AACR-Bench: 包括的なリポジトリレベルのコンテキストを用いた自動コードレビューの評価
従来の自動コードレビュー(ACR)の評価は、GitHubの生のプルリクエストデータに依存していたため、正解データの網羅性が低く、特定の言語に偏っているという課題がありました。本研究が提案する「AACR-Bench」は、10種類の主要言語と50のリポジトリを対象とし、80名の熟練エンジニアと最新AIモデルを組み合わせた検証パイプラインにより、問題の網羅率を従来比で285%向上させた画期的なベンチマークです。検証の結果、リポジトリレベルの文脈提供やエージェント構成の採用がモデルの性能に与える影響は、使用する言語やモデルの特性によって大きく異なることが明らかになり、今後の自動レビュー技術開発における重要な指針を提示しました。
TL;DR(結論)
従来の自動コードレビュー(ACR)の評価は、GitHubの生のプルリクエストデータに依存していたため、正解データの網羅性が低く、特定の言語に偏っているという課題がありました。本研究が提案する「AACR-Bench」は、10種類の主要言語と50のリポジトリを対象とし、80名の熟練エンジニアと最新AIモデルを組み合わせた検証パイプラインにより、問題の網羅率を従来比で285%向上させた画期的なベンチマークです。検証の結果、リポジトリレベルの文脈提供やエージェント構成の採用がモデルの性能に与える影響は、使用する言語やモデルの特性によって大きく異なることが明らかになり、今後の自動レビュー技術開発における重要な指針を提示しました。
なぜこの問題か
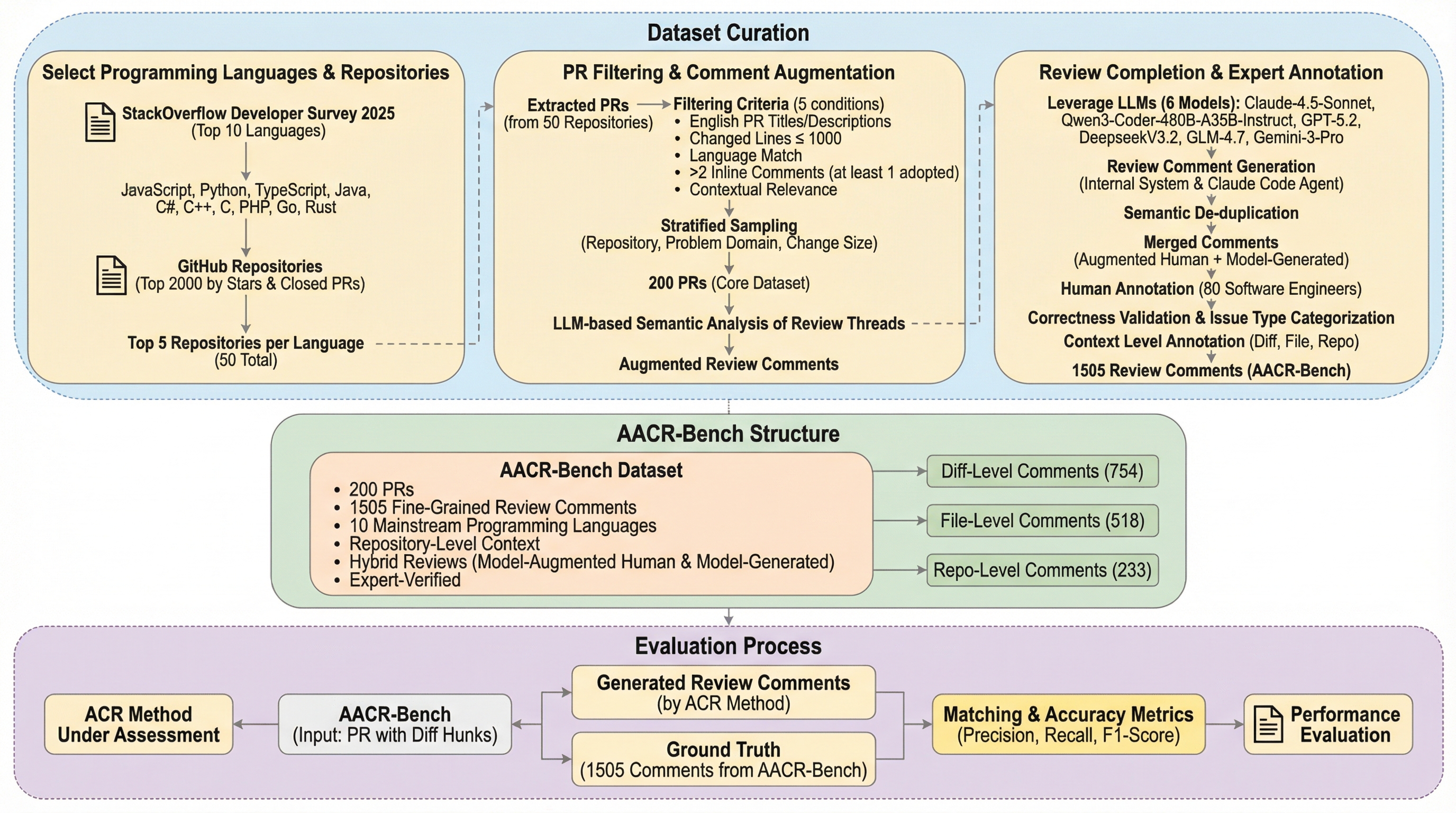
現代のソフトウェア開発において、大規模言語モデル(LLM)を活用した自動コードレビュー(ACR)技術は、開発効率を向上させるための鍵として大きな注目を集めています。しかし、これらの技術を正確に評価するための既存のベンチマークには、主に二つの深刻な限界が存在していました。第一に、正解データ(Ground Truth)の不完全性です。従来のデータセットの多くは、実際のプルリクエスト(PR)から抽出された生のコメントをそのまま正解として利用していますが、これらは人間が見逃した潜在的な欠陥を含んでおらず、モデルが本来指摘すべき問題を十分にカバーできていません。その結果、モデルが優れた指摘を行っても、それが正解データに存在しないために誤報と見なされるなど、真の能力を過小評価するリスクがありました。 第二の課題は、評価対象となる文脈の範囲とプログラミング言語の多様性の欠如です。コードの欠陥の多くは、変更された箇所(diff)だけでなく、ファイル全体やリポジトリ内の他のファイルとの依存関係に起因する「クロスファイル」な性質を持っています。…
核心:何を提案したのか
本研究は、これらの課題を解決するために、リポジトリレベルの文脈をサポートする多言語ACRベンチマーク「AACR-Bench」を提案しました。このベンチマークの最大の特徴は、AIによる支援と人間による専門的な検証を組み合わせた「AI-assisted, Human expert-verified」という高度なアノテーションパイプラインを採用している点にあります。具体的には、GitHub上の50の人気リポジトリから抽出された391件のリアルなレビューコメントに加え、80名の熟練ソフトウェアエンジニア(実務経験2年以上)が、6つの主要なLLM(Claude-4.5-Sonnet、GPT-5.2、Qwen3-Coder-480B、DeepSeek-V3.2、GLM-4.7、Gemini-3-Pro)によって生成された2,145件のコメントを精査しました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related