Zonkey: 微分可能なトークン化と確率的アテンションを備えた階層型拡散言語モデル
Zonkeyは、従来の固定されたトークナイザー(BPE)が抱える非微分性やドメイン適応の困難さを解消するため、生の文字から文書レベルの表現までを完全に微分可能なパイプラインで構築した階層型拡散言語モデルである。
TL;DR(結論)
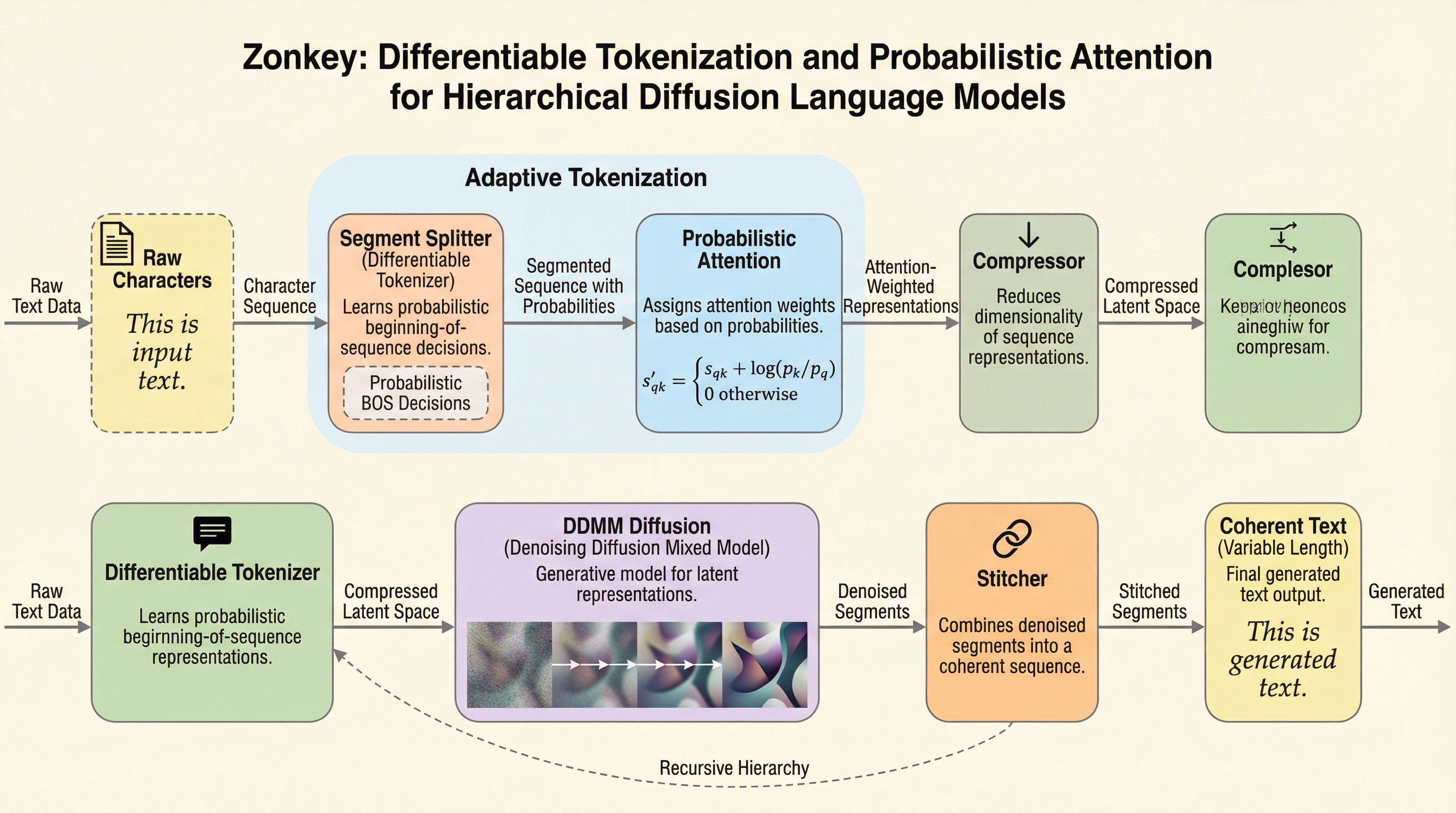
Zonkeyは、従来の固定されたトークナイザー(BPE)が抱える非微分性やドメイン適応の困難さを解消するため、生の文字から文書レベルの表現までを完全に微分可能なパイプラインで構築した階層型拡散言語モデルである。 核心となる「Segment Splitter」は、明示的な教師なしで単語や文の境界といった言語的構造を確率的に学習し、新開発の「Probabilistic Attention」が位置ごとの存在確率を用いることで、可変長のシーケンスを柔軟かつ微分可能な形で処理することを可能にしている。 Wikipediaを用いた単一GPUでの学習において、ノイズから一貫性のあるテキストを生成することに成功しており、階層的な構造が自然に創発することや、従来のトークン化手法に依存しないエンドツーエンドの最適化が次世代の言語モデルとして有効であることを示している。
なぜこの問題か
現在の大型言語モデル(LLM)は、翻訳やコード生成などの分野で劇的な進歩を遂げているが、その根幹には依然として大きなボトルネックが存在している。それは、Byte Pair Encoding(BPE)に代表される、あらかじめ定義されたルールに基づく固定的なトークナイザーの存在である。これらの手法は学習プロセスから切り離されており、微分不可能であるため、モデルの学習中にトークン化のプロセス自体を最適化することができない。その結果、未知語(OOV)の問題や、ノイズの多いテキスト、あるいは専門的なドメイン固有のデータに対する適応能力が制限されてしまうという課題がある。また、従来の階層型モデルにおいては、文字などの低レベルな表現を単語や文といった高レベルな抽象概念に集約する際、固定長の仮定を置くことが多く、これが柔軟性を損なう要因となっていた。 画像生成で強力な性能を発揮する拡散モデルをテキスト生成に応用しようとする試みもなされているが、テキストが離散的なトークンで構成されていることや、ノイズによる意味の歪み、そして出力の長さが固定されがちであるといった問題に直面している。…
核心:何を提案したのか
本論文が提案する「Zonkey」は、生の文字入力から高次の抽象表現までを統合する、完全に微分可能な階層型拡散フレームワークである。このモデルの最大の特徴は、従来の固定ルールによるトークン化を、学習可能な「Segment Splitter(セグメント・スプリッター)」に置き換えた点にある。このスプリッターは、シーケンスの開始位置(BOS)を確率的に決定することで、明示的な教師なしに単語の境界や文の始まりといった言語的に意味のある区切りを自律的に学習する。この微分可能なトークン化を実現するために、新たに「Probabilistic Attention(確率的アテンション)」というメカニズムが導入された。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related