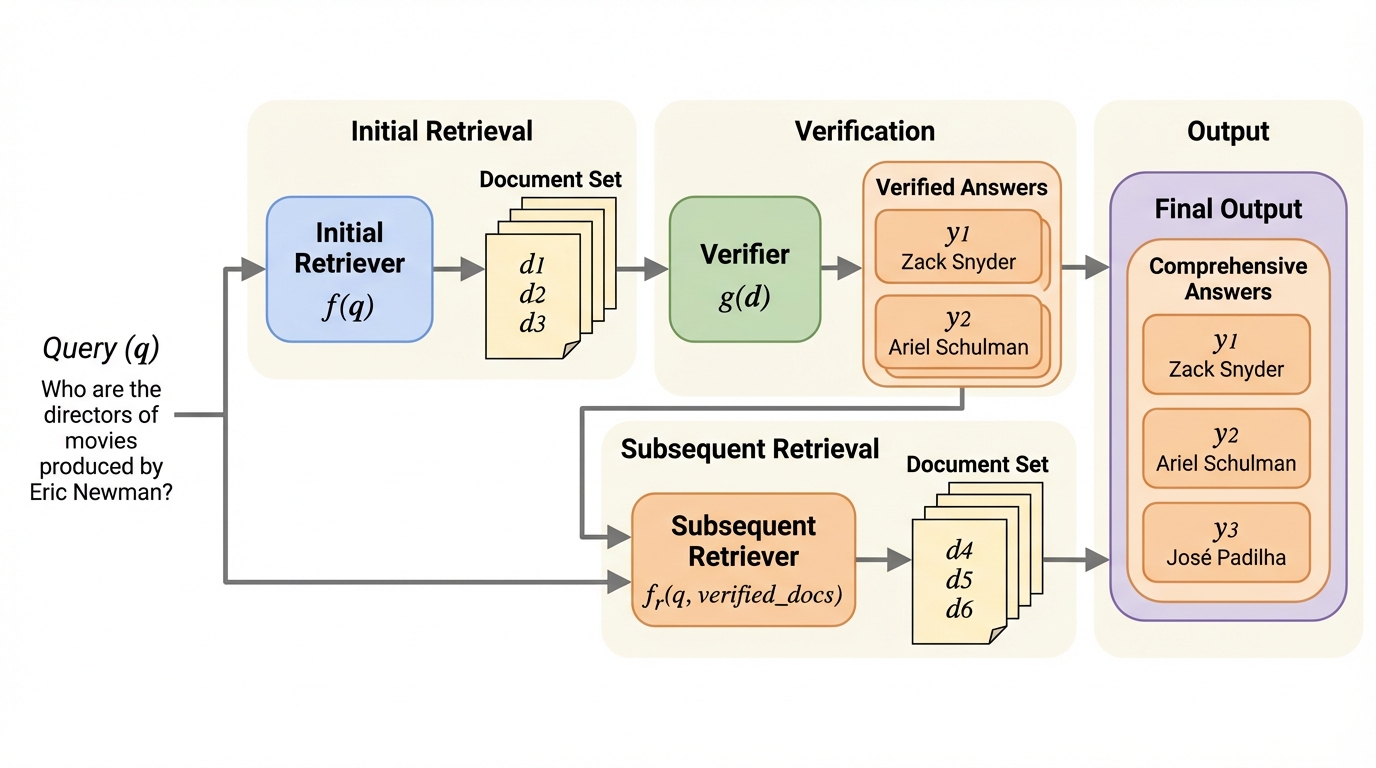
正解が多数あり得る質問では、上位文書を一度だけ並べる検索では答えの偏りや取りこぼしが起きやすく、関連性と網羅性を同時に高める工夫が必要です。 / RVRは、最初の検索結果を検証器でふるいにかけ、その「良い」と判断した文書を質問に連結して次の検索を回し、前の周回で未カバーの答えに対応する文書を追加で狙います。
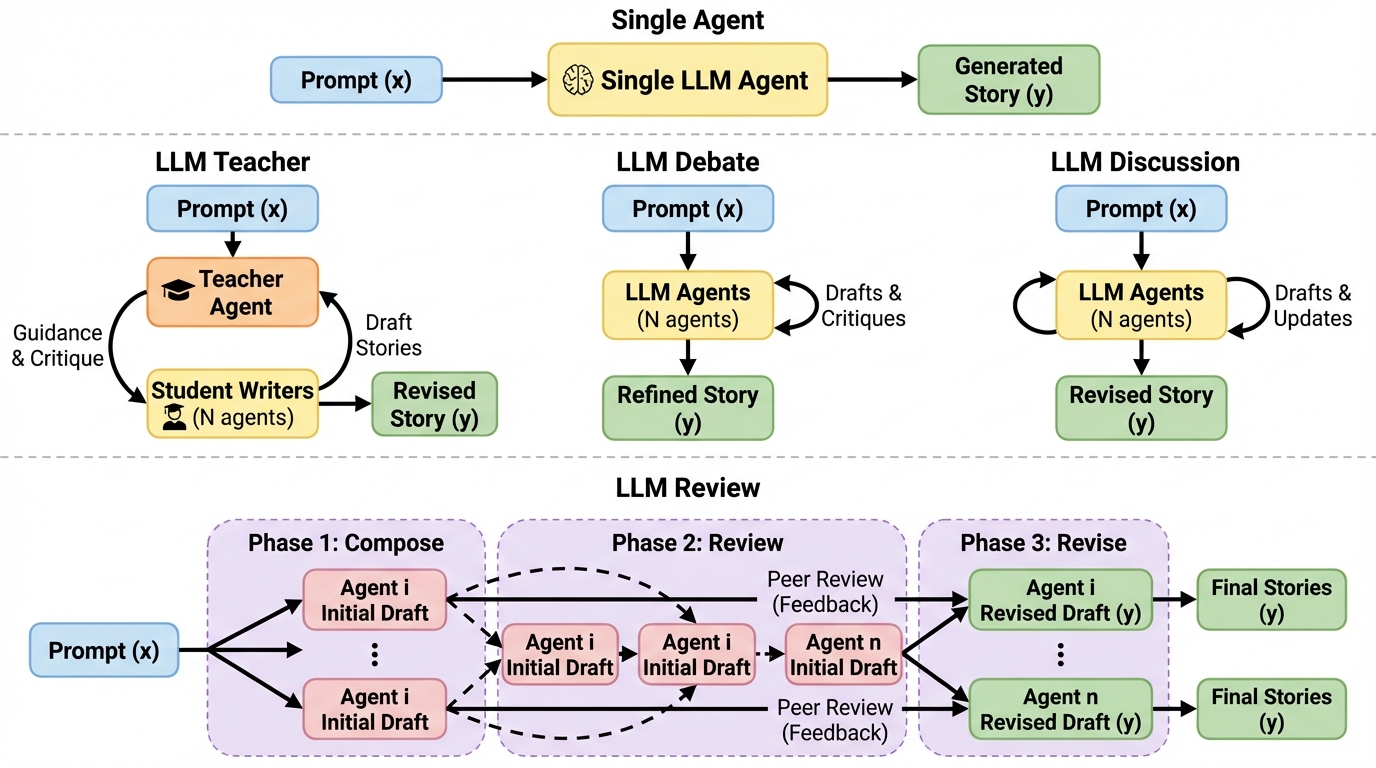
創作では相互作用を増やすほど良くなるとは限らず、エージェント同士が互いの出力に引っ張られて内容が似通う「均質化」が起き得るため、情報の流れそのものを設計対象として扱う必要があります。 / LLM Reviewは、複数エージェントがまず独立に初稿を書き、その後に他者の初稿へ狙いを定めた批評だけを返しつつ、改稿では他者の改稿結果を見せない「ブラインド・ピアレビュー」型の反復を行います。 / サイエンスフィクション短編用データセットSciFi-100と、採点モデルによる評価・人手注釈・規則ベース新規性指標を組み合わせた検証で、提案枠組みが複数のマルチエージェント基準法より一貫して良い結果を示し、相互作用の構造がモデル規模を一部代替し得ることが示唆されます。
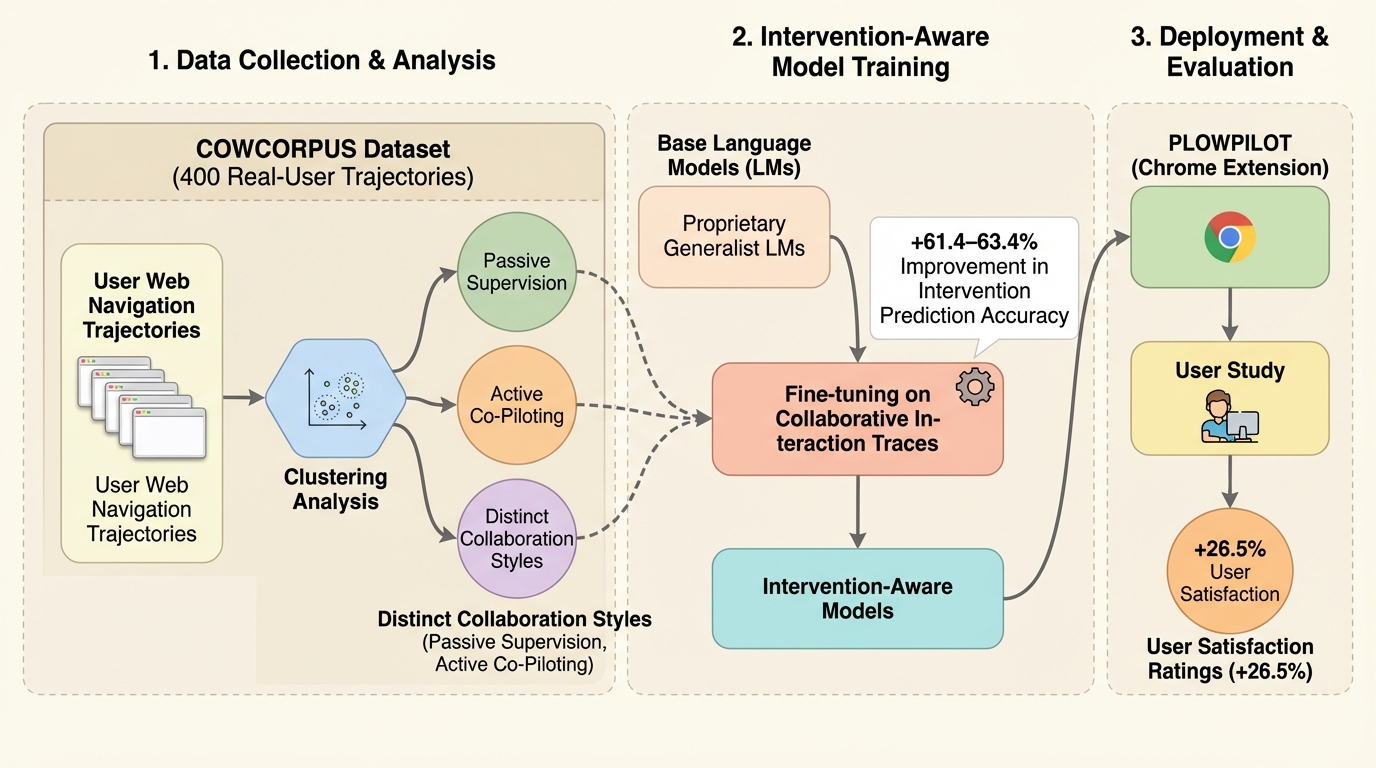
自律的に動くWebエージェントでも実行途中に人が誤り修正や好みの反映のために介入するため、介入が起きるタイミングを見越して振る舞いを調整できるかどうかが協調体験を左右します。 / 400件の実ユーザ軌跡(人とエージェントの行動が4,200件超で交互に記録)を集め、介入の仕方を4つの型に整理したうえで、スクリーンショットとアクセシビリティツリー、履歴、提案行動から次の介入有無を逐次予測するモデルを教師ありで学習します。 / 介入予測はベースの言語モデルより61.4〜63.4%改善し、さらに予測を組み込んだ実運用のWebエージェントはユーザ評価の有用性が26.5%増加しており、介入を構造化して扱うことが適応的な協調につながります。