テスト時の強化学習における分布を考慮した報酬推定手法「DARE」
大規模言語モデルがラベルのないデータで自己改善するテスト時強化学習において、従来の多数決方式が抱えていた「正解が少数派の場合に有益な情報を捨ててしまう問題」と「初期の誤答を強化し続ける確認崩壊」を理論的に特定し、解決策を提示しました。
TL;DR(結論)
大規模言語モデルがラベルのないデータで自己改善するテスト時強化学習において、従来の多数決方式が抱えていた「正解が少数派の場合に有益な情報を捨ててしまう問題」と「初期の誤答を強化し続ける確認崩壊」を理論的に特定し、解決策を提示しました。 提案手法「DARE」は、全回答の出現頻度とトークンごとの不確実性(エントロピー)を組み合わせた経験的分布に基づき報酬を推定し、さらに低頻度かつ低不確実な回答に探索ボーナスを付与することで、多数派に埋もれた正解からも学習を可能にする画期的なフレームワークです。 難関数学タスクであるAIME 2024において相対的に25.3%の性能向上を達成したほか、科学的推論や一般推論のベンチマークでも既存手法を圧倒し、未知のデータセットに対する高い汎化性能と学習の安定性を実証することで、外部ラベルに頼らない自己改善の新たな基準を確立しました。
なぜこの問題か
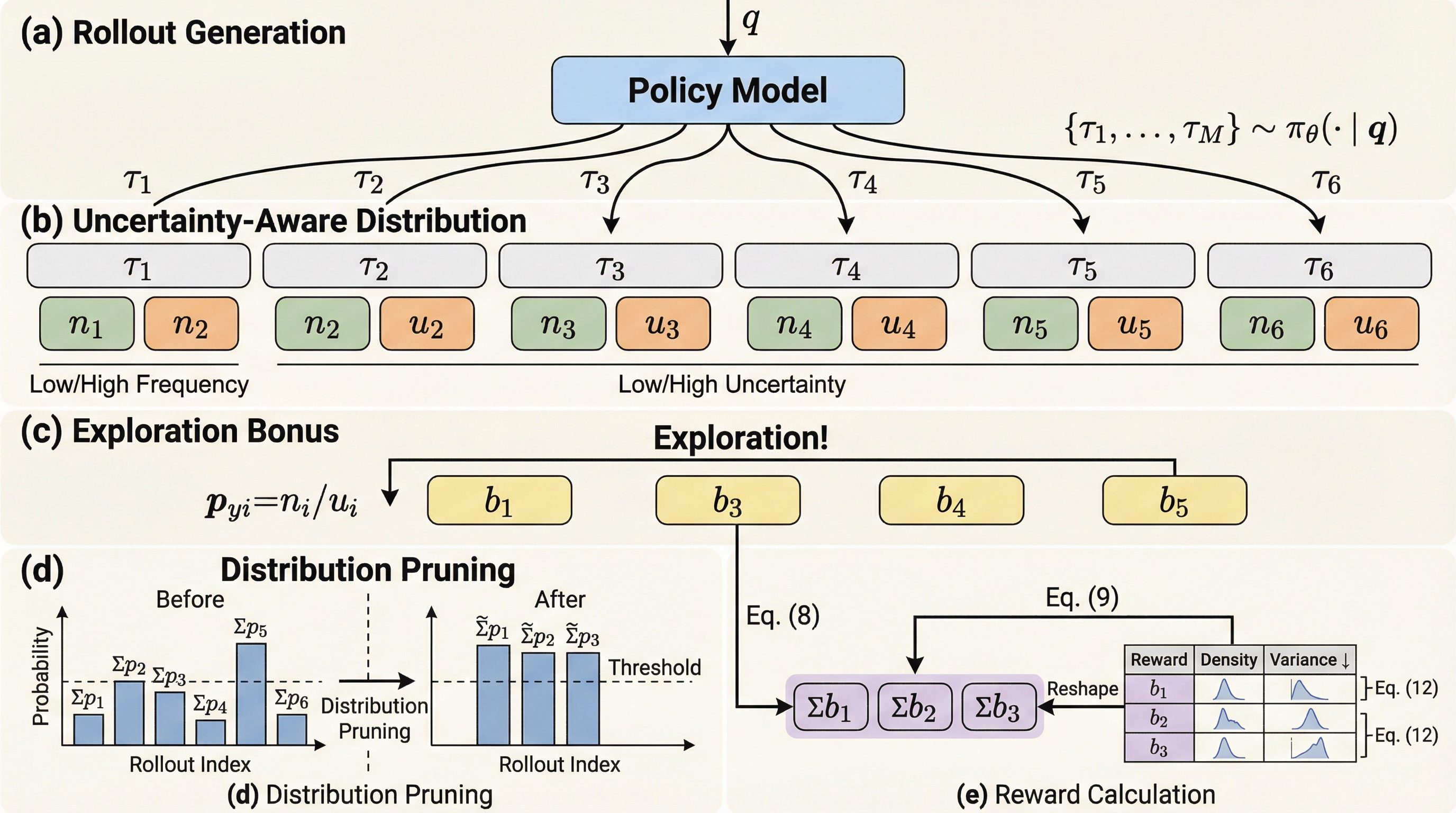
大規模言語モデル(LLM)が、外部からの正解ラベル(教師データ)が得られない環境下で、自分自身の出力を用いて推論能力を向上させる「テスト時強化学習(TTRL)」は、モデルの適応能力を極限まで引き出す手法として注目されています。しかし、このプロセスの成否は、モデルが生成した複数の回答(ロールアウト)から、いかにして「何が正しいか」という報酬信号を正確に構築できるかにかかっています。既存の多くの手法では、複数の回答の中で最も頻度が高いものを正解の代理とする「多数決(MV)」方式が採用されてきましたが、本論文はこの方式には理論的かつ実用的な二つの致命的な限界があると指摘しています。 第一の限界は「情報の損失(情報崩壊)」です。多数決は、モデルが生成した多様な推論プロセスの分布を、単一の「最も多い回答」という点に圧縮してしまいます。論文内の定理2.1で示されているように、この圧縮プロセスによって、多数派ではないものの正解である回答に含まれる有益な情報が完全に排除されてしまいます。…
核心:何を提案したのか
本研究では、多数決のように結果を単一の点に集約して情報を捨てるのではなく、生成された回答の「経験的分布」全体を報酬信号として活用する新しい手法「DARE(Distribution-Aware Reward Estimation)」を提案しています。DAREの核心的な思想は、回答の出現頻度という表面的な指標だけでなく、その回答に至る推論プロセスの「内部的な不確実性」を報酬設計の核に組み込むことにあります。これにより、多数派の回答を盲目的に追従するのではなく、分布に基づいたより信頼性の高いガイドをポリシーの最適化に提供することが可能になります。 DAREは主に三つの革新的な要素で構成されています。一つ目は「不確実性を考慮した経験的分布」の構築です。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related