大規模言語モデルを用いたグラフ情報に基づく行動生成による身体化されたタスク計画
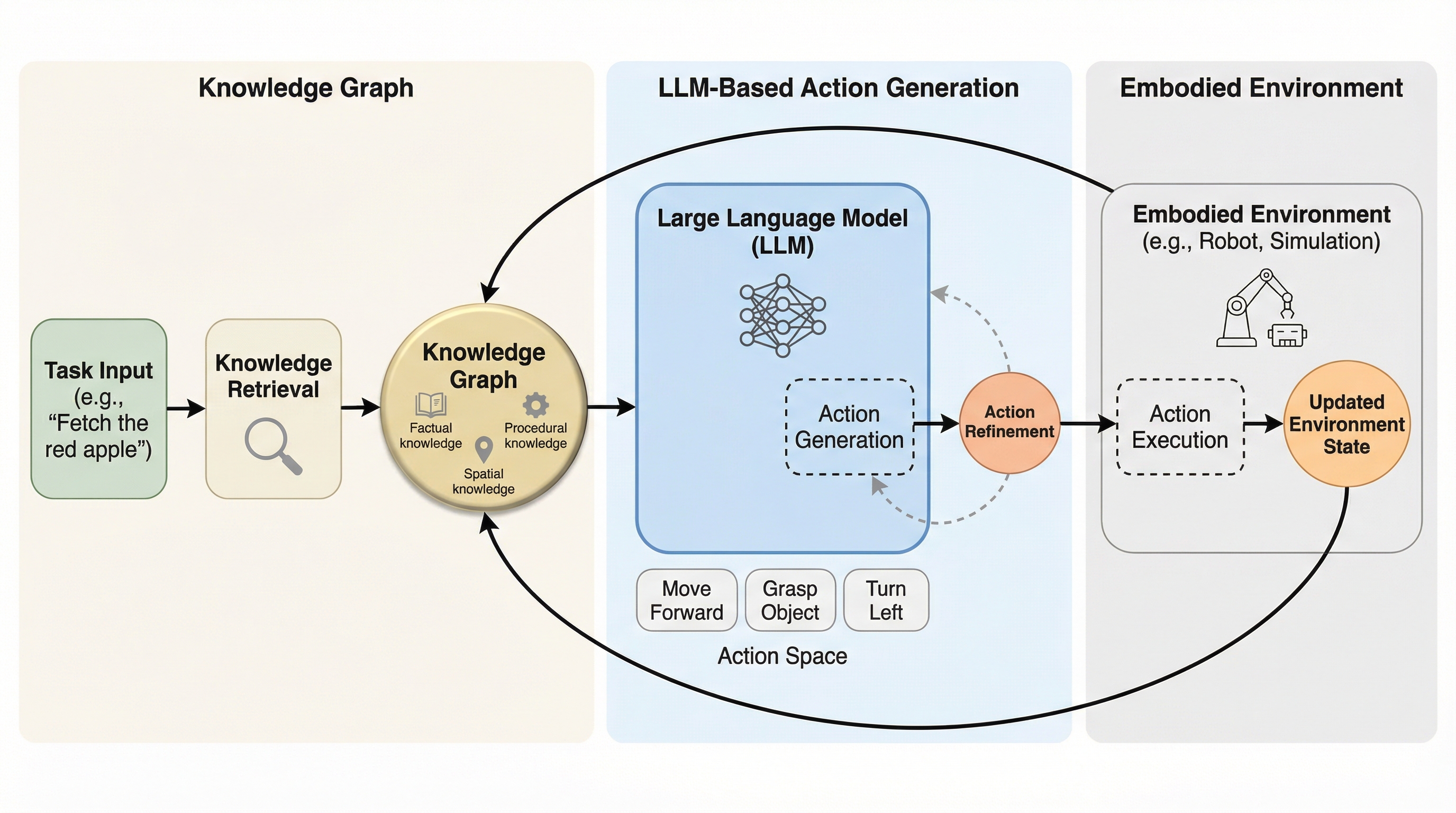
大規模言語モデルを身体化エージェントとして活用する際、長期的な計画立案において文脈の逸脱や物理的制約を無視した幻覚が生じるという課題に対し、二層のグラフ構造を用いた記憶アーキテクチャ「GiG(Graph-in-Graph)」を提案しました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
大規模言語モデルを身体化エージェントとして活用する際、長期的な計画立案において文脈の逸脱や物理的制約を無視した幻覚が生じるという課題に対し、二層のグラフ構造を用いた記憶アーキテクチャ「GiG(Graph-in-Graph)」を提案しました。
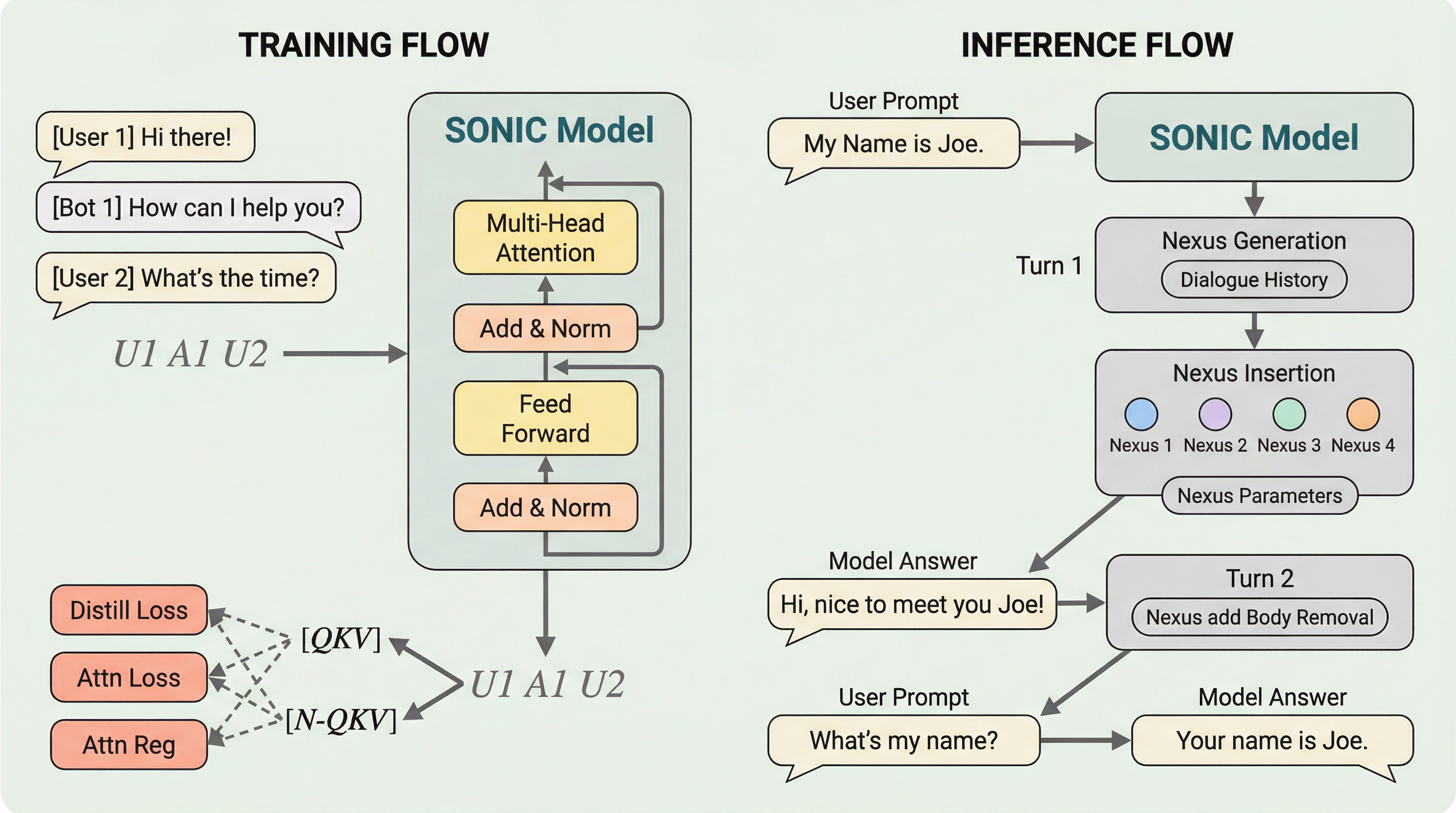
大規模言語モデルのマルチターン対話において、履歴の増加に伴い線形に肥大化するKVキャッシュのメモリ問題を解決するため、履歴セグメントを「Nexus」と呼ばれる少数の学習可能なトークンに集約して圧縮する新しいフレームワーク「SONIC」が提案されました。
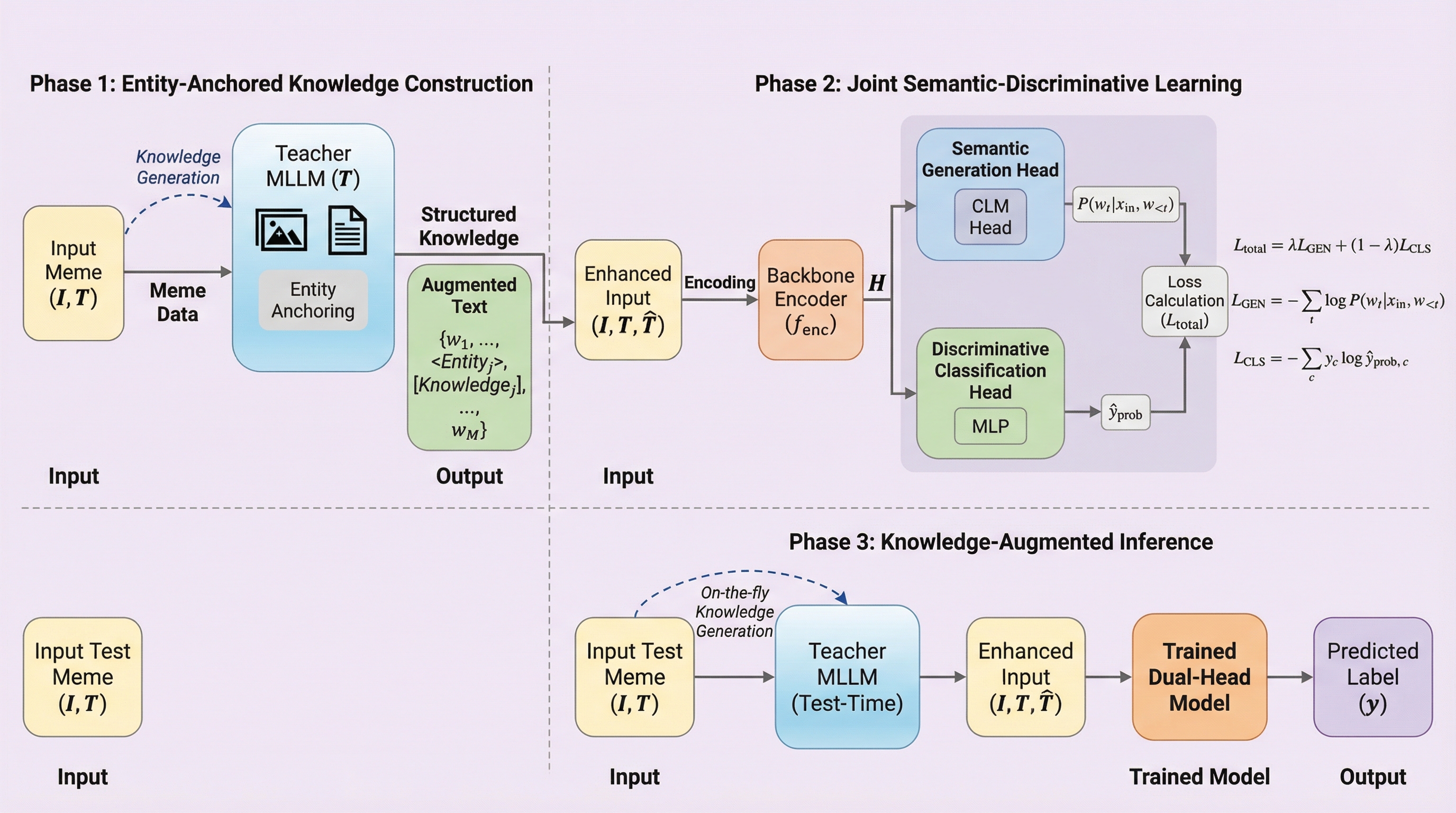
インターネット上のミームは比喩や文化的背景に深く依存しており、従来のモデルでは表面的な情報の処理に留まり、潜在的な有害性を見逃す「知識と文脈の断絶」という課題がありました。本研究が提案するKIDフレームワークは、視覚的エンティティに背景知識を紐付ける「エンティティ・アンカー型知識注入」と、意味生成と分類を同時に最適化する「デュアルヘッド学習」により、複雑な推論を可能にします。英語、中国語、ベンガル語の5つのデータセットを用いた実験の結果、既存の最先端手法を2.1%から19.7%上回る性能を記録し、多言語や低リソースな環境においても極めて高い汎用性と堅牢性を示しました。
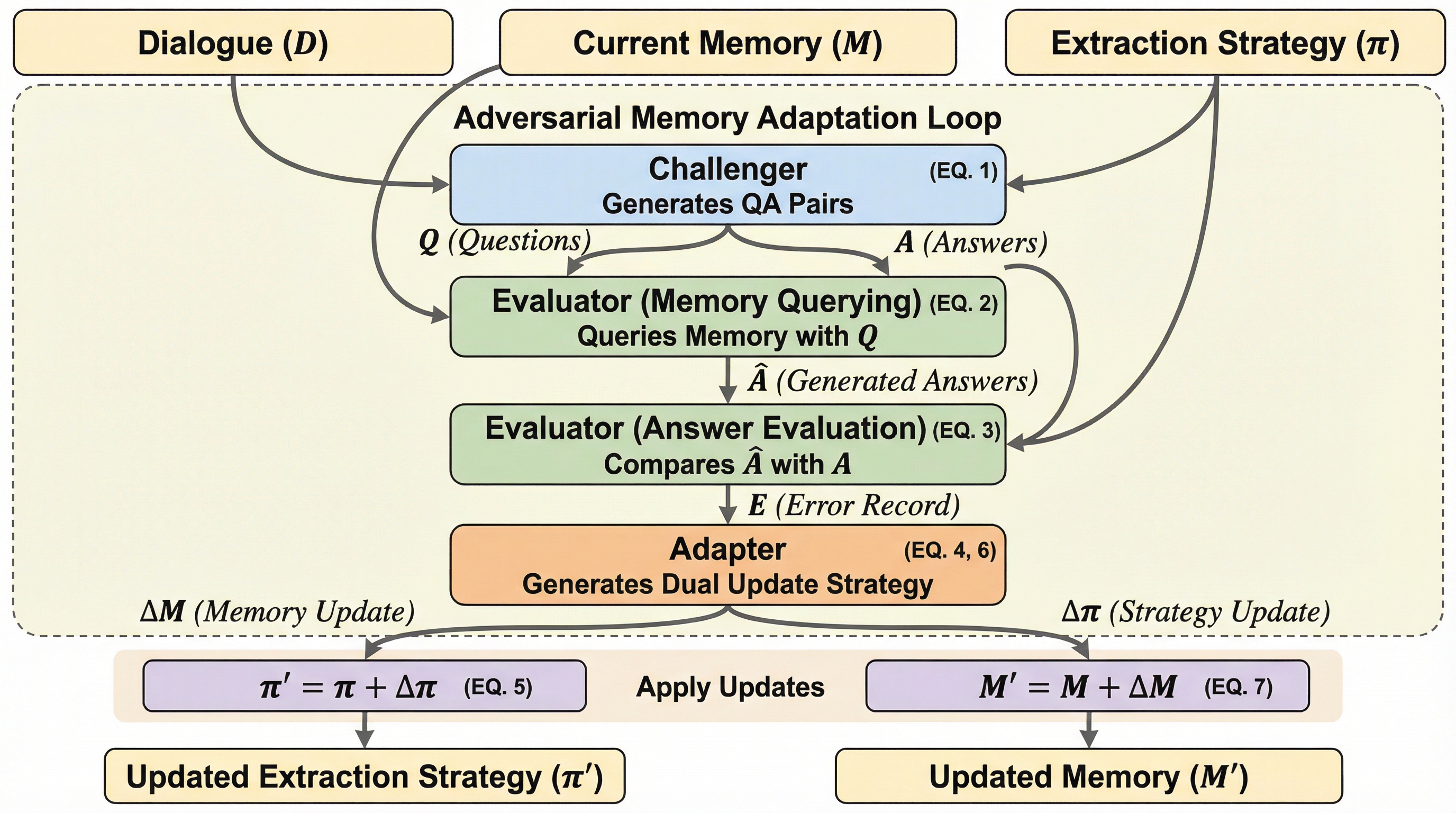
従来の会話エージェントにおけるメモリシステムは、オフラインでのメモリ構築がタスクに依存せず固定されていたため、実際のタスク要求との間に乖離が生じるという課題がありました。 本研究が提案する「敵対的メモリアダプテーション(AMA)」は、チャレンジャー、エバリュエーター、アダプターという3つのエージェントを用いてタスク実行をシミュレーションし、メモリ構築と更新をタスク目標に動的に適合させます。 長期対話ベンチマークであるLoCoMoを用いた実験の結果、AMAは既存の複数のメモリシステムに統合可能であり、下流タスクにおける推論性能と適応性を大幅に向上させることが確認されました。
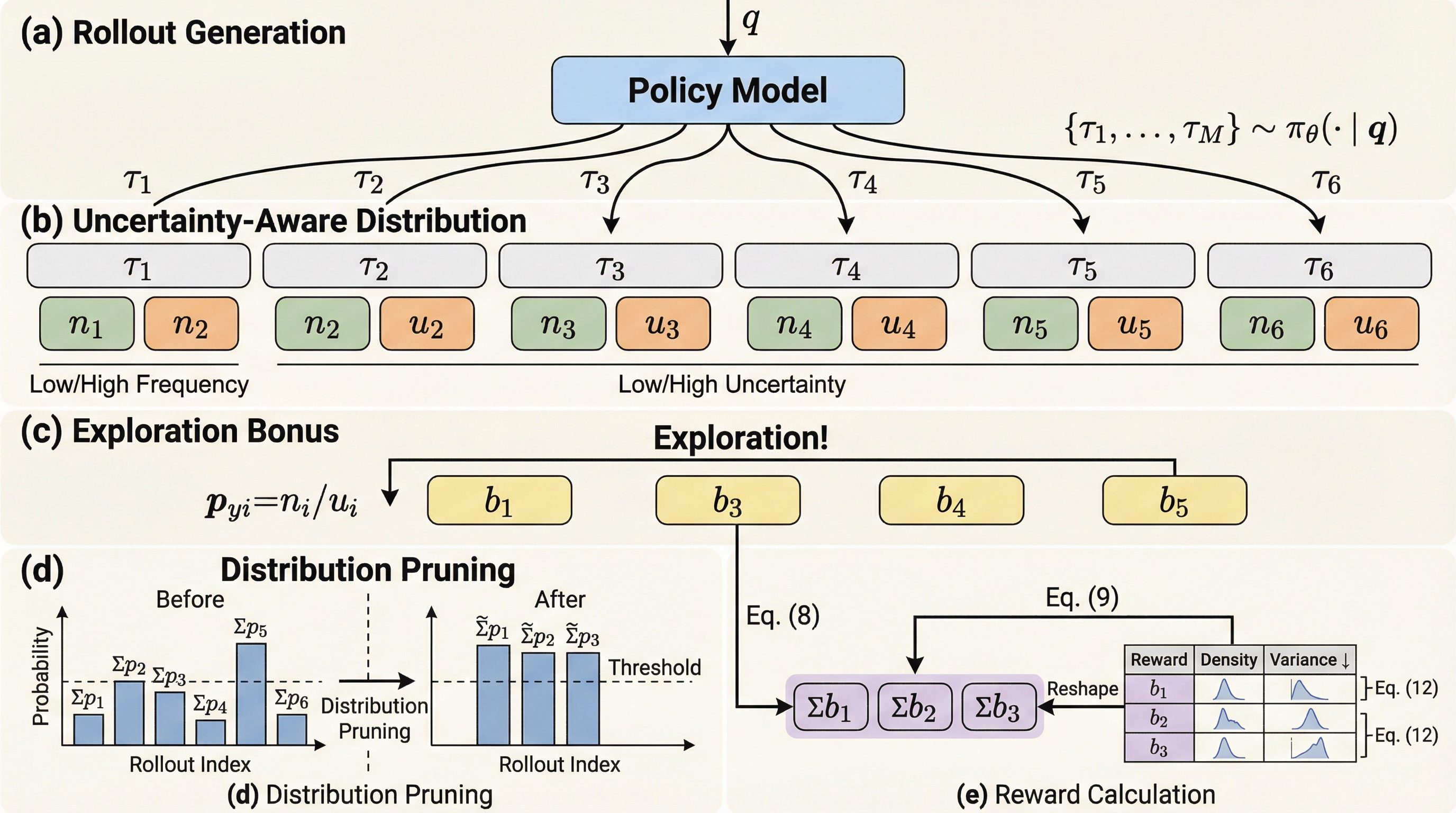
大規模言語モデルがラベルのないデータで自己改善するテスト時強化学習において、従来の多数決方式が抱えていた「正解が少数派の場合に有益な情報を捨ててしまう問題」と「初期の誤答を強化し続ける確認崩壊」を理論的に特定し、解決策を提示しました。
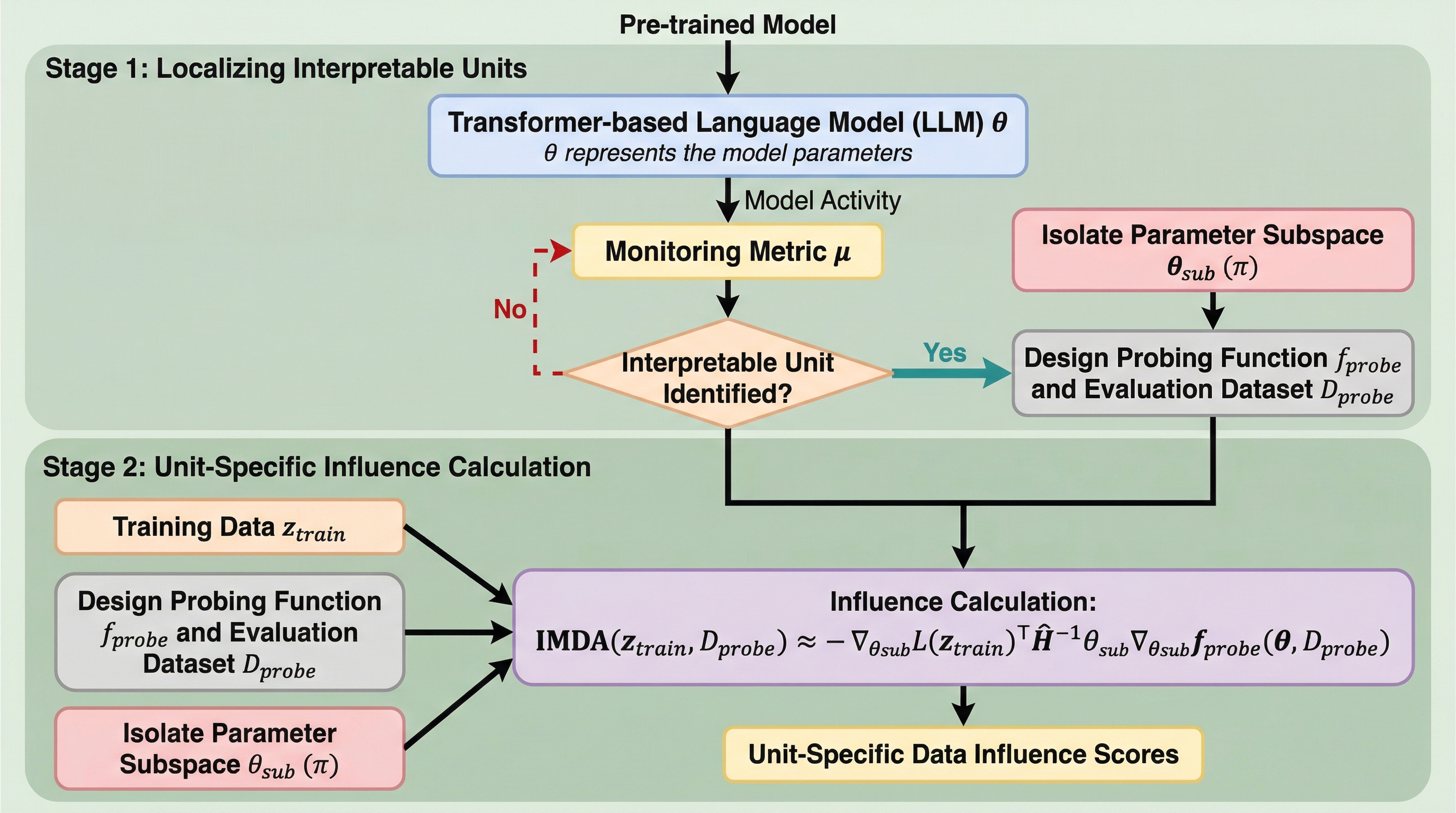
Mechanistic Data Attribution(MDA)は、大規模言語モデル(LLM)内部の誘導ヘッドなどの解釈可能なユニットが、学習データのどのサンプルから影響を受けて形成されたのかを特定する新しいフレームワークです。
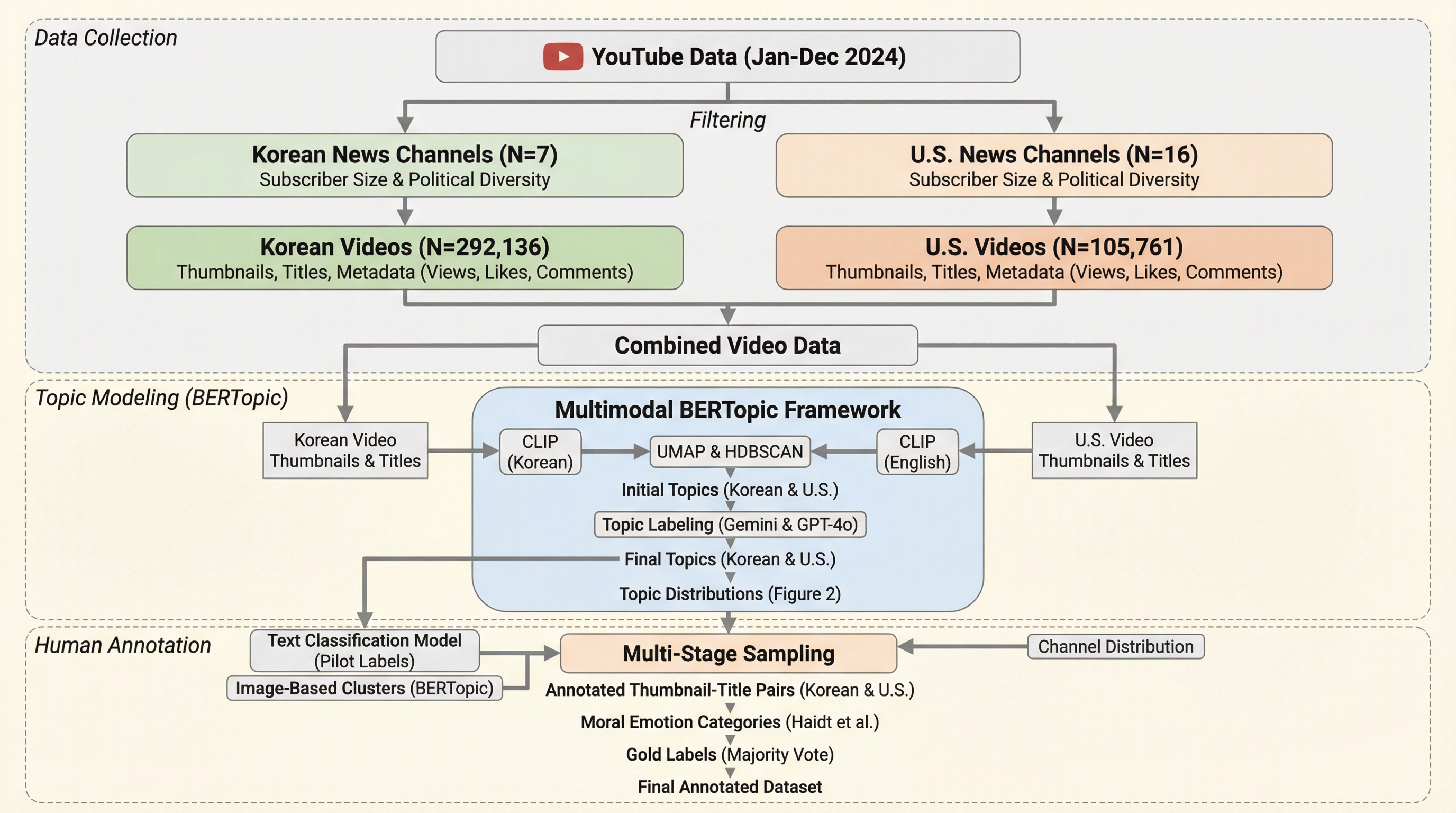
本研究は、YouTubeのニュース動画において、サムネイル画像とタイトルを組み合わせたマルチモーダルな分析を行い、道徳的感情のフレーミングがユーザーの関与に与える影響を韓国と米国の比較を通じて調査した。
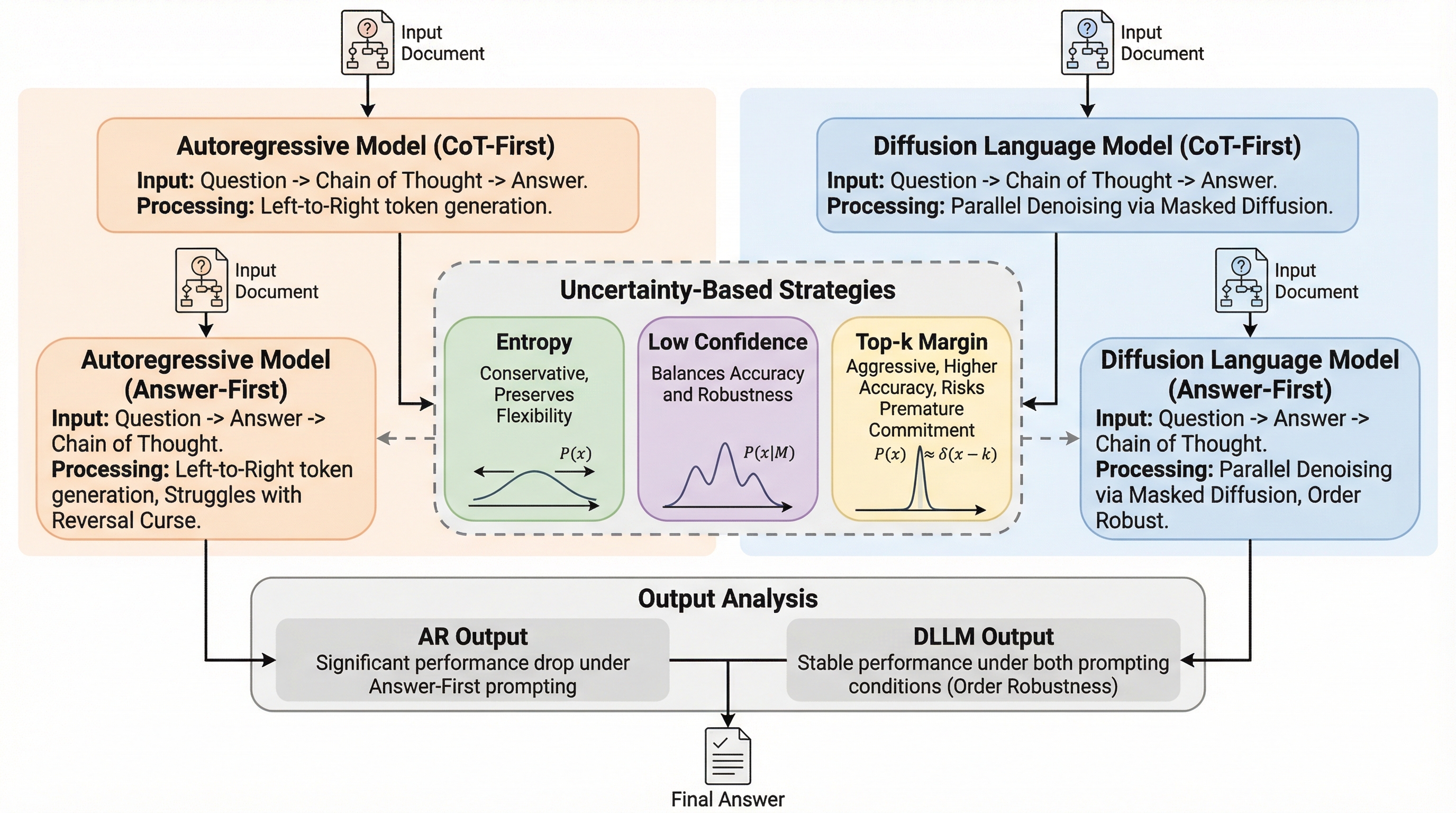
従来の自己回帰型モデルは、回答を推論より先に出力する形式において、十分な思考の前に回答を確定させてしまうため精度が最大67%低下するという構造的な課題がありました。本研究では、マスク拡散言語モデル(MDLM)が、出力の物理的な位置に関わらず確信度の高いトークンから処理することで、回答を先に出力する場合でも高い精度を維持する「順序に対する堅牢性」を持つことを明らかにしました。新ベンチマーク「ReasonOrderQA」を用いた検証により、拡散モデルは単純な推論ステップを複雑な回答よりも先に安定させることで、内部的な推論を先行させてから回答を確定させる仕組みを持っていることが示されました。
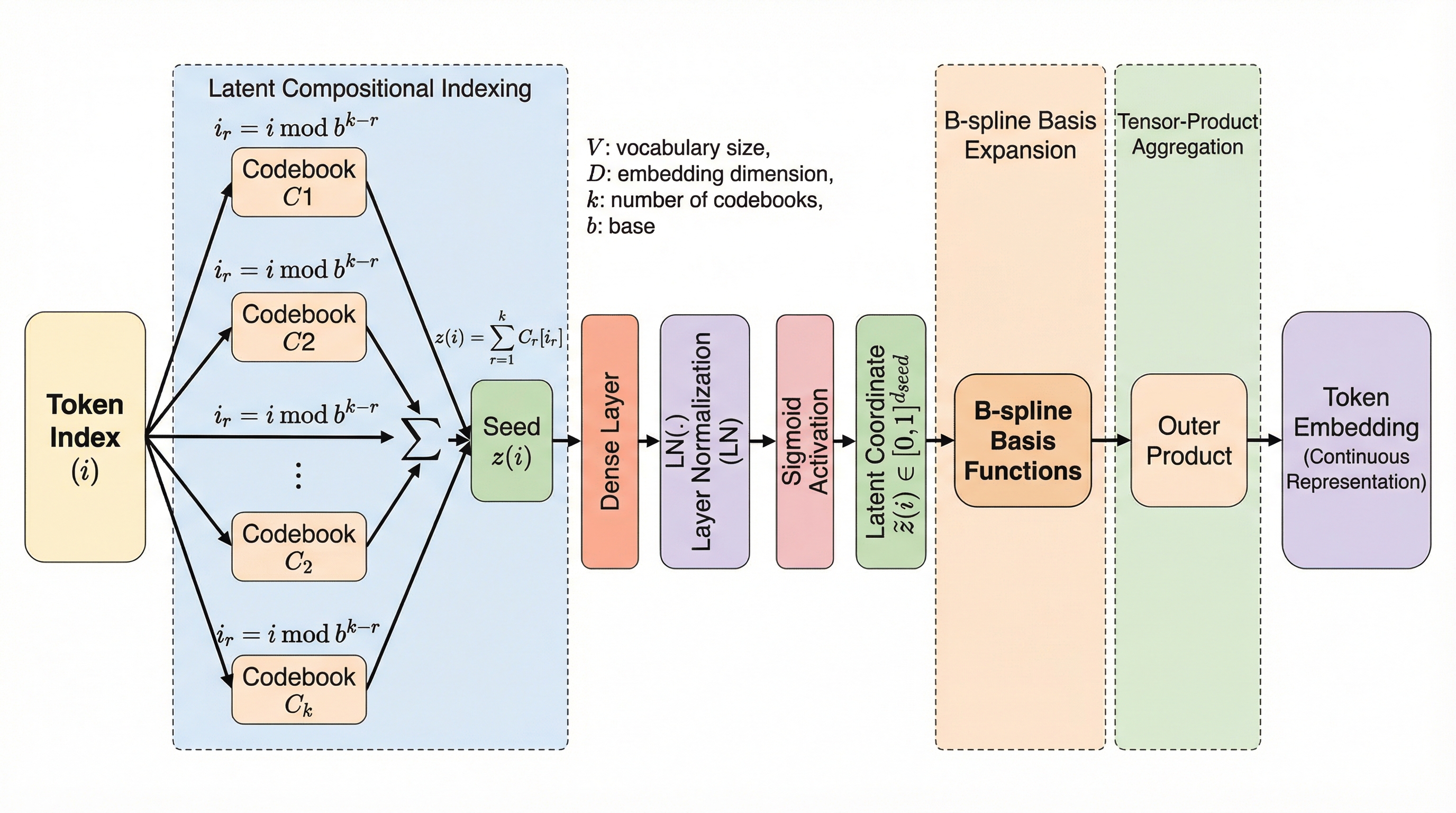
従来の小規模言語モデル(SLM)において、パラメータ予算の多くを占有していた離散的な埋め込み行列(ルックアップテーブル)を、連続的な関数近似を行う「分離可能なニューラルアーキテクチャ(SNA)」を用いた生成器に置き換える新手法「Leviathan」が提案されました。
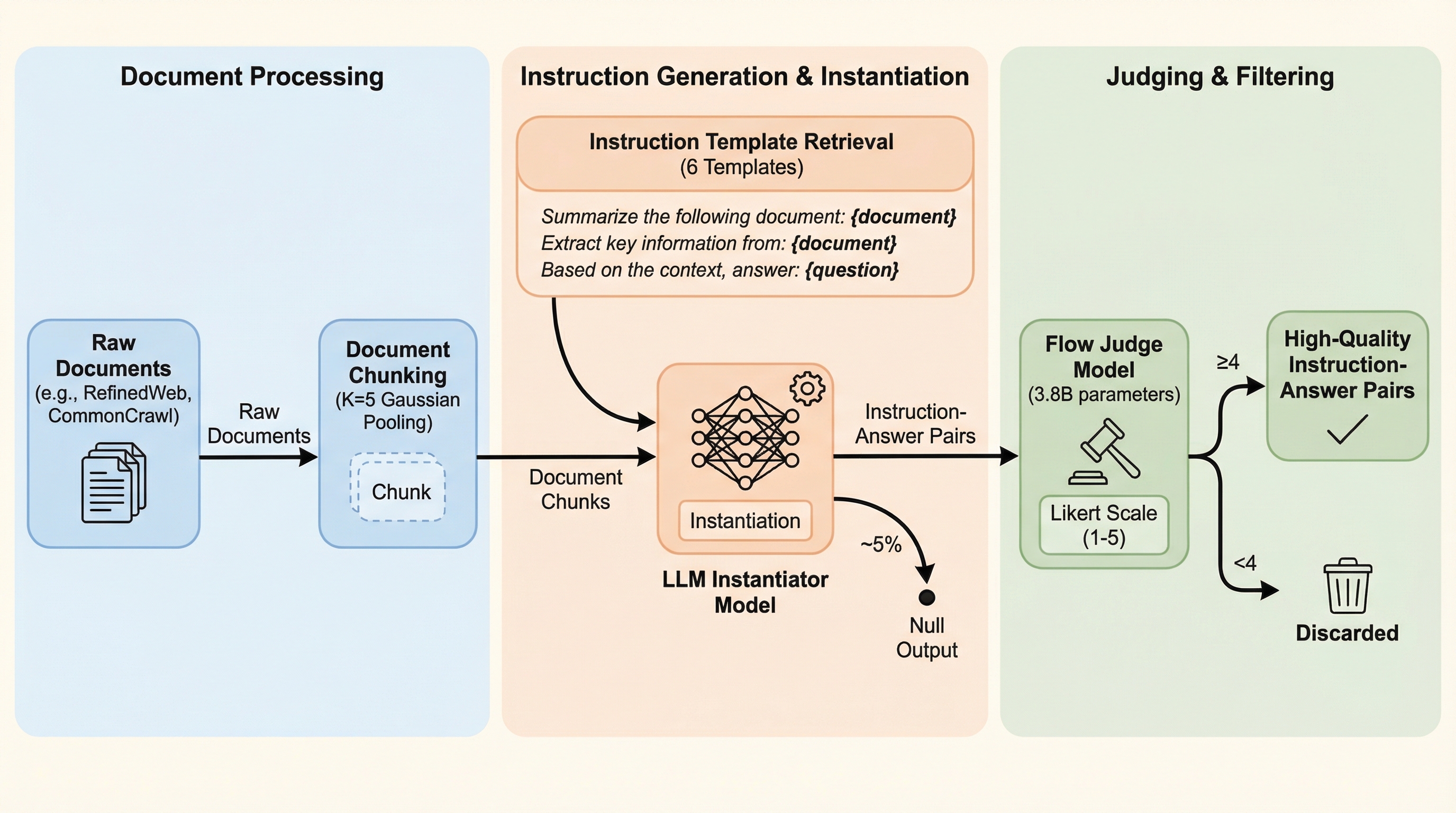
大規模言語モデル(LLM)の事前学習において、従来の非構造化テキストによる次単語予測ではなく、実際のユーザーのクエリに基づいた「指示と回答」のペアを10億件以上の規模で合成し、それを用いてゼロから学習を行う手法「FineInstructions」が提案された。