MALLOC:大規模シーケンシャル推薦のためのメモリを考慮した長尺系列圧縮のベンチマーク
大規模推薦システムにおいて、ユーザーの長い行動履歴を処理する際の計算コストとメモリ消費の爆発的な増加(メモリ・レイテンシのジレンマ)を解決するため、メモリ効率を重視した長系列圧縮技術の包括的なベンチマークである「MALLOC」が提案されました。
TL;DR(結論)
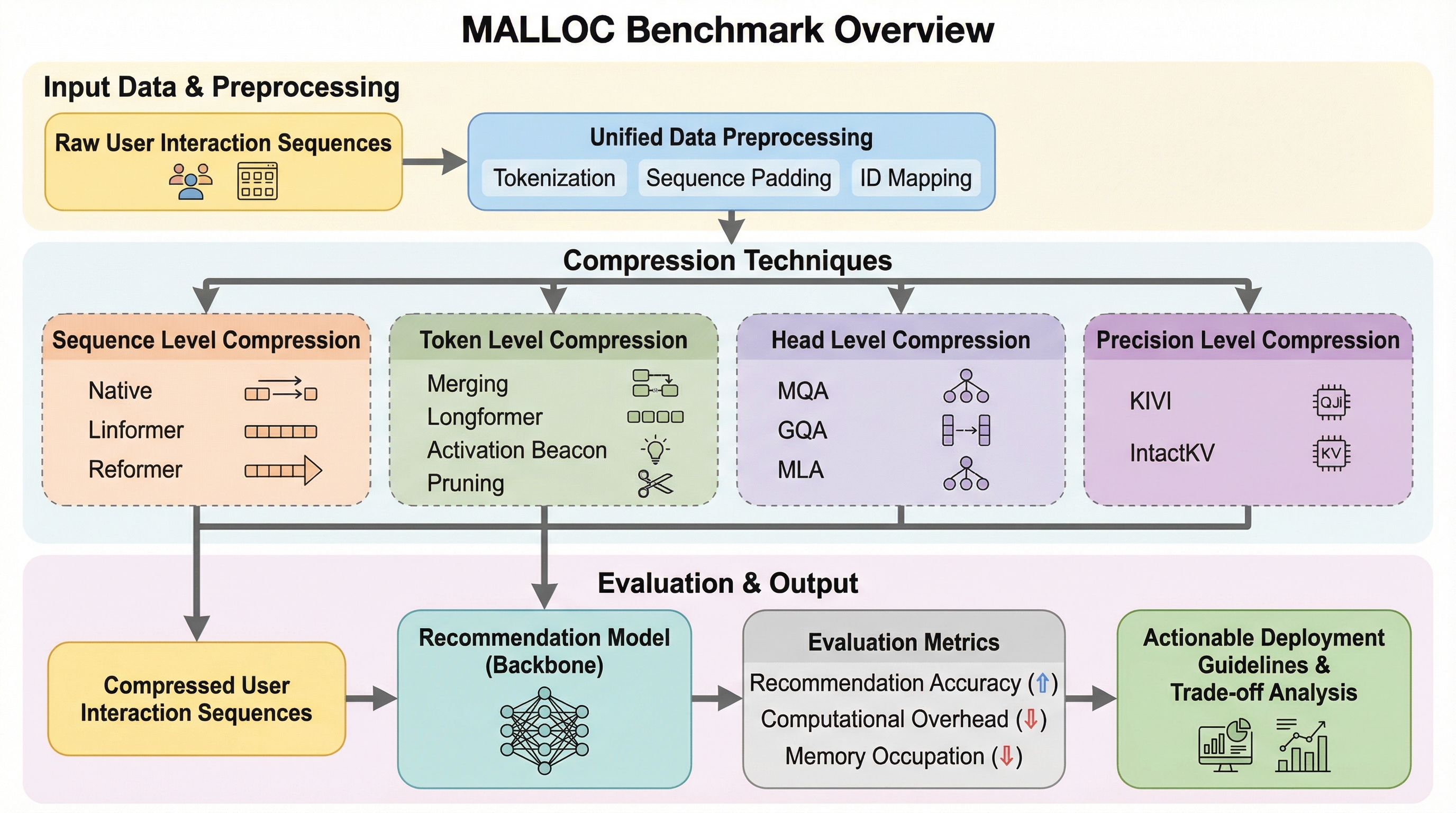
大規模推薦システムにおいて、ユーザーの長い行動履歴を処理する際の計算コストとメモリ消費の爆発的な増加(メモリ・レイテンシのジレンマ)を解決するため、メモリ効率を重視した長系列圧縮技術の包括的なベンチマークである「MALLOC」が提案されました。 このベンチマークでは、既存の圧縮技術をメモリ割り当ての粒度(系列、トークン、ヘッド、精度、アーキテクチャ)に基づいて体系的に分類し、推薦精度、推論効率、実装の複雑さという多角的な指標を用いて、大規模な実データセット上での性能を評価しています。 実験の結果、精度の維持とリソース消費の削減を両立するパレートフロントが構築され、実際の産業用デプロイメントにおいて、どのメモリ管理戦略が最も費用対効果が高く、深いネットワーク構造においても堅牢であるかを示す具体的なガイドラインが提示されました。
なぜこの問題か
現代のオンラインデータとユーザー活動の指数関数的な増加に伴い、推薦システムはEコマースや動画配信などの多様な分野で不可欠な役割を果たしています。従来の推薦システムは、比較的小規模なモデル構造を用いた特徴量エンジニアリングに依存していましたが、近年の「スケーリング則」の知見により、データ量とモデル容量を拡大することで性能が向上するというパラダイムシフトが起きています。この変化により、特徴量中心のアプローチから、パラメータ中心の長系列推薦へと移行が進んでいますが、これには深刻な計算上の課題が伴います。 特に、ユーザーの意図を捉えるために不可欠な長系列の依存関係をモデル化する際、広く使用されているアテンションメカニズムは、系列長の二乗に比例する計算コストを必要とします。例えば、1,000件以上のユーザー行動履歴を考慮することは、推薦の多様性と有効性を高めるために重要ですが、これをそのまま処理しようとすると、推論時の効率が著しく低下します。具体例として、化粧品を購入したユーザーが在庫を使い切るまでの周期的な行動を捉えるには、長期的な履歴の保持が不可欠ですが、これを大規模に展開することは困難です。…
核心:何を提案したのか
本論文では、大規模推薦システムにおけるメモリ効率を考慮した長系列圧縮のための包括的なベンチマークである「MALLOC」を提案しています。これは、私の知る限り、推薦システムの文脈において、生のユーザーインタラクション系列を完全に保持しつつ、高い推論効率を維持することに焦点を当てた、最初期のメモリ認識型圧縮ベンチマークの一つです。MALLOCの核心は、バラバラに存在していた長系列圧縮技術を「メモリ割り当ての粒度」という新しい視点から統合し、体系的な分類を行った点にあります。 MALLOCは、単に既存の手法を集めるだけでなく、これまで推薦システムにおいて評価されてこなかった大規模言語モデル(LLM)向けのメモリ管理戦略も取り入れています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related