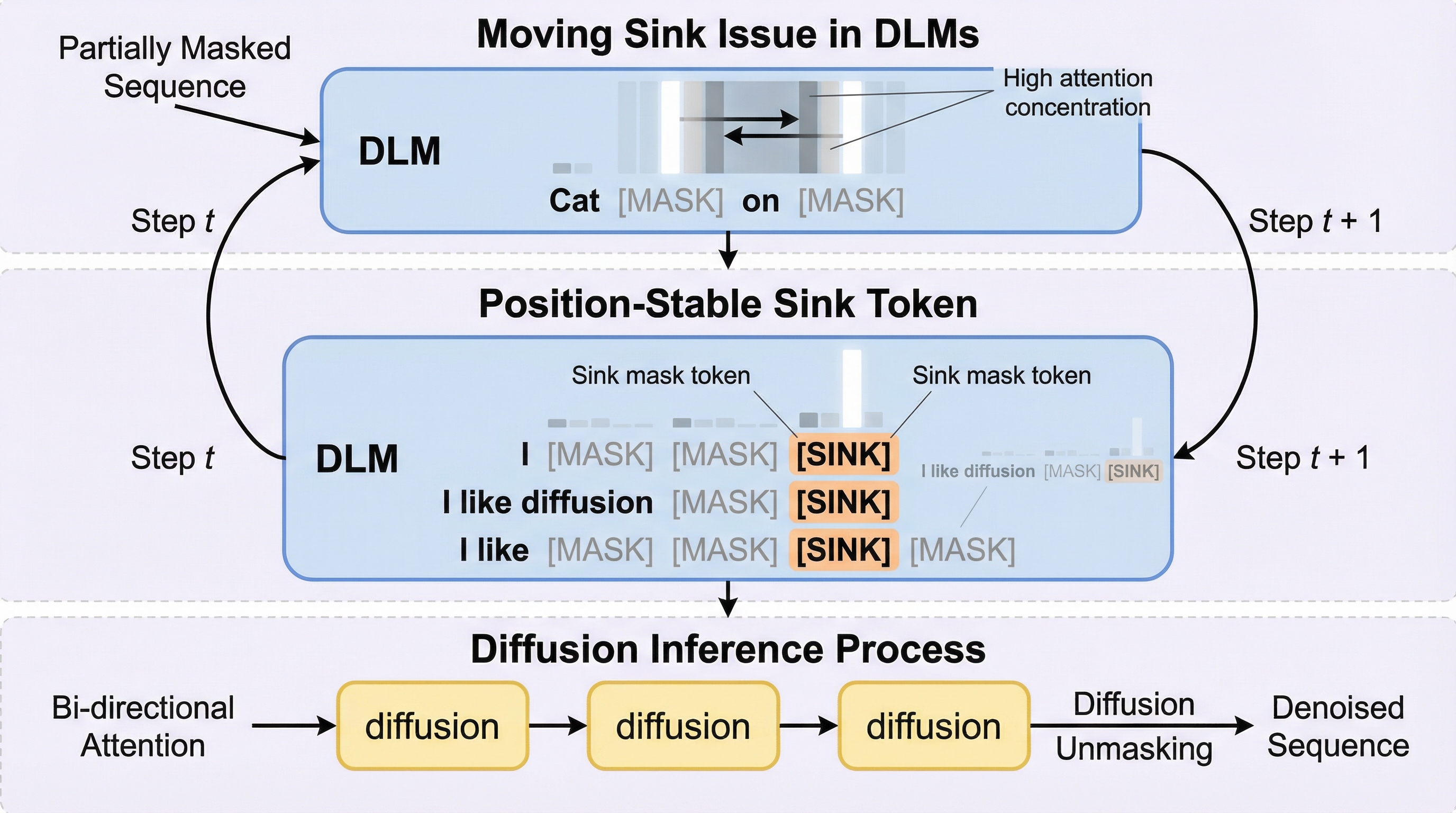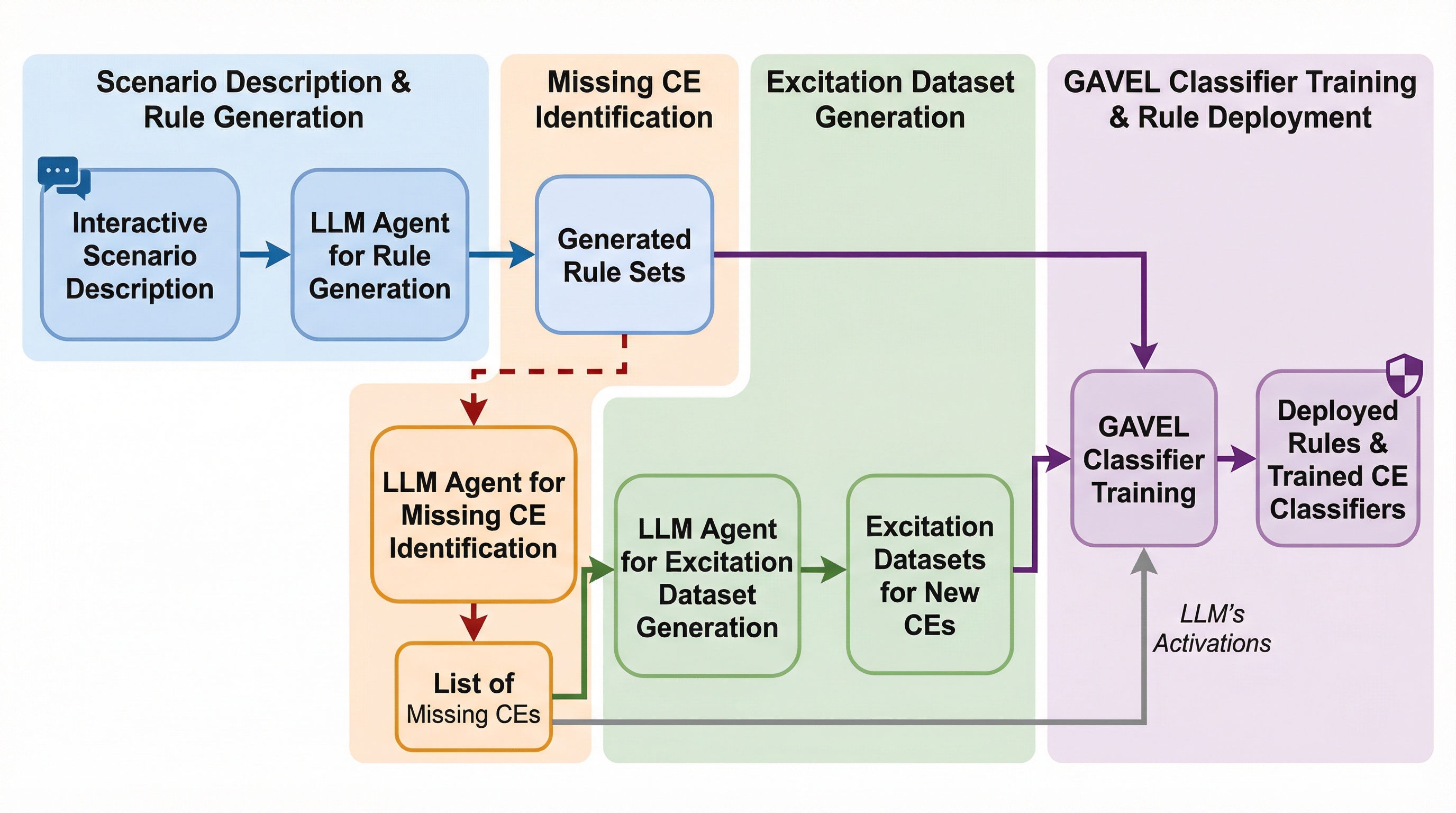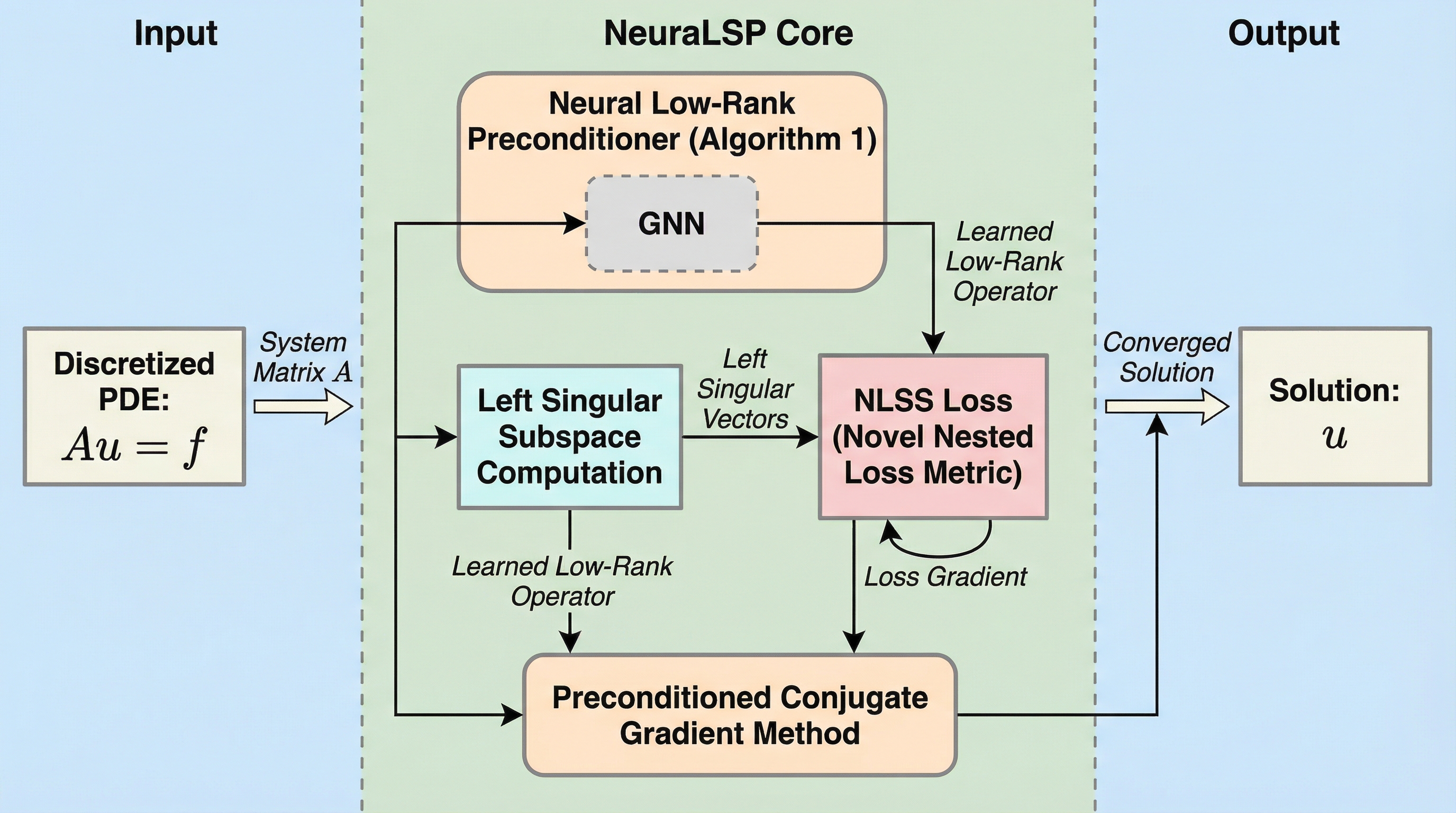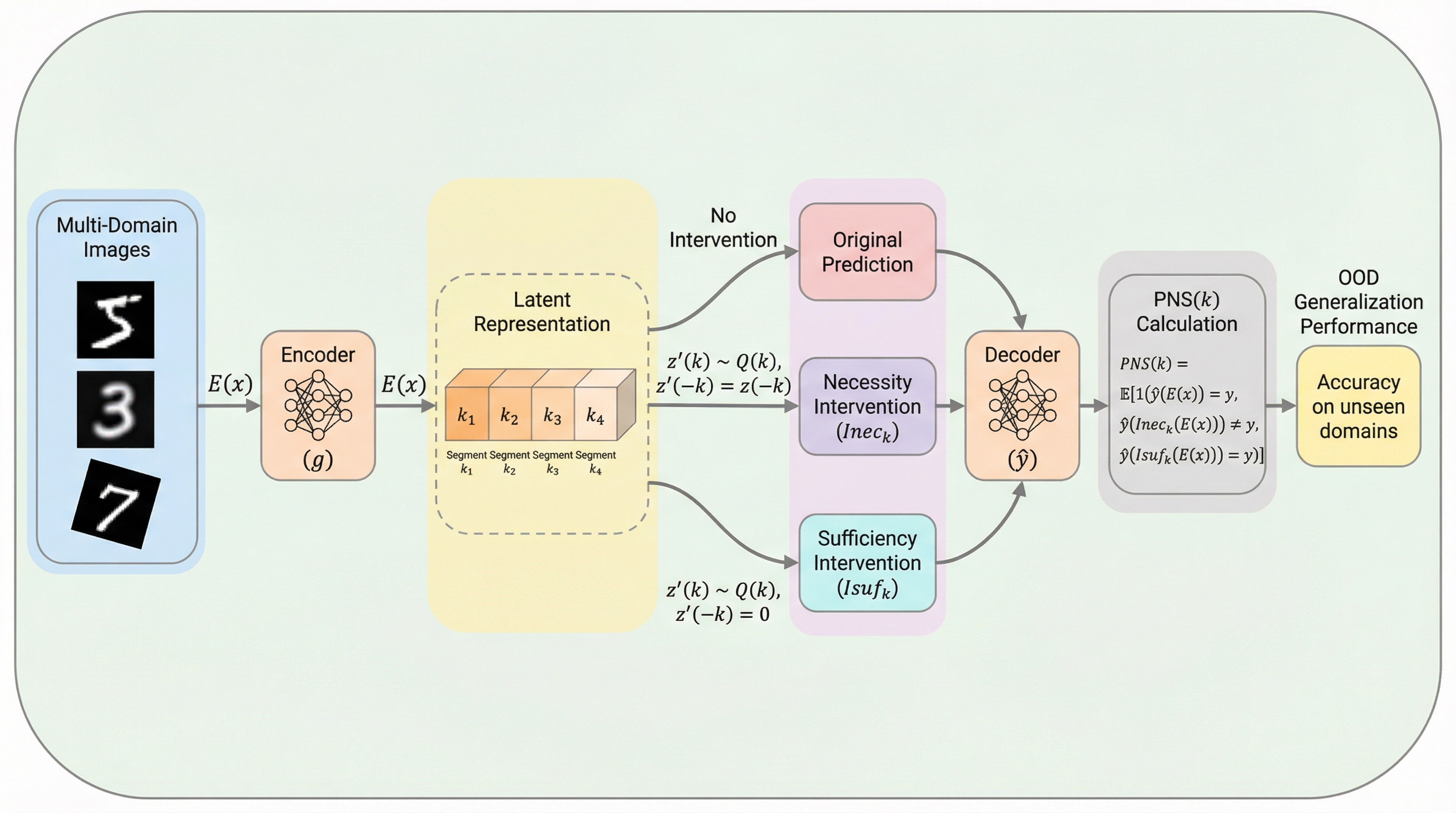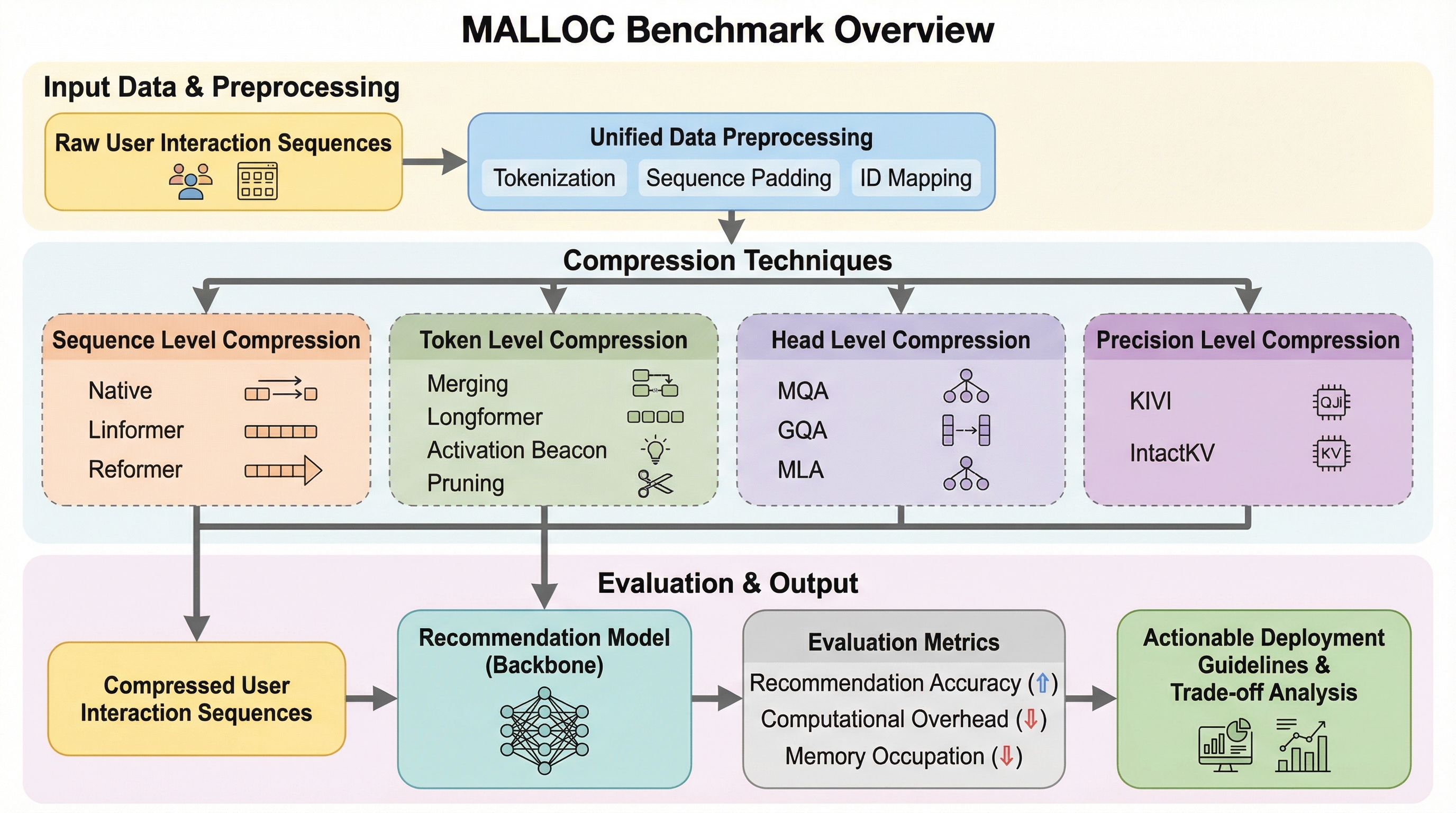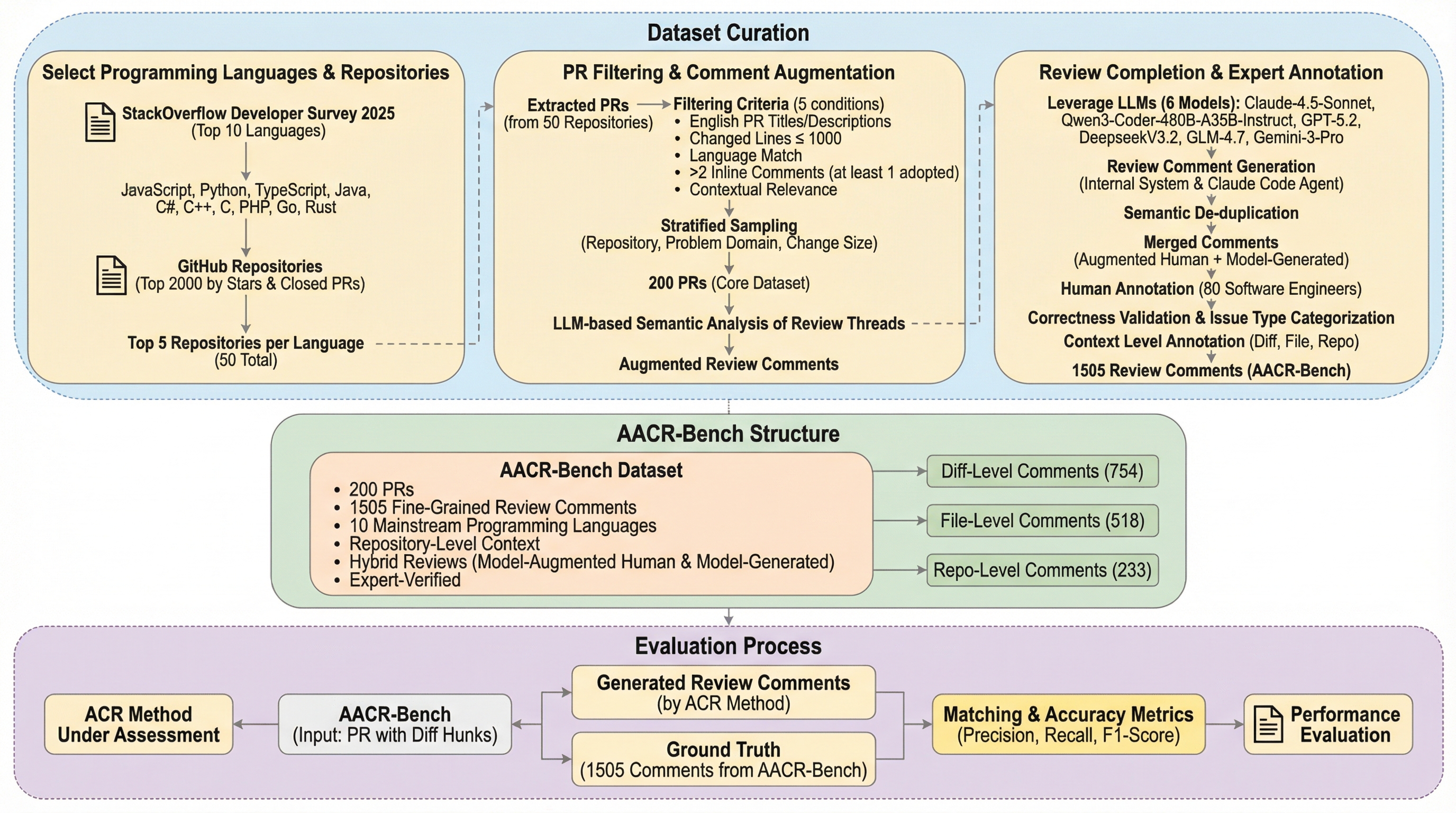
AACR-Bench: 包括的なリポジトリレベルのコンテキストを用いた自動コードレビューの評価
従来の自動コードレビュー(ACR)の評価は、GitHubの生のプルリクエストデータに依存していたため、正解データの網羅性が低く、特定の言語に偏っているという課題がありました。本研究が提案する「AACR-Bench」は、10種類の主要言語と50のリポジトリを対象とし、80名の熟練エンジニアと最新AIモデルを組み合わせた検証パイプラインにより、問題の網羅率を従来比で285%向上させた画期的なベンチマークです。検証の結果、リポジトリレベルの文脈提供やエージェント構成の採用がモデルの性能に与える影響は、使用する言語やモデルの特性によって大きく異なることが明らかになり、今後の自動レビュー技術開発における重要な指針を提示しました。