1トークンで十分:シンクトークンによる拡散言語モデルの改善
拡散言語モデル(DLM)において、注意機構の計算過程で不要な情報を逃がす「シンク(掃き出し口)」となるトークンの位置がステップごとに不規則に変動する「移動シンク現象」が、生成の不安定性や性能低下の主要因であることを特定しました。
TL;DR(結論)
拡散言語モデル(DLM)において、注意機構の計算過程で不要な情報を逃がす「シンク(掃き出し口)」となるトークンの位置がステップごとに不規則に変動する「移動シンク現象」が、生成の不安定性や性能低下の主要因であることを特定しました。 この問題に対し、自分自身にのみ注意を向けつつ他のすべてのトークンからは参照可能であるような「追加のシンクトークン」をシーケンスに1つだけ挿入するという、計算コストをほぼ増加させない極めてシンプルかつ効果的な手法を提案しています。 この静的なシンクトークンを導入することで、モデルの規模や初期化手法(事前学習済みモデルの転用かスクラッチ学習か)にかかわらず推論の安定性が高まり、特に大規模モデルにおいては複雑なゲート機構よりも優れた性能向上が一貫して確認されました。
なぜこの問題か
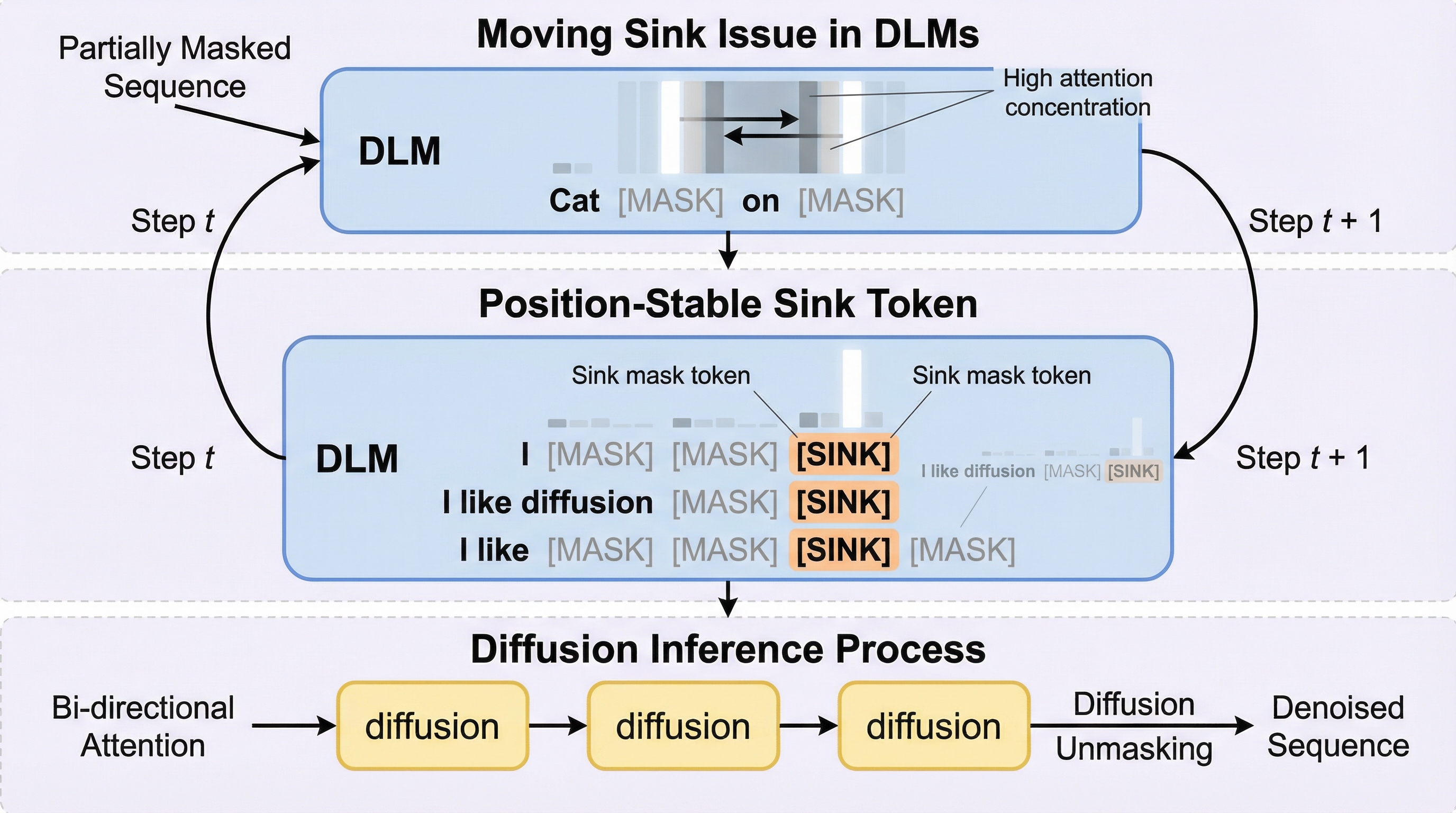
近年、拡散言語モデル(DLM)は、従来の自己回帰型(AR)モデルに代わる次世代のテキスト生成アプローチとして急速に注目を集めています。左から右へと順次トークンを生成するARモデルとは異なり、DLMは双方向の注意機構(Bidirectional Attention)を駆使し、並列的なテキスト生成を可能にするという利点を持っています。しかし、この革新的なアーキテクチャには、特有の不安定性が潜んでいることが明らかになりました。それが本研究で焦点となる「移動シンク現象(moving sink phenomenon)」です。 Transformerベースのモデルでは、ソフトマックス関数の性質上、注意の重みの合計が必ず1になる必要があります。そのため、現在のトークンにとって重要な情報が文脈中に存在しない場合でも、どこかのトークンに注意を割り振らなければなりません。ARモデルでは、文頭のトークン(BOSなど)が固定的な「注意のシンク(attention sink)」として機能し、過剰な注意の重みを吸収することでモデルの挙動を安定させています。これは構造的に固定された「アンカー」として機能します。…
核心:何を提案したのか
この不安定性の問題に対処するために、著者らは「たった1つの追加トークン(One Token)」を導入するだけで十分であるという、驚くほどシンプルで強力な仮説を立て、それを実証しました。具体的には、拡散言語モデルのために特別に設計された、位置が固定された専用の「追加シンクトークン」を提案しています。 この提案の核心は、既存のモデルアーキテクチャを大きく変更したり、複雑な計算処理を追加したりすることなく、入力シーケンスに特殊なトークンを1つ追加し、それに対する注意マスク(Attention Mask)を工夫する点にあります。この追加トークンは、意味的な情報を持たない、いわば「ゴミ箱」のような役割を果たします。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related